
Optimization Techniques for GPU Programming
【综述解析·III】Optimization Techniques for GPU Programming(推荐)(上)
本文是一篇 CSUR长文,80 页,≈450文献整理而成。作者来自阿姆斯特丹自由大学,QS209.
本文前四章营养较少,可以从第五章看起,核心是第六章,涉及的干货也很多,是我读过的 GPU 相关的最全的综述。
本文分两部分(正文+附录),这篇只放正文。
摘要: 在过去十年中,图形处理器(GPU)在高性能计算领域中发挥了重要作用,并持续推动物联网、自动驾驶和百亿亿次计算等新兴领域的发展。因此,深入理解如何高效地挖掘这些处理器的性能具有重要意义,而这并非易事。本文综述了过去14年中发表的450篇相关文献,系统梳理了其中提出的各类优化技术。我们从多个视角对这些优化策略进行了分析,结果表明各类优化手段之间存在高度关联性,这也凸显了诸如自动调优等技术的必要性。
一、引言
图形处理器(GPU)在过去数十年间彻底改变了高性能计算(HPC)的格局,并被认为是近年来人工智能(AI)领域取得诸多进展的重要推动因素。GPU 最初作为游戏图形处理的专用处理器而诞生,随后被适配为高性能计算系统中的协处理器,用于处理更为广泛的计算任务。近十年来,GPU 再次开始渗透到诸如物联网设备与自动驾驶汽车等新兴市场。当前,第一代百亿亿次超级计算机(100EFLOPS)正在部署之中,其中大多数采用 GPU 作为主要的计算平台。然而,与以 NVIDIA 占据主导地位的 pre-exascale 时代不同,现阶段的部分系统开始采用来自 Intel 和 AMD 的 GPU,这些硬件伴随着相对新颖且各异的编程模型。因此,在 GPU 硬件、应用场景与编程体系快速多样化的背景下,总结过去十四年在 GPU 优化方面积累的经验变得尤为迫切。
自 2007 年 CUDA 编程模型引入以来,GPU 编程逐渐变得更为普及。紧随其后的 OpenCL 标准于 2008 年底发布,使得在更多种类的处理器上执行 GPU 程序成为可能。尽管随后出现了许多用于简化应用开发的高级语言与领域特定语言,CUDA 与 OpenCL 仍是目前主流的 GPU 编程语言。GPU 编程通常被视为一个专业化领域,尤其在性能优化方面,需要深入理解底层硬件的运行机制,并在众多权衡因素中做出合理取舍。因此,已有大量研究提出了被统称为“优化”的代码变换、编程技术与方法,旨在提升 GPU 应用程序的性能。
本综述首次对该类优化技术进行了系统性的总结与分析,重点关注可由程序员在现有硬件平台上借助 CUDA 和 OpenCL 等编程语言实现的软件层面优化技术。不涵盖编译器中间表示上的变换或底层架构层面的性能优化。本文采用 CUDA 的术语体系进行表述,但所讨论的大多数优化策略同样适用于 OpenCL 及非 NVIDIA 硬件平台。
本综述面向多个研究与实践群体:一方面,GPU 程序员可从中了解多种可应用于实际开发的性能优化方法;另一方面,编程语言与编译器研究者可识别 GPU 编程中的关键挑战,并据此改进语言设计以进一步简化性能优化过程;此外,计算机体系结构研究者与硬件制造商可据此观察体系结构可编程性的演进路径,并探讨其未来的增强方向。
本文首先介绍与本研究相关的已有工作,随后描述我们从450篇文献中提取优化技术并构建数据库以供分析的方法。接着,我们简要介绍 GPU 编程基础,并对各类优化技术进行详细分类与分析。最后,我们从多个视角对优化进行综合性讨论,指出不同优化策略之间具有高度的相互关联性,许多关键因素相互依赖,因此诸如自动调优(auto-tuning)等技术在实现高效利用方面具有重要价值。
二、相关工作(相关综述)
本节回顾了以往关于 GPU 优化技术,或更广义上的并行体系结构优化的研究工作。Bacon 等人综述了面向编译器的高级程序重构技术,并指出这些技术对于手动优化同样具有实际意义。他们将“优化”定义为“优化性变换”的简写(注:optimization→optimizing transformation),认为优化的总体目标是在最大化计算资源利用率的同时,最小化操作次数、内存带宽的使用以及整体内存占用。他们还指出,随着体系结构日益复杂,优化过程也变得愈加困难。
Kowarschik 等人在 Bacon 提出的基于循环的优化基础上,进一步引入了关于缓存与数据局部性的优化。尽管其工作主要面向 CPU,但其中提出的优化策略对于 GPU 编程也具有重要参考价值。2008 年,Ryoo 等人发表了两篇专门面向 GPU 优化的综述文章。这些工作是早期关于 GPU 编程优化的研究之一,发表于 CUDA 编程模型发布后不久,主要关注哪些代码适合在 GPU 上运行,以及如何通过调整实现高性能,强调在性能优化中需合理权衡多个因素,并提出自动调优对于性能提升的重要性。
2012 年,Stratton 等人对多个 GPU 应用与计算核(kernels)进行了调查,提出了一系列优化模式及其所针对的性能问题,并逐一分析了每种模式所要解决的瓶颈。同年,Brodtkorb 等人探讨了基于 GPU 架构特性的优化策略,特别强调了多线程对内存延迟的隐藏能力以及内存层级结构对性能的影响。他们提出一种以性能分析为导向的方法,通过比较三个版本的计算核(原始版本、移除内存访问的版本以及仅包含内存访问的版本),来构造一个在多种性能需求之间取得平衡、可自动调优的高效内核。2008 年与 2012 年的这些研究总结了作者在 GPU 编程中的实践经验,并归纳出一系列普适的优化原则。
与此不同,本文的研究基础是我们所分析的文献中提取出的 GPU 优化方法。此外,还有若干面向特定应用领域的综述也讨论了 GPU 优化策略。例如,Tran 等人分析了图处理领域中 GPU 的使用,重点强调数据布局与负载分布在性能优化中的重要作用;Al-Mouhamed 等人回顾了结构化网格计算中的优化技术与高级编译器,区分了面向体系结构的通用优化(如带宽与局部性优化)与面向具体领域的定制优化(如迭代间同步);Mittal 等人针对深度学习领域,总结了 GPU 上的优化策略,并区分了计算瓶颈与存储瓶颈两大类,分别提出了针对性的优化方案。
尽管本综述聚焦于程序员手动实施的优化方法,仍有大量研究专注于通过改进 GPU 硬件架构以提升整体性能。Khairy 等人对 GPU 架构层面的优化进行了系统综述,其研究不仅为本文所讨论的软件优化提供了背景信息,也为读者深入理解 CPU 与 GPU 之间的体系结构差异提供了有益参考。
三、方法论(可跳过)
本节概述了本文在文献检索、筛选与处理过程中所采用的方法。我们借助文献分析工具 litstudy 在 Scopus 数据库中进行文献查询与组织,从而建立一个涵盖 GPU 优化研究的文献集合。该方法分为多个阶段,旨在尽可能全面地覆盖与 GPU 优化相关的研究成果。
之所以采用如此系统的方法,原因在于我们观察到许多研究在描述类似概念时使用了不同的术语,通过广泛收集文献,有助于我们理解不同作者对相似或重叠概念的命名差异。此外,该方法还使我们能够识别出在不同研究中更为常见的优化技术(详见第4节的数据分析)。我们还特别关注对 AMD GPU 及 OpenCL 编程的文献覆盖,以补充这些在现有综述中相对缺失的内容。
图1展示了我们在附录B中详细介绍的文献筛选流程。在第一阶段,我们基于 GPU 优化相关关键词,在 Scopus 数据库中进行了两次查询,分别于2019年11月29日和2021年5月27日执行,以涵盖最新发表的研究成果。初始检索得到 3,973 篇文献,我们首先根据标题、发表会议/期刊和关键词进行初筛,保留了 1,120 篇。
第二阶段中,我们进一步加入摘要与作者信息作为筛选依据,最终选定 532 篇核心文献,并将 202 篇未入选但包含其他相关信息的文献标记为辅助文献。从这些辅助文献中,我们进一步选取了10篇,第二阶段结束后共获得 542 篇候选文献。
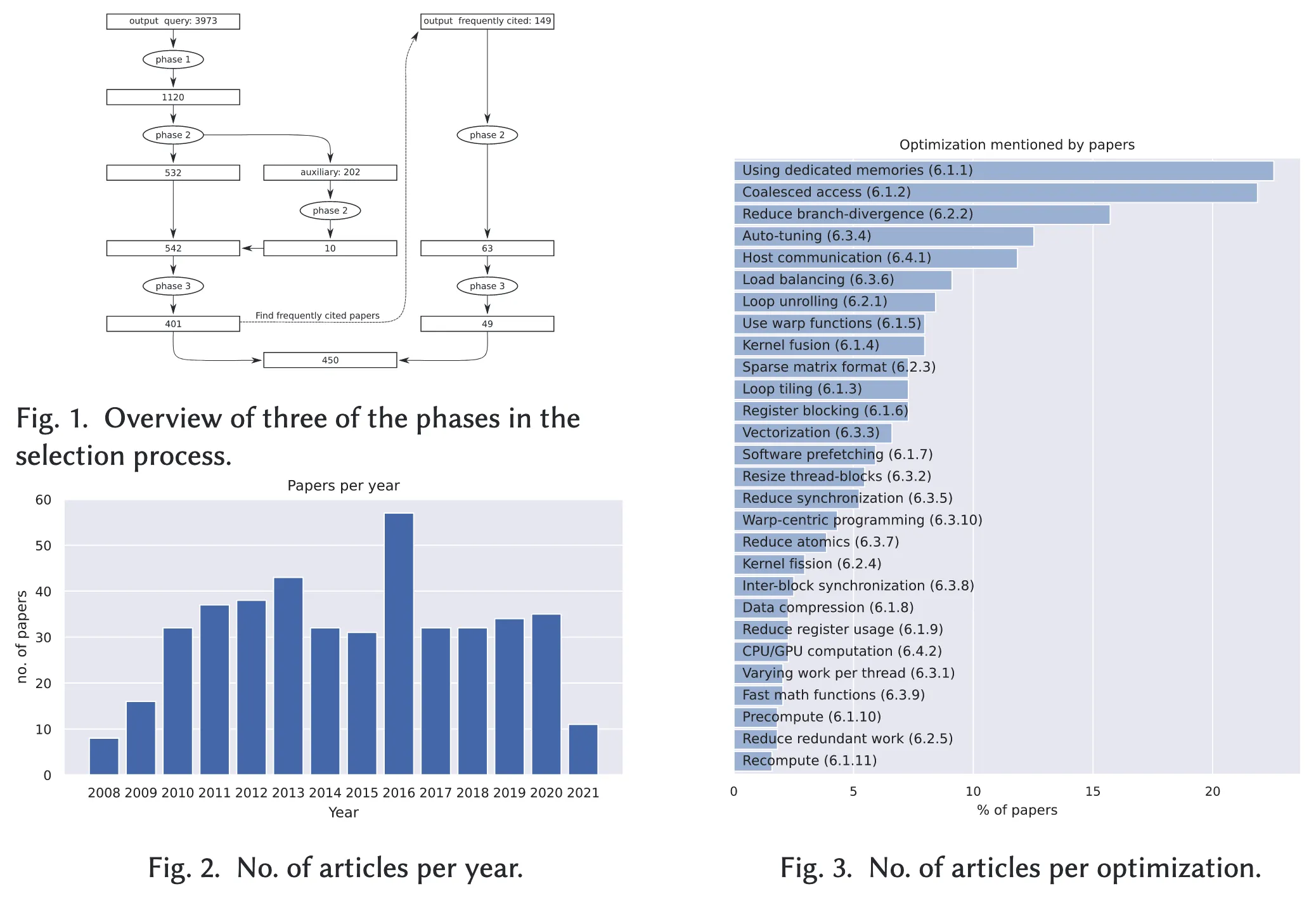
在第三阶段,我们对候选文献进行深入浏览,依据预设标准(详见图1及附录B)筛选出确实包含 GPU 优化内容的文献,最终得到 401 篇。在此基础上,我们分析了这些文献所引用的其他高频文献,识别出 149 篇尽管未在初选集中,但被频繁引用且内容重要的文献,并最终纳入其中的 49 篇。经过第二与第三阶段的筛选,我们共获得 450 篇用于优化分析的文献。
在第四阶段,我们从这 450 篇文献中提取相关信息,包括所采用的优化技术、使用的 GPU 类型以及明确提及的性能瓶颈等,并将这些信息整理入数据库。
第五阶段对上述优化技术进行分析与归纳。针对感兴趣的读者,附录A提供了完整的优化技术参考材料。由于篇幅限制,第6节仅给出该参考材料的简要摘要。第7节则分析了这些优化与性能瓶颈之间的关联。
四、数据分析
本节对基于检索查询所选定的文献集进行分析,补充细节及图表见附录C。图2展示了根据 Scopus 数据库中记录的发表年份统计的年度文献数量。从图中可见,GPU 优化相关研究始于2008年,随后年度发表数量持续增长,并在2013年左右趋于稳定。2016年的文献数量呈现出显著上升,但进一步分析表明该年度的数据未存在异常,仅是该年发表数量高于平均水平。在撰写本文时,2021年的全部文献尚未完全收录。
Scopus 同时提供了文献的发表来源信息,结果显示,GPU 优化研究最常见的会议为 IPDPS、SC 和 PPoPP,最常见的期刊为 Concurrency & Computation: Practice and Experience (CPE)、IEEE Transactions on Parallel and Distributed Systems (TPDS) 和 Journal of Parallel and Distributed Computing (JPDC)。整体来看,GPU 优化的研究成果广泛分布于多个出版平台,表明该研究主题具有高度的跨领域性质,并非局限于某一特定学术社区或会议。
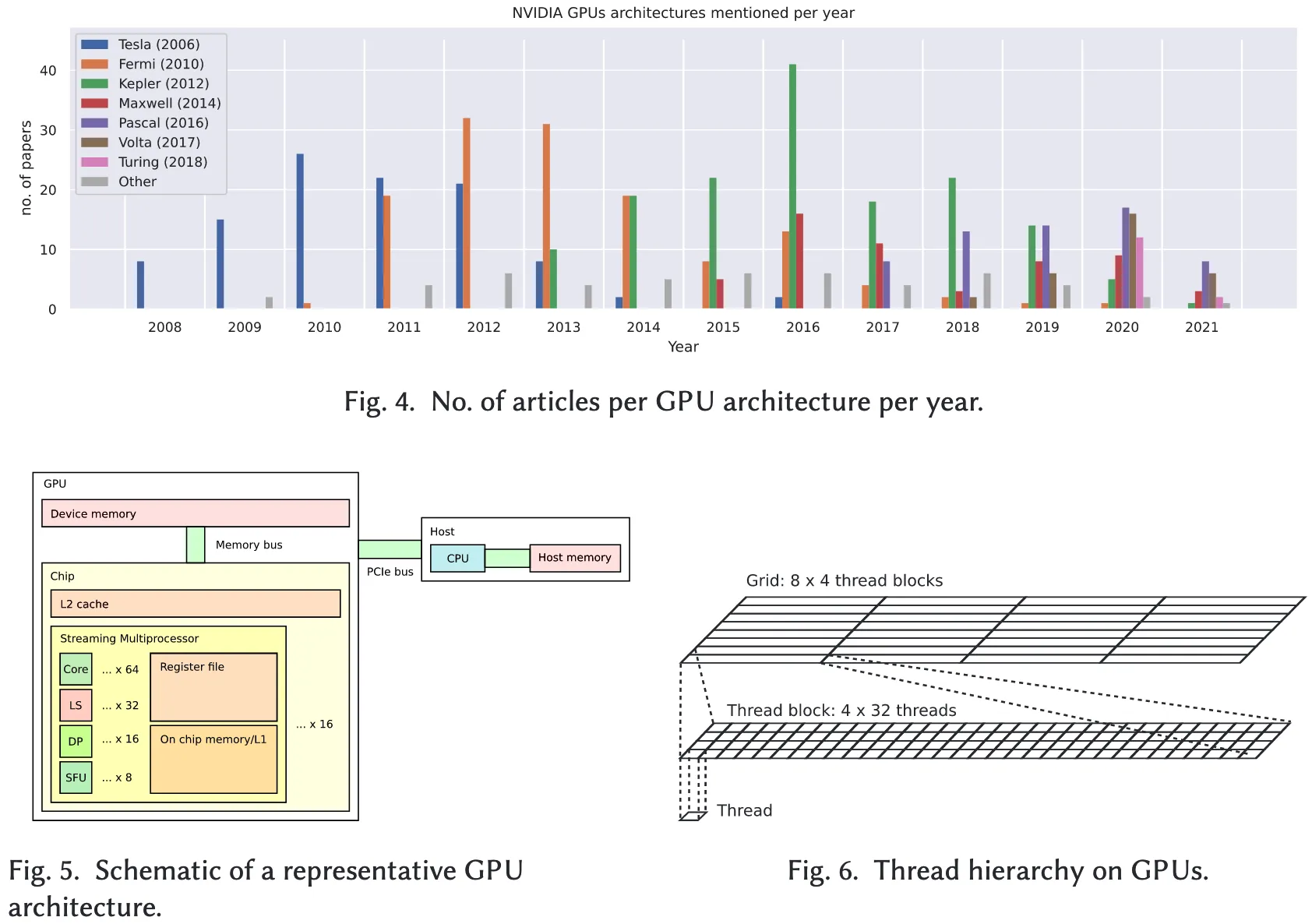
图4统计了不同 GPU 架构在各年度文献中被提及的频率。从图中可以看出,NVIDIA 是最常被引用的 GPU 厂商,其在文献中的出现频率远高于其他厂商;而 AMD 与 Intel 被归类为“其他”类别,在全部文献中出现频率略高于10%。此外,不同架构在各年度的热度呈现明显的兴衰变化,尽管 GPU 架构通常具有较长的生命周期。例如,即使到了2019年,Kepler 架构仍然是文献中最常被提及的 GPU 架构,尽管该架构发布距今已有七年。
第6节将详细讨论我们从文献中归纳出的28类优化技术。图3则展示了各类优化在文献中被提及的比例。从中可以看出,最常见的优化技术包括:访问合并(coalesced access)、使用专用存储器、减少分支发散以及自动调优(autotuning),这些策略在多个研究中被广泛采用。
五、GPU 编程的介绍
5.1 GPU 架构
GPU 架构发展迅速,为避免过度聚焦于某一具体架构,本文采用一种“代表性”GPU 架构进行讨论,该架构虽在现实中并不存在,但足以揭示优化过程中所需关注的核心结构与问题。如图5所示,该代表性架构为一高层次的结构示意图。一般而言,GPU 作为 PCIe 扩展卡集成于主机系统中,与主机端的 CPU 和内存协同工作。GPU 本身包含片上处理器与设备内存,并通过 PCIe 总线与主机通信。
芯片组成:芯片由较大的二级缓存(L2 Cache)与多个流处理多处理器(Streaming Multiprocessors, SMs)组成,在本模型中设有 16 个 SM。
- 每个 SM 包含 64 个用于算术运算(如单精度浮点运算)的核心
- 32 个用于数据加载/存储的单元(Load/Store Units, LS)
- 16 个支持双精度计算的运算单元(Dual Precision Units, DP)
- 以及 8 个用于计算超越函数的特殊功能单元(Special Function Units, SFUs)
此外,SM 还具备片上存储器资源,该资源作为共享内存使用,与一级缓存(L1)共享物理空间。
5.2 编程抽象
下面这些知识每一个细节尽量都要记一下。
在 CUDA 或 OpenCL 编程模型中,核函数(kernel)是从主机端发起、在 GPU 上并行执行的函数。核函数通常针对单个线程编写,在执行时会以一个或多个线程并行启动。GPU 中的线程组织呈层次结构:线程首先被组织成线程块(thread block),多个线程块再组成网格(grid),如图6所示。(这个图画的不好,看下面这个)
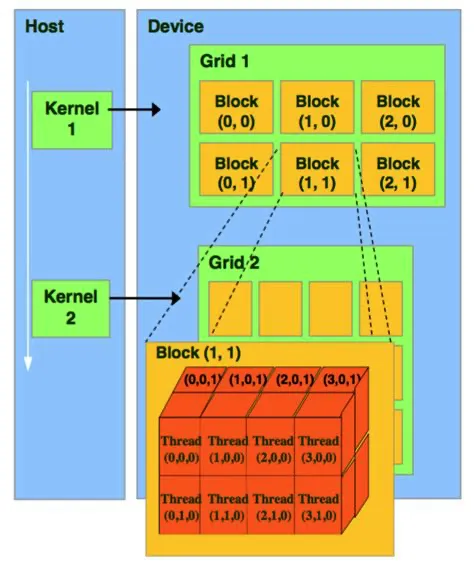
以示例配置为例,一个二维线程块包含 个线程,而整个网格由 个线程块构成。每个线程依据其所在线程块编号、线程块维度以及线程在块内的编号获取唯一标识符,从而在程序中定位对应的数据或任务。
同一线程块内的线程可通过共享内存进行通信:一个线程写入的值可被其他线程读取。然而,由于线程无法主动获知其他线程何时完成写操作,因此需要通过同步屏障(barrier)机制来协调数据访问。在传统 GPU 架构中,不同线程块之间在单次核函数执行过程中无法直接通信(尽管现代架构对此限制已有一定程度的放宽,详见第6.3.10节)。因此,实现跨线程块的同步通常需要通过多次核函数调用实现。
线程块内共享内存,需要同步屏障;线程块外无法通信
注:为什么需要多次核函数才能跨块同步?CUDA 调度器可能并行、乱序调度多个线程块到不同的 SM 上。所以一个线程块不能知道其他线程块是否已经执行或执行完某个操作;CUDA 并没有提供像__syncthreads() 那样能让不同 Block 的线程同步的机制。GPU 是为了吞吐量优化而非强同步设计的。强制线程块等待彼此完成会大幅降低并行性。
kernel1<<<…>>>();
cudaDeviceSynchronize(); // 确保 kernel1 所有线程块都执行完
kernel2<<<…>>>();
图7(a) 展示了一个简单的 CUDA 核函数示例,实现数组 aa 与 bb 的按元素加法并将结果存入数组 cc。每个线程基于其全局线程编号(由线程块编号、块内线程编号及线程块维度计算)处理一个数组元素,实现并行加法操作。图7(b) 展示了主机端代码,用于设定线程块和网格规模并启动 vecadd 核函数。此例中每个线程块包含 1024 个线程,核函数以约 1000 个线程块的规模并行执行。这种并行度在实际 GPU 应用中较为常见。
尽管编程模型中未显式体现,但了解线程的实际调度单位对性能优化有重要意义。在 NVIDIA 架构中,线程块内的线程被划分为 32 个线程一组的 warp,AMD 架构中通常为 64 个线程一组。指令以 warp 为调度单位执行,因此同一 warp 内的所有线程将执行相同的指令流。(锁步执行)

5.3 编程抽象与 GPU 架构的映射关系☆
在 GPU 编程模型中,线程块(thread block)这一编程抽象映射至架构层面的流处理多处理器(Streaming Multiprocessor, SM)。SM 中的各类功能单元(如算术核心)负责执行 warp 级别的指令,而共享内存则位于片上存储器中,并按线程块粒度进行分配。编译器负责确定每个线程所需的私有寄存器数量。一般而言,线程间无法通过寄存器直接通信。
注:线程间无法通过寄存器直接通信的原因是寄存器是线程私有资源、隔离寄存器有利于并行调度、线程通信使用的是共享内存或全局内存。
在 NVIDIA GPU 架构中,提供了 warp-shuffle 函数,使得同一 warp 内的线程可在不依赖共享内存的情况下进行数据交换(详见第6.1.2节)。若线程所需寄存器数量超出寄存器文件的容量,则部分寄存器值将被“溢出”存储至设备内存中,从而导致性能开销增加,尽管这些值通常会被缓存以减轻影响。
GPU 属于面向吞吐量的处理器架构,其调度机制以 warp 为单位进行。每当某一 warp 执行高延迟操作(如访问设备内存)时,调度器可采取以下两种方式继续执行:
- 在该 warp 的指令流中调度下一条独立指令;
- 切换至其他可执行的 warp。
由此,GPU 通过调度其他 warp 来隐藏高延迟操作,这种机制被称为线程级并行性(Thread-Level Parallelism, TLP);而在单个线程指令流中调度独立指令的机制则被称为指令级并行性(Instruction-Level Parallelism, ILP)。需要指出的是,后者常常在厂商提供的编程文档中被忽视。
每个 SM 可同时执行多个线程块,通常为 8 或 16 个。具体可并发线程块数量受以下三个因素限制:
- 每个线程块中的线程数;
- 每个线程所需寄存器数量;
- 每个线程块所分配的共享内存大小。
线程块大小的上限通常为 1,024 个线程;当线程块达到此上限时,SM 往往只能并发执行 1 或 2 个线程块。适当减小线程块规模有助于提升 SM 的并发度。线程块的寄存器需求由单个线程的寄存器数量与线程数共同决定。最后,SM 上的共享内存也需在线程块之间划分;若某一线程块独占全部共享内存资源,则该 SM 在该时刻只能承载一个线程块。
5.4 性能参数的平衡
从上述讨论可以明显看出,许多参数之间存在相互作用,而在各种参数之间实现适当的平衡对于性能而言至关重要。由于我们所讨论的典型GPU拥有16个SM(Streaming Multiprocessor),每个SM都能够处理多个线程块,因此通常需要网格中包含大量线程块。这也表明,从负载均衡的角度出发,SM的配置通常是过度的。
为了保证各 SM 之间的负载均衡,仅靠网格里足够多的线程块就能做到,不一定要 NN 个 SM;但为了整体性能和隐藏各种内部延迟,GPU 厂商往往会在 SM 数量上做出“过度”投入。
通常认为,如果所选择的寄存器数量、共享内存大小和/或线程块大小导致低占用率(occupancy),那么就无法实现高性能。然而,Volkov指出,占用率作为利用率的衡量标准仅反映了线程级并行性(TLP),而指令级并行性(ILP)同样重要。更进一步,Volkov还指出,在某些核函数中,为了实现高性能,反而需要较低的占用率。
实现高性能往往是一种平衡的艺术,其中TLP与ILP在一定程度上构成“连通器”,但其间存在“水桶”结构,使得最终的结果并不总是立竿见影,除非某一水桶溢出。例如,提高ILP通常是有益的,直到达到SM的某个资源限制,如寄存器数量限制,从而减少了可同时激活的线程块数量,进而降低了TLP。
在附录D中,我们进一步介绍了Volkov的性能模型,该模型从TLP和ILP两个方面对利用率进行了定义。
六、优化技术
本节概述了从现有文献中提取的优化技术,并根据四个主题对这些技术进行了组织,分别为:内存访问(第6.1节)、不规则性(第6.2节)、平衡性(第6.3节)以及主机交互(第6.4节)。由于内存访问通常远慢于计算操作,因此“内存访问”是最为关键的优化主题之一。我们将该主题进一步细分为片上(On-Chip)和片外(Off-Chip)两个子主题,两者各自面临不同的挑战与应对策略。
考虑到GPU是一种高度规则的体系结构,另一个重要主题是“不规则性”,该部分讨论了如何高效地将不规则算法映射至GPU架构上。在“平衡性”主题中,我们探讨了若干优化技术,并进一步划分为三个子主题:
- 指令流的平衡——这是影响性能的关键因素,详见第5.4节;
- 与并行性相关的平衡——在粒度控制与负载均衡中尤为重要;
- 与同步相关的平衡——这一方面对提升性能具有重要意义。
最后,在“主机交互”主题中,我们讨论了GPU作为加速器与主机之间的协同机制。
需要指出的是,我们并不将这些主题视为一种严格的分类体系,而更倾向于将其作为组织优化技术的方式。某些技术的归属并非绝对明确。例如,负载均衡被归入“平衡性”主题,但在不规则应用中也常常不可或缺,因此也可将其视为“不规则性”的一部分。我们在此选择将其归入“平衡性”。
希望深入了解各项优化技术的读者可参考附录A,该附录按照相同的主题结构编排,并附有所述技术的目录索引。
6.1 内存访问
在GPU编程中,优化内存访问是一个重要主题,因为GPU由于高度并行性而在计算方面具有极强的能力,而内存访问通常远比计算慢。这种不匹配体现在GPU复杂的内存层级结构中,同时也体现在众多优化技术往往围绕改善内存访问展开。我们将这些技术划分为片上(On-Chip)和片外(Off-Chip)两类,前者主要涉及GPU芯片内部的内存,而后者主要涉及设备内存。
6.1.1 片上 —— 利用专用内存
围绕内存访问的优化是最常见的,因为性能瓶颈往往出现在内存访问问题上。除了两级缓存之外,GPU还提供映射到快速存储器中的专用内存空间。常量内存适用于内核中的只读数据,并且将这些数据广播给多个线程仅需一次内存事务。纹理内存同样是只读的,针对具有二维空间局部性的访问进行了优化,因此在通用计算中得到广泛利用。它还可以用于处理边界值、改善非合并访问、实现自动的整数到浮点转换,或者仅仅因为访问是缓存的。
纹理内存(Texture Memory)是指专门用于存储图形纹理数据的显存(GPU内存)部分。在计算机图形学和游戏开发中,纹理内存是非常关键的一部分,因为它直接影响图像的质量和渲染效率。
Liu等人展示了纹理内存在基因序列比对中通过一次纹理获取提取打包的字符串数据的应用。共享内存驻留在流处理器的片上内存中,同一个线程块内的线程可以通过同步屏障机制共享其中的数据。由于这些同步可能会导致warp停顿,可以通过减少线程块使用的共享内存量,从而在一个流处理器上容纳多个线程块以减轻这一问题。共享内存除用于数据共享外,还可以减少代价高昂的内存操作,支持非合并访问,或降低不规则访问的影响。
当数据具有时间局部性或空间局部性时,共享内存能极为高效,这一特性可以通过分块(blocking) 或内核融合(kernel fusion) 进一步增强。由于共享内存按bank组织,可能出现bank冲突,进而降低性能,因此存在多种缓解手段,如填充、数据重排或线程与数据之间的重映射。Reddy等人利用操作的交换律对数据访问进行重排。Bernstein等人则开发了一种搜索工具,能够将线程与数据对应,从而几乎完全消除bank冲突。
6.1.2 片上 —— 使用 Warp 函数
NVIDIA在Fermi架构(2010年)中引入了warp投票(warp-voting)函数,使得一个warp内的线程可以在不需要显式同步或共享内存的情况下达成一致。从Kepler架构(2012年)开始,NVIDIA进一步扩展了这些warp投票函数,引入了warp shuffle函数。Warp投票函数用于在warp级别上评估谓词,并将评估结果广播给warp中的所有线程。文献中warp shuffle函数最广泛的用途是在线程间共享数据而不依赖共享内存。值得注意的是,Barnat等人将这些函数用于构建一个warp级别的缓存系统。另一个典型的应用场景是实现协同算法,如归约(reduction)和前缀和(prefix-sum)等。
__shfl_down_sync 等函数允许warp内线程通过特殊指令直接访问彼此的寄存器(由硬件直接支持)
6.1.3 片上 —— 寄存器阻塞
寄存器是GPU中最快速的存储资源,因此在存储频繁使用的值以提升性能方面非常有效。由于寄存器在线程之间不可共享,它们更适用于具有时间局部性的数据复用,而不适用于空间局部性,尽管某些场景中可结合warp shuffle进行跨线程值的分发。由于这些限制,寄存器阻塞(register blocking),有时也称为时间阻塞(temporal blocking),与循环展开密切相关。此外,它还与每个线程的工作负载变化有关,因为有时相同的数据会被一个线程重复用于多个计算元素。Hong等人指出,改变线程的工作负载可以实现寄存器阻塞。该优化技术常见于三维模板(3D stencil)计算,通过在Z维上串行化计算并使用寄存器重用该维度上的值,得到了较为深入的研究。研究还指出寄存器在GPU中尤其适合作为累加器使用,因为其存储的值不易在线程间共享。同时也需注意寄存器不可被索引访问,因此必须借助宏展开或模板技术来实现对寄存器数组的控制。
6.1.4 片上 —— 减少寄存器使用
寄存器的使用对线程占用率(occupancy)具有关键影响,许多应用的性能受限于过高的寄存器使用量,这会导致寄存器溢出,即线程局部变量被存储在较慢的片外设备内存中,尽管这些变量通常会被缓存。典型的优化技术包括使用指针运算、最小化临时变量、重写算术操作;将临时变量转移到共享内存、将小数据类型打包进较大的数据类型(例如将4个字节打包为一个整数),以及避免存储可重新计算的值。通过循环展开也可以减少对寄存器的需求,因为这样可去除归纳变量的使用。其他方法包括改变算法、强制编译器限制寄存器的使用,或更激进地,编写自定义的寄存器分配器。
注:循环展开(loop unrolling)通常会增加对寄存器的需求,而不是减少
6.1.5 片上 —— 重新计算
重新计算优化策略通过重新计算先前已计算过的值以避免通信,从而减少内存操作或内存占用。该策略可视为与预计算(precompute)相对的做法,在现代GPU中尤为有效,因为其计算能力远超内存与通信带宽。一个具有代表性的案例是Lefebvre等人将内核融合与重新计算相结合,避免了通过全局内存进行昂贵的同步操作,并因此省去了中间结果的存储。
6.1.6 片外 —— 合并访问(Coalesced Access)
合并访问是应用最广泛的优化技术之一,指的是当一个warp(32个线程)发出的内存访问满足特定的合并规则时,可以通过少于32次的内存事务从设备内存中获取数据。合并规则因GPU架构而异,且随着架构的演进,其约束逐渐放宽。实现合并访问的方法多种多样,其复杂性取决于数据布局、线程组织方式以及共享内存的可用性。
在数据布局允许的情况下,可以通过重排线程、选择合适的线程块大小、块划分(tiling)、采用不同的并行策略,或利用空间填充曲线等复杂索引方法来实现合并访问。另一种策略是将数据以合并方式从全局内存加载至共享内存中,再进行非合并访问;或将数据暂存于共享内存,以合并方式写回全局内存,此方法常与块划分结合使用。此外,还可以对全局内存中的数据布局进行调整,例如,将结构体数组(Array of Structs)转换为结构体内数组(Struct of Arrays)、将行优先数组转换为列优先数组,或采用其他置换方式,如转置与填充等。
一个有趣的案例表明,在多阶段算法中,不同的布局在不同阶段具有更优表现,动态调整数据布局甚至比始终保持一个固定布局更高效。合并访问在存在大量随机访问的应用中较难实现,如稀疏矩阵-向量乘法或图处理等高度不规则应用。其中一种解决方案是缓存代价高昂的随机访问加载操作。已有研究提出多种稀疏矩阵格式以支持或增强合并访问,此外还有专为图处理设计的新格式,其数据布局天然支持合并访问。亦有研究提出面向合并访问设计的哈希表结构,该哈希表采用链式结构,并在链表节点中引入“slab”结构,即包含多个键值对与一个指针的节点,使得操作可以通过warp指令高效执行,实现内存访问的合并。
6.1.7 片外 —— 循环块划分或空间阻塞
文献中“blocking”和“loop tiling”两个术语常被交替使用,均指将数据或计算划分为若干块,逐块处理的优化策略。为区分与时间阻塞(temporal blocking)的差异,此处采用“空间阻塞”一词加以指代。空间阻塞为程序员提供了对数据局部性的控制,从而提升对L1/L2缓存、纹理缓存、寄存器和共享内存中数据复用的效率。阻塞还可能带来其他优势,例如减少warp分歧。
块的维度通常与线程块维度直接相关,但若将两者解耦,程序员可调整每个线程的工作量,这本身也是一种优化方式。自动调优机制常被用于联合选择最优的线程块维度与块划分大小,以实现性能最大化。
6.1.8 片外 —— 内核融合(Kernel Fusion)
内核融合(亦称内核合并或内核统一)类似于循环融合,其定义为“将连续且存在依赖关系的循环合并”。不过,内核与循环存在本质差别,因为内核允许在设备内存层面进行同步操作。当两个内核存在数据依赖并共享中间数据时,若将其分开执行,则需要通过全局内存进行同步与数据传输。而通过融合内核,可将这类代价高昂的操作转化为片上内存操作或直接避免,从而显著减少同步与内存传输的开销。
6.1.9 片外 —— 软件预取(Software Prefetching)
由于GPU存在较高的内存访问延迟,其架构设计允许在遇到长延迟内存操作或其他阻塞时,切换至可运行的warp以保持执行进度。然而,通过软件预取可以对数据的可用性进行更精细的控制。预取(有时被称为“软件流水线”)已被广泛应用于多种稠密线性代数内核中,例如矩阵-向量乘法、矩阵-矩阵乘法以及模板操作,通常与块划分(tiling)技术结合使用,即在当前迭代中预取下一迭代所需的数据。
在某些文献中,这种方法也被称为双缓冲,因为需要两个缓冲区(一个用于当前数据块,一个用于下一数据块),尽管该术语更多用于描述计算与数据传输的重叠处理。一个具有代表性的案例是Bauer等人提出的GPU编程模型,其中不同的warp承担不同功能(称为warp专用化),其中之一即为预取。Wu等人则研究了跨线程块屏障同步相较于多次调用内核的有效性。他们在跨线程块屏障前预取接下来即将使用的数据,而这一机制在独立的内核调用中无法实现。
6.1.10 片外 —— 数据压缩(Compress Data)
由于主机系统的内存资源远较GPU丰富,数据压缩可用于降低GPU上的内存占用,无论是存储空间、数据传输带宽,还是预处理时间。在实际应用中,该优化被广泛用于稀疏矩阵存储,但同样适用于序列比对中的最长公共子序列问题以及正则表达式匹配等任务。
常用的稀疏矩阵压缩格式:压缩行存储(只记录数值,列号,每一行非零元素的起始索引),压缩列存储(同理),坐标格式(数值和数组坐标)…
6.1.11 片外 —— 预计算(Precompute)
预计算的核心思想是在主计算开始前,离线执行部分计算,并在程序运行时反复重用这些已预处理的结果。此优化常被视为在时间与空间之间进行权衡的一种手段,即通过牺牲一定的存储空间来换取执行时间的节省。因此,它可以看作是与第6.1.5节中重新计算(recompute)策略相对的做法。
此外,预计算还可以作为实现其他优化策略的一种方式,用以减少冗余计算。例如,可在主机端完成部分计算并在主机与GPU之间合理分配任务。典型实例包括预先计算可容纳于共享内存中的行数,或在旅行商问题中预先计算城市之间的距离矩阵并将其存储于纹理内存中,以提高访问效率。
6.2 非规则性(Irregularity)
GPU 作为一种高度规则的架构,在设计上更适合处理结构化和规律性强的计算任务。然而,许多实际应用与算法本身具有高度的不规则性。本小节探讨如何高效地将这些不规则算法映射到GPU架构上。
6.2.1 循环展开(Loop Unrolling)
循环展开是一种优化技术,通过显式地重复循环体的内容来减少循环控制相关的指令。展开可以手动实现(直接复制循环体),也可以通过宏、C++模板或编译器指令自动完成。其主要优势包括减少循环控制指令(如分支与地址计算)、提升指令级并行性(ILP),因展开后的代码包含更多独立指令,从而有助于隐藏执行延迟。此外,循环展开还能够激活其他编译器优化,如将数组存入寄存器、消除与循环相关的分支、或指令矢量化。
尽管循环展开通常带来性能提升,过大的展开因子可能反而降低性能。选择合适的展开因子是关键,且应根据具体的内核与硬件设备而定。
6.2.2 降低分支发散(Reduce Branch-Divergence)
分支发散(或称路径发散)是GPU等SIMD或warp级架构中的典型性能瓶颈。在遇到与线程索引相关的条件分支时,不同线程可能需走不同执行路径,这在GPU上意味着所有线程需串行执行每一条路径,非执行路径上的线程仅不写回结果而已,从而导致效率下降。
若分支内部指令足够简单,则可使用谓词化指令替代显式分支,仅使满足条件的线程写回结果。减少分支的策略包括:完全消除分支、用算术替代条件逻辑(即分支重构)、算法展平、使用查找表进行指令流归一化、内核裂变(详见 6.2.4)等。还可通过通知线程已完成的工作、循环展开、延迟循环迭代等方式降低分支发散概率。
此外,还可通过权衡策略降低分支数量,如以执行冗余计算、容忍少量误差或使用串行执行替代复杂分支。亦可通过代码移动(如分支分布)或简化分支条件实现谓词化,从而减轻分支对性能的影响。
线程/数据重映射虽不直接减少分支,但可通过改变并行策略来降低分支发散,例如进行线程分组或对数据排序,使得线程具有相似的控制路径。此外,调整数据布局(如填充或采用稀疏格式)也能有效缓解分支问题。分支行为也常受到算法设计本身的显著影响。
6.2.3 稀疏矩阵格式(Sparse Matrix Format)
GPU 在处理稀疏线性代数计算(特别是稀疏矩阵-向量乘法)方面具有显著优势。用于表示稀疏矩阵的内存格式对性能影响巨大,研究中已提出多种适用于GPU的格式。
ELLPACK(ELL)格式通过对每行非零元素进行填充以实现固定长度,具有高度规则性,适合GPU架构。在此基础上,进一步发展出多个变种格式,如ELL-R、SELL、ELLR-T、AdELL、AdELL+、CoAdEll、SELL-C-σ等。
对于每行非零元素数量高度不均的情况,也提出了多种格式:如适用于对角稀疏矩阵的CRSD、可减少常规CSR发散的ASCR、降低warp负载不均的SIC-CSR、支持外部存储的CEL、利用超级行提升带宽的格式等。还有研究通过自动调优选择最优参数配置。
混合格式将多种格式结合使用,如HYB格式结合COO与ELL格式;某些方法根据启发式为每行选择ELL或CSR;另有方法将矩阵划分为多个子矩阵,并为每个子矩阵选择最合适的格式,通常由性能模型训练而得。
数据压缩技术也可提升内存带宽利用率,但需额外计算开销进行解压。常见策略包括索引压缩、增量编码、位标志压缩等。上述格式多数假设数据是静态的,但也存在用于动态图结构(如图处理)的格式,支持运行时动态添加或删除边。
6.2.4 内核裂变(Kernel Fission)
内核裂变是指将一个复杂内核拆分为多个小内核,或将一次迭代分解为多个子迭代。该策略与内核融合相对,其核心思想是通过构建更简单、结构更规整的内核以提升资源利用率。
内核裂变在以下场景中被广泛应用:提升稀疏或稠密矩阵-向量乘法的规则性、简化复杂内核结构、减少分支发散(详见6.2.2)、以及提升自动调优的效果。通过裂变后的内核更便于进行性能优化和配置选择。
6.2.5 与同步相关的负载均衡 —— 减少冗余计算(Reduce Redundant Work)
该优化策略旨在避免执行那些被认为是冗余的工作,其实现通常依赖于具体算法结构。此策略与“重新计算”(参见6.1.5)相对,是通过避免重复计算而非重复执行。
该优化尤其适用于处理不规则数据结构,如图结构、动态规划问题或线性代数运算。在这些场景中,针对性的算法设计可有效减少不必要的计算与同步开销,从而提升整体性能。
6.3 负载均衡(Balancing)
尽管GPU架构相对简单,但其架构细节之间高度耦合,因此在实现高性能时需精细地平衡资源使用与并行性映射。本节讨论若干优化策略,旨在实现指令流、并行性及同步方面的均衡。我们将这些策略划分为三个子主题:指令流均衡、与并行性相关的均衡,以及与同步相关的均衡。
6.3.1 指令流均衡 —— 向量化(Vectorization)
该优化策略通过使用向量类型替代标量变量,并采用能够同时作用于向量中所有元素的指令进行操作。向量数据类型最常用于内存访问,并可提升合并访问效率。此外,还可用于调整每个线程的工作量、增加单次循环迭代中的工作量、优化稀疏矩阵访问、提高数据存储效率、加速数值计算过程,以及减少分支。
6.3.2 指令流均衡 —— 快速数学函数(Fast Math Functions)
此优化策略使用近似计算的数学函数,以显著快于标准函数的速度完成数学运算。这些函数通常由硬件中的专用功能单元(Special Function Units)实现。程序员可以通过内建函数显式启用该优化,或通过编译器全局设置激活。一个典型应用是用近似函数替代条件判断,从而降低分支发散。此外,现代GPU架构引入了张量核心,这是一种专用于张量运算的特殊功能单元,支持不同精度的浮点运算,主要用于机器学习任务。虽然通常通过cuBLAS或cuDNN等库调用,但也可以通过底层接口直接编程访问。
6.3.3 指令流均衡 —— 以Warp为中心的编程(Warp-Centric Programming)
该策略将warp作为基本的计算单元,围绕warp组织代码结构,强调warp在并行控制与同步减少中的作用。Warp-centric编程的一个重要优势是可有效减少同步开销。实现方式之一是将工作分配从线程或线程块粒度转向warp粒度。该策略常用于负载均衡、隐藏执行延迟,以及嵌套并行任务的实现。另一个扩展应用是warp专用化,即不同的warp执行不同种类的任务。
6.3.4 并行性均衡 —— 每线程工作量调整(Varying Work per Thread)
调整每个线程或线程块的工作量是GPU编程中最重要且通用的优化之一。该策略在文献中被称为矩形块划分(如1×2 tiling)、剥离开采(strip mining)、线程/线程块合并(merge)、线程粗化(coarsening)或块粗化(block coarsening)等。
总体而言,在存在数据重用的场景中,增加每线程的计算任务有助于提升资源利用效率,但同时也会加剧对寄存器与共享内存的需求。最优的工作量分配常依赖于自动调优机制的支持,以实现性能最优化。
6.3.5 并行性均衡 —— 线程块大小调整(Resize Thread Blocks)
GPU编程中,开发者在设置线程块大小与线程块数量方面拥有较大自由度。例如,针对长度为 2202^{20} 的向量加法操作,可以采用不同线程块大小与线程块数量的组合实现。在简单内核中,线程块大小可能对性能影响较小,但在复杂内核中,其影响可能显著。
调整线程块大小会影响寄存器使用量、每个SM上可调度的独立线程块数量、在存在同步障碍时计算单元的利用率,以及每线程块的共享内存消耗——所有这些因素都会影响整体并发度。尽管该优化常与每线程工作量调整策略目的相似,但二者并不必然改变相同的变量;线程块大小的调整并不总会改变每线程的任务量,尽管在某些情况下可以如此配置。线程块大小是GPU性能调优中使用最频繁的参数之一。
6.3.6 并行性相关均衡 —— 自动调优(Auto-tuning)
尽管线程块大小是GPU编程中最易修改的参数之一,但在实际应用中找到其最优配置仍颇具挑战性。自动调优是一种自动探索参数配置空间以寻找最优组合的过程。该技术已广泛应用于多个领域,尤以稀疏矩阵格式、模板操作、稠密矩阵乘法及线性代数最为常见,特别是在Cholesky分解中具有显著效果。
自动调优方法各异,例如根据稀疏结构调整参数、结合建模与基准测试、或基于机器学习技术进行预测。通用调优工具与框架包括 CLTune、PADL、Kernel Tuner、OpenTuner 以及 Kernel Tuning Toolkit,它们提供API以支持内核的运行与调优。除了性能优化之外,性能可移植性亦是自动调优的重要目标,即在不同硬件平台上实现一致的高性能表现。
6.3.7 并行性相关均衡 —— 负载均衡(Load Balancing)
GPU提供多层次的并行结构,在每一层级上均衡负载对性能具有重要影响。最底层的负载不均衡问题虽与warp分支发散相似,但二者本质不同:分支发散指warp中各线程需串行执行不同路径导致工作重复,而负载不均衡则指部分线程无任务执行,从而浪费计算资源。
许多研究致力于同时缓解上述两类问题,特别是在图处理等应用中常见负载不均现象。典型技术包括:使用全局工作列表延迟处理异常点、在线程块和warp内划分任务(如CTA+Warp+Scan)、或采用边分组的负载均衡划分策略。在稀疏矩阵处理领域,也存在专为warp级负载均衡设计的格式。
此外,一些方法从抽象层面概括稀疏格式中的共性,并引入嵌套并行模式(nested parallel patterns)以实现粗粒度任务向细粒度任务的动态划分。线程块内部的负载均衡可通过全局工作列表、共享内存中的任务捐赠机制,或对数据进行排序实现。而线程块之间通常无需负载均衡机制,因为GPU编程模型本身假设线程块数量超过硬件容量,以实现动态调度。
但对于不规则应用,持久线程模型(persistent threads)被广泛采用,其中线程在整个内核执行期间保持活跃并不断窃取任务。例如,在光线追踪应用中,通过将任务分为多个bin,并在任务过载时以轮询方式将其分配给其他多处理器,实现任务的动态迁移。
在这里 bin 是指"任务分组或者任务桶 (task binning)"
此外,GPU与CPU之间的负载均衡也不容忽视。常见做法是使用静态划分策略,将预定比例的任务分配给GPU,其余由CPU处理;亦有研究提出动态划分方案,以实现更精细的资源调度。
6.3.8 与同步相关均衡 —— 减少同步(Reduce Synchronization)
在高度并行的体系结构中,同步操作可能成为性能瓶颈,尤其当线程数量不足以掩盖同步屏障带来的延迟时更为明显。避免同步往往需通过算法级的改造以确保正确性不被破坏。例如,有研究提出一种无需同步的Cooley-Tukey快速傅里叶变换变体。
常用的减少同步策略包括:增加每线程的工作量(参见第6.3.4节)、使用共享内存实现局部同步、以及利用块划分优化数据访问模式。特别地,通过对基于树的归约算法进行完全展开,也可有效消除同步开销。
同步优化的实现方式并不唯一。有研究主张用更细粒度的原语替代同步屏障,而另一些则提出以屏障替代细粒度同步,这体现出对不同应用场景下同步策略的差异性选择。
6.3.9 与同步相关均衡 —— 减少原子操作(Reduce Atomics)
原子操作为并行内存更新提供了无冲突的机制,是许多算法正确性的重要保障。然而,它们通常伴随着高开销的同步代价。为此,可通过多种方式减少原子操作的使用。
一种策略是完全避免原子操作,这通常依赖于特定应用的特点,例如采用特定的数据划分方法、放宽内存一致性模型要求,或接受对数据状态的近似表达。此外,也有研究提出无锁的线程块间同步机制,作为避免原子操作的一种替代方案。
若不能完全规避,则可以减少原子操作的数量,例如在图处理任务中聚合push操作,或移除潜在冲突最大的原子操作实例。标准化手段包括:在共享内存中实现原子操作,或利用shuffle指令替代代价高昂的原子访问。
6.3.10 与同步相关均衡 —— 块间同步(Inter-Block Synchronization)
传统上,线程块间的同步需通过多个内核调用来实现。为支持更高层级的同步,一些研究提出了多种机制,例如在全局屏障前预取数据等策略。
已有若干实现,其中以Xiao等人提出的两种机制最为广泛采用:一种基于原子操作,另一种为无锁实现。随着CUDA 9.0的发布,NVIDIA引入了协作组(cooperative groups) 功能,允许程序员在超越线程块范围内自定义同步线程组,可支持线程网格级别的同步。
这种高级同步机制需依赖Pascal及更新架构提供的硬件支持,为跨线程块的协调执行提供了更强的编程能力。
6.4 主机交互(Host Interaction)
尽管许多优化策略专注于GPU内核本身,但通过在主机与设备之间实现高效交互,同样可以显著提升整体应用性能。这些优化既包括通信机制的改进,也包括在CPU与GPU之间合理划分计算任务。
6.4.1 主机通信(Host Communication)
为提升应用性能,常需优化主机与GPU设备之间通过PCI Express总线进行的数据通信。最有效的做法是尽可能消除通信需求,即尽量在GPU上完成整个算法,或将数据尽量长时间保留在GPU上。此外,也可通过压缩传输数据来减少PCI-e通信带宽开销。
另一种有效方式是利用动态并行性,即允许线程在GPU内部直接启动新的内核,从而将主机控制逻辑迁移至设备端。类似地,也可借助OpenCL中提供的统一内存机制(类似于CUDA的统一内存模型)来简化主机与设备之间的内存管理。
提升通信效率的常见策略包括:使用页锁定内存(pinned memory)来加速主机与设备间的数据拷贝;结合页锁定内存与映射内存(mapped memory)实现数据传输与计算的重叠;使用流(streams)或命令队列构建复杂的通信调度机制(如流水线),以实现高效的数据移动与执行调度。此外,需管理缓冲区的使用,例如采用双缓冲或三缓冲机制,以避免通信瓶颈。
部分研究提出通过流水线方式隐藏线程与数据之间的重映射延迟,该方法亦适用于改善GPU内的线程调度与通信效率。
6.4.2 CPU/GPU 协同计算(CPU/GPU Computation)
该优化策略通过在CPU与GPU之间划分计算任务,使两类处理器均能并行执行有意义的工作,提升整体性能。该方法特别适用于可划分为一组相互独立或半独立任务的应用场景。
若CPU与GPU之间存在任务依赖关系,则优化数据传输过程变得尤为关键。此外,需关注负载均衡问题,以确保资源得到充分利用。相关讨论可参见第6.3.7节。此类协同计算策略对于提升异构系统中的计算效率具有重要意义。
7 优化技术的分析
在上一节中,我们对文献中的优化技术进行了高层次的综述。本节将从多个视角对这些优化策略进行分析,旨在理解它们之间的关联及其在整体优化流程中的作用。此外,我们还将探讨GPU架构的发展如何影响优化策略的演变,并总结每种优化可能带来的性能提升潜力。
7.1 基于应用特性的分析
本节的分析以应用程序本身的特性为出发点。我们讨论若干GPU应用或内核所具备的属性,帮助读者根据具体问题选取合适的优化技术。这些属性可视为多维空间中的坐标轴,尽管它们之间并非完全正交,因此我们将分别进行讨论。
此处正交是指各个属性(如计算密集度、内存访问模式、线程发散性等)不是完全独立的,一个属性的变化可能会影响另一个。
我们首先区分优化对象是整个应用程序还是单个内核。除非某个特定内核被明确识别为性能瓶颈,否则通常更有意义的是优化由多个内核组成的执行流水线。第二个属性是内核是计算密集型还是内存带宽受限型,这一点会直接影响适用的优化策略。与之高度相关但仍有差异的另一个属性是内核是否具备数据重用性,这同样决定了可采用的优化方法。最后,我们区分规则性(regular) 与不规则性(irregular) 内核,这也是优化策略选择中的关键考量因素。
7.1.1 优化整个应用程序还是优化单个内核
通常,一个GPU应用由多个内核构成,仅对其中少数内核进行优化可能对整体性能提升有限。例如,在分子动力学模拟或HEVC视频编码中,多个内核构成流水线式结构,优化策略应放眼整个应用流程。
当优化目标是整个应用程序时,最先需要关注的技术之一便是主机通信优化(参见第6.4.1节)。在许多场景中,GPU内核的执行速度极快,导致应用性能瓶颈转移至主机与设备之间的数据传输。此时,结合使用页锁定内存、流水线通信机制以及双缓冲技术可有效缓解通信延迟。
此外,数据压缩(参见第6.1.10节)同样是重要手段,常用于减少主机与GPU之间的通信量,从而减轻PCIe传输压力。另一关键技术是CPU/GPU协同计算(参见第6.4.2节),通过将任务在CPU与GPU之间合理划分,实现异构计算资源的高效协同。
最后,预计算优化也是面向整体应用的策略之一,通常通过在主机端预先完成部分计算工作,并将结果传递给GPU,以减少运行时计算负担,从而加快整体执行流程。
其他相关的优化技术包括内核融合(第6.1.8节),即将操作相同数据的多个内核融合为一个内核,这通常可以带来显著的性能提升。与内核融合相关的还有线程块间同步(第6.3.10节),它允许那些需要全局同步的内核被融合在一起。如果实现了线程块间同步,则软件预取优化(第6.1.9节)也变得可行,因为全局同步机制使得在同步点之后提前加载数据成为可能。与内核融合相对的是内核分裂(第6.2.4节),它适用于那些结构庞大且难以优化的单体GPU内核,可通过拆分为更小的部分以提升可优化性。其余的优化技术大多作用于内核层面。
7.1.2 计算受限还是内存受限
确定一个内核是计算受限还是内存受限,在很大程度上决定了应采用的优化策略。Roofline模型是一种常见的性能分析工具,它通过定义“操作强度”(即计算操作与内存访问的比值)来判断内核是否为内存受限。
例如,向量加法是一个典型的内存受限内核,因为每次加法操作涉及两次读取和一次写入,其操作强度较低;而快速傅里叶变换(FFT) 则是典型的计算受限内核,因其对每个数据元素都执行大量浮点运算。
通常,计算受限的内核更受青睐,但这类内核的优化空间通常小于内存受限内核。在某些情况下,通过提高计算效率,一个计算受限内核也可能转变为内存受限。
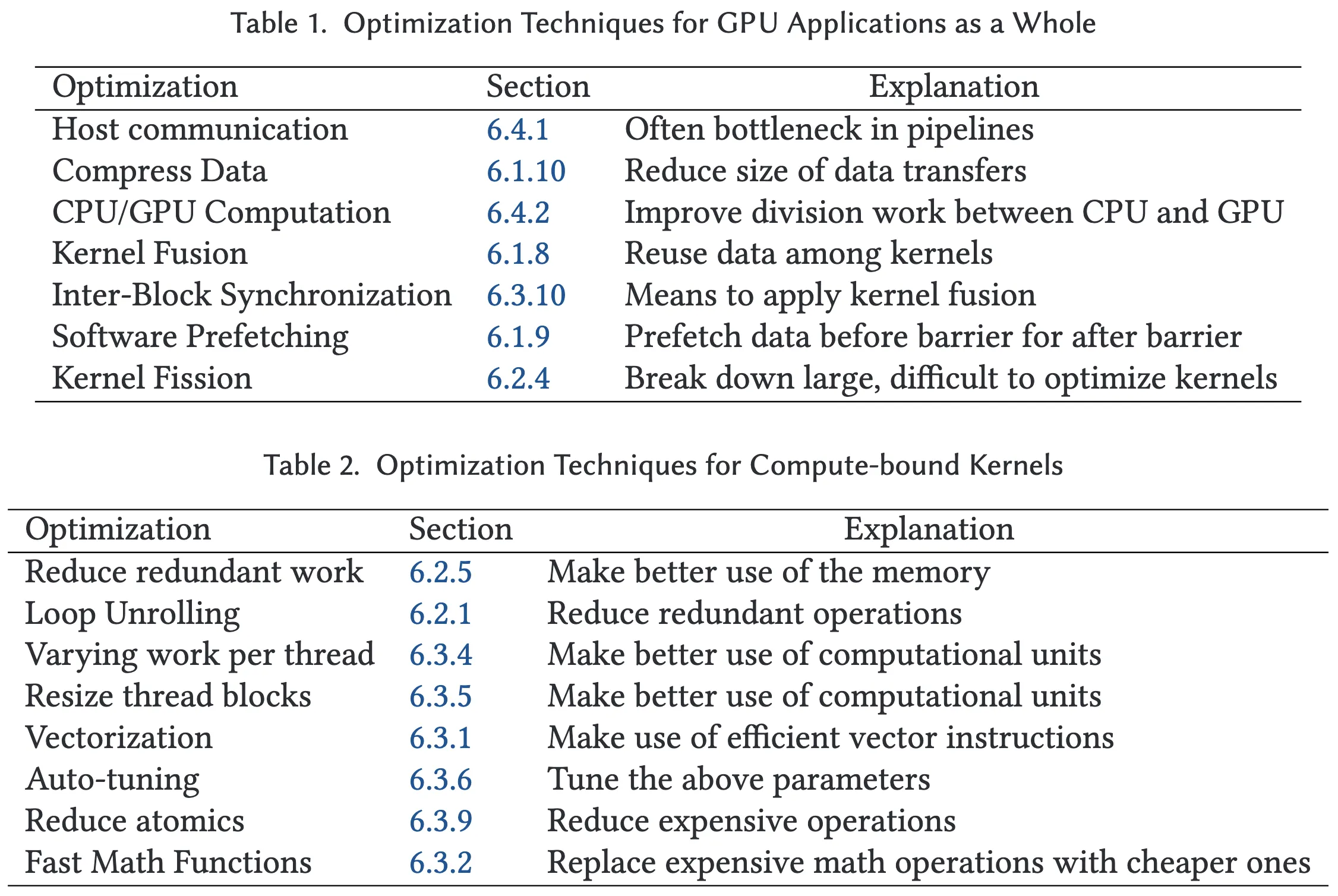
表2列出了适用于计算受限内核的优化技术。其中包括:
- 减少冗余计算:可将已计算的数据存储以供后续重复使用;
- 循环展开(Loop Unrolling):用于优化索引操作;
- 变更线程工作量、调整线程块大小、向量化、自动调优(Auto-tuning):通过这些手段更有效地利用功能单元,实现指令级并行;
- 减少原子操作(Reduce Atomics):可避免开销较大的原子操作,提高计算吞吐量;
- 快速数学函数(Fast Math Functions):以牺牲精度换取更高的计算性能。
对于内存受限内核,则有更多机会利用GPU的内存层次结构,表3列出了适用的优化技术:
- 专用内存(第6.1.1节)和内存访问合并(Coalesced Access,第6.1.6节) 可提高带宽利用率;
- **空间阻塞(Spatial Blocking,第6.1.7节)和寄存器阻塞(Register Blocking,第6.1.3节)**可改善数据局部性,降低内存压力;
- 内核融合及其辅助技术线程块间同步可在多个内核之间重用数据;
- 软件预取允许开发者主动控制何时加载特定数据;
- **Warp函数、Warp中心编程(Warp-centric Programming)**可减少共享内存压力;
- **同步减少(Reduce Synchronization)**可减轻因共享内存屏障导致的瓶颈;
- **数据重计算(Recompute)**策略通过以时间换空间,避免重复存储中间结果;
- 循环展开、线程工作量调整、线程块大小调整、向量化与自动调优则可提升指令级并行性,发起更多内存请求。
7.1.3 数据重用与否
内核是否具有数据重用特性与其是计算受限还是内存受限高度相关。具备数据重用的内核往往适用不同的优化技术(见表4),而不具备数据重用的内核则应采用另一套优化策略(见表5)。
典型的不具备数据重用的内核是向量加法,每个输入元素仅使用一次。相反,矩阵乘法是典型的具备数据重用的内核,其中某些输入元素被多个输出元素复用。
如果矩阵乘法中未有效利用数据重用,内核往往表现为内存受限,因为每个输入元素需要多次加载。而一旦合理重用数据,该内核则可能转变为计算受限,从而受益于计算密集型优化策略。
显然,GPU 的专用存储器可用于存储可重用的数据。空间阻塞和寄存器阻塞能够以更有利于数据重用的方式组织代码结构。内核融合(以及线程块间同步)有助于提升多个内核之间的数据重用机会。借助Warp函数,线程之间可在一个warp内部共享重用数据,因此可能需要采用以Warp为中心的编程范式。此外,线程工作量的变化可改善线程之间的数据重用,线程块大小的调整则用于调节每个线程块可用的共享内存大小。这两者皆可通过**自动调优(auto-tuning)**机制以寻找最优配置。
对于不具有数据重用性的内核,可选的优化手段较少。由于每个数据元素仅被使用一次进行计算,这类内核通常是内存受限的。除非某些数据元素参与多次计算,否则只有在这种计算密集的场景下,才适用计算受限内核的优化策略。否则,以下优化技术更为适用。值得注意的是,许多优化方法与具备数据重用的内核相同,但其适用的理由不同——其核心目标是通过提高并行度来克服带宽瓶颈。例如,通过调整线程块大小和减少寄存器使用,可以提升线程级并行性(TLP),从而允许更多线程块同时运行;循环展开和线程工作量变动可增加独立指令数量,从而增强指令级并行性(ILP);向量化技术有助于提高实际的内存带宽利用率;而自动调优则用于在多种参数配置中寻找最优组合。
7.1.4 规则或不规则
将不规则算法映射到高度规则的GPU架构上具有一定挑战性。不规则的内存访问在GPU上代价尤高,因此相关内核几乎总是内存受限,这使得大多数内存相关优化技术在该情形下仍然适用。除此之外,表6列出了一些特别适用于此类情况的优化方法。一个典型的不规则内核示例是稀疏矩阵-向量乘法(SpMV)。在广泛使用的CSR格式中,该算法需要进行不可预测的随机内存访问,其性能不仅依赖于内核本身,也依赖于输入数据的稀疏性等属性。与此相对的是规则内核,例如稠密矩阵乘法,其内存访问模式可预测,性能基本不受输入数据影响。
数据压缩常用于压缩稀疏矩阵或图算法中指向非零元素的索引信息。不规则内核通常还伴随着分支结构的不规则性,这导致某些warp中大量线程被禁用,从而引起warp分支发散(branch divergence)。减少分支发散一节中提出了多种方法以改善此类低效现象。此外,稀疏数据格式的设计旨在使内核执行模式趋于规则,通常目标是减少分支发散并提升内存访问的合并程度(coalesced access)。内核分裂是一种将复杂内核划分为更简单或更易优化子内核的技术。由于不规则内存访问开销较大,因而在可用数据基础上尽可能多地进行计算,减少冗余计算也成为一种常见策略。
最后,负载不均衡是处理不规则任务时常见的问题。相关章节针对不同层次的并行性提供了多种负载均衡方法。
7.2 基于瓶颈的分析
在本节中,分析视角聚焦于 性能瓶颈。性能瓶颈是指限制内核、应用程序或体系结构性能提升的关键因素。例如,全局内存带宽就是一种常见瓶颈,许多研究指出某些内核的性能受限于全局内存带宽,如果该带宽更高,其性能将显著提升。
我们从所选文献中筛选出明确指出瓶颈的文章,对这些瓶颈进行了分类,并列出被多次提及的代表性问题(被提及次数少于两次的长尾部分则被省略)。这些瓶颈被归纳为四个主题:内存访问、不规则性、负载均衡和主机交互,并在以下小节中关联相应的优化技术。
7.2.1 内存访问
在被分析的文献中,全局内存带宽与访问延迟是最常见的瓶颈。应对这些问题的优化技术包括:
- 使用专用内存(第 6.1.1 节):利用共享内存、常量内存、纹理内存等层次结构提升访问效率。
- 合并内存访问(第 6.1.6 节):提高内存带宽利用率。
- 内核融合(第 6.1.8 节):减少内核间的读写操作。
对于非合并访问和不规则访问也适用上述技术,但后者还涉及更多手段(见第 7.2.2 节)。此外:
- 空间阻塞(第 6.1.7 节)和寄存器阻塞(第 6.1.3 节)有助于最大化已加载数据的计算利用率。
- 向量化(第 6.3.1 节)可利用宽指令改善内存带宽。
- 软件预取(第 6.1.9 节)能够缓解访问延迟。
若瓶颈是由于不规则访问导致的带宽与延迟问题,那么使用稀疏矩阵格式(第 6.2.3 节)将尤为有效。
在共享内存使用受限(如银行冲突、容量、带宽或延迟)时,可采用以下技术:
-
使用专用内存、空间阻塞、Warp 函数(第 6.1.2 节)、寄存器阻塞;
-
软件预取和数据压缩(第 6.1.10 节)缓解容量与带宽瓶颈;
-
预计算(第 6.1.11 节)与重计算(第 6.1.5 节)可降低对共享内存的压力;
-
变更每线程工作量(第 6.3.4 节)与调整线程块大小(第 6.3.5 节)有助于更高效地组织共享内存使用;
-
Warp 中心编程风格(第 6.3.3 节)在改善共享内存问题方面也有帮助。
在**寄存器容量不足或溢出(Spilling)**的场景下,推荐使用: -
专用内存、空间阻塞、寄存器阻塞;
-
减少寄存器使用(第 6.1.4 节);
-
预计算与重计算可以释放长期持有的数据寄存器;
-
循环展开(第 6.2.1 节)是寄存器溢出的主要诱因之一;
-
内核拆分(第 6.2.4 节)有助于简化内核逻辑,改善寄存器使用;
-
变更每线程工作量和线程块大小也可显著影响寄存器需求。
对于缓存瓶颈(冲突、缺失、高延迟、低带宽、容量限制),建议使用:
- 专用内存、空间阻塞、寄存器阻塞;
- 内核融合;
- 对于带宽和容量限制,数据压缩也具有积极作用(第 6.1.10 节)。
7.2.2 不规则性
多数与不规则性相关的瓶颈源于分支发散(branch divergence)以及分支指令开销。负载不均虽然在下节(Balancing)中展开,但其在线程或 warp 层面的表现与分支发散高度相关。
应对这些瓶颈的优化技术包括:
- 减少分支发散(第 6.2.2 节):优化控制流;
- 稀疏格式设计(第 6.2.3 节):将原始不规则数据映射为结构化形式,提高访存规律性;
- 循环展开和内核拆分有助于减少分支或简化分支逻辑;
- Warp 中心编程也可降低分支不一致性;
尽管冗余计算在文献中提及较少,但针对该瓶颈的优化手段包括:
- 减少冗余计算(第 6.2.5 节);
- 预计算(第 6.1.11 节),用于替代重复计算或优化内核逻辑。

7.2.3 平衡性(Balancing)
在该主题中,原子操作争用(atomic contention) 以及更广义的同步开销(synchronization) 是文献中经常被提及的性能瓶颈。如需缓解原子操作争用,可采用的优化技术包括:减少原子操作的使用、使用专用内存以及利用Warp函数。其中,后两者通过共享内存或Warp级的方式完成归约操作,从而降低对原子操作的依赖。此外,以Warp为中心的编程方法对于解决此类问题也具有重要意义。
针对一般性的同步问题,相关的优化技术包括:减少同步操作、线程块间同步机制以及与内核融合技术的协同使用。此外,使用专用内存(特别是结合共享内存中的屏障机制)同样可以在一定程度上缓解同步相关的性能瓶颈。
若瓶颈表现为负载不均衡,则应采用负载均衡相关技术进行优化。在Warp级别,负载不均衡问题往往与分支发散密切相关,因此也可通过以Warp为中心的编程模式加以改善。在更高的层级上,CPU/GPU协同计算技术同样可以有效缓解因任务划分不合理导致的负载不均。
另一个关键的性能瓶颈类别为硬件资源利用率(utilization),即GPU的并行资源(如线程、线程块、特殊功能单元等)的利用程度。需要注意的是,在一个SM(Streaming Multiprocessor)上可同时并发执行的线程块数量受到线程块大小、每线程所需寄存器数量以及每线程块分配的共享内存容量的共同影响。因此,为解决共享内存容量与寄存器文件容量带来的限制,调整每线程工作量与调整线程块大小是尤为关键的优化手段。这些技术在提升并发度和整体性能方面具有显著作用。
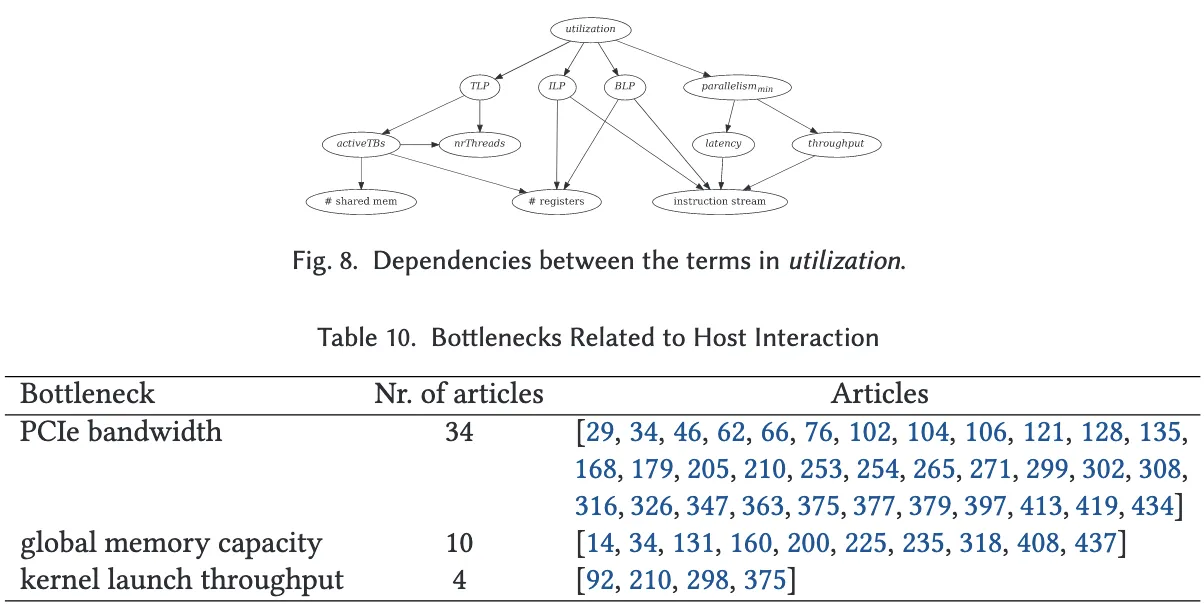
然而,前述技术多侧重于线程级并行性(TLP),而指令级并行性(ILP) 在某些情况下同样重要,甚至是实现高性能的必要条件。ILP 的提升取决于指令之间的独立性,同时也受限于指令延迟以及寄存器上的读后写依赖。文献中有若干研究指出,整数指令吞吐量、特殊功能单元(SFU)的吞吐量及其延迟等均可能成为瓶颈。图 8 总结了影响利用率的多个因素之间的依赖关系,这一模型源自 Volkov 的性能模型(详见附录 D)。
例如,如果需要提升 ILP 或 TLP 以提高利用率,那么所采取的优化措施往往会进一步影响指令流的结构、所需寄存器数量,以及共享内存用量。而后两者对线程块的并发执行数量具有显著影响。换言之,在 GPU 上实现良好的资源利用本质上是一种精细的“平衡艺术”。由于相关因素间存在强耦合关系,关于利用率的分析与优化往往极具挑战性。实践中,一种有效且广泛使用的手段是自动调优(Auto-tuning, 见第 6.3.6 节),用以在这些参数之间找到最优配置,实现更高的资源利用率。
7.2.4 主机交互(Host Interaction)
与主机交互相关的最主要瓶颈是PCIe 总线带宽,如表 10 所示。为缓解该问题,主机通信优化技术(第 6.4.1 节)至关重要。此外,通过在 CPU 与 GPU 之间合理划分计算任务(第 6.4.2 节),亦可在一定程度上减少主机与设备之间的数据交换。
内核融合(Kernel Fusion, 第 6.1.8 节) 可以提高数据重用率,避免重复通过带宽受限的总线传输。而内核裂变(Kernel Fission, 第 6.2.4 节) 则可通过将内核拆分,进而实现内核执行与数据传输的重叠,提高整体效率。另一项重要的技术是数据压缩(Compress Data, 第 6.1.10 节),通过减小传输数据量并利用空闲计算资源进行解压,以缓解 PCIe 带宽的压力。
另一个被提及的重要瓶颈是全局内存容量受限。此类问题可以通过类似的手段加以缓解,如数据压缩、构建流式内核等。此外,**数据重计算(Recompute, 第 6.1.5 节)**也是有效策略之一,通过在设备端重复计算以避免大量中间结果的存储,从而节省内存空间。
最后,内核启动吞吐量也是潜在瓶颈之一。应对此问题的策略包括:通过内核融合减少内核启动次数,或利用每线程工作量调整(第 6.3.4 节) 扩展内核计算任务,从而提高执行效率并减少启动开销。
7.3 GPU 架构演进对优化策略的影响
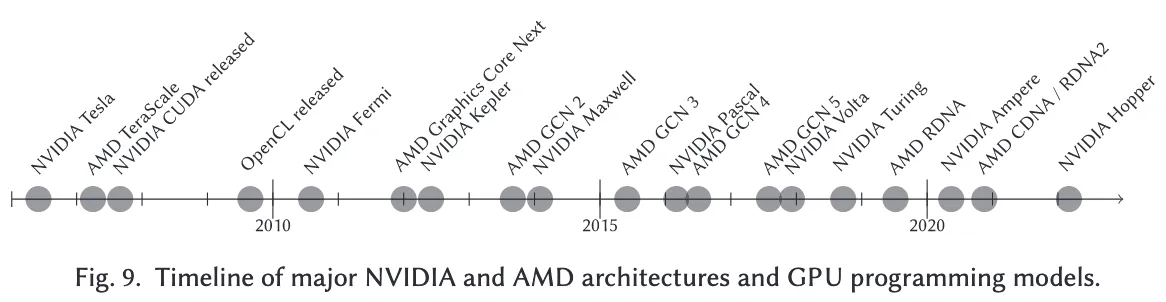
本节简要回顾了GPU主要架构的发展历程,并分析了其对GPU编程优化策略的影响。图9展示了NVIDIA与AMD主要GPU架构及编程模型发布的时间轴。
2006年11月,NVIDIA发布了基于Tesla架构的GeForce GTX 8800 GPU,这是首款采用统一着色器(Unified Shader)的GPU。统一着色器的引入使得着色器处理器可以灵活分配执行顶点、片元和几何着色器等任务,从而为CUDA这一面向通用计算的GPU编程模型的出现奠定了基础。在CUDA问世之前,已有部分研究尝试通过图形API将GPU用于科学计算,但这类方案并不在本综述的讨论范围之内。
2007年,NVIDIA正式推出了CUDA编程模型。同年,时属ATI的AMD也发布了采用TeraScale 1架构的Radeon HD 2000系列GPU,采纳了类似的统一着色器架构。随后,随着Radeon R700和Geforce 9系列的推出,AMD与NVIDIA开始支持OpenCL编程模型。
在GPU编程初期,诸如内存访问合并(coalescing) 与专用存储器的使用(dedicated memories) 等内存优化手段尤为关键,其性能提升可以达到数量级的水平。NVIDIA在Fermi架构中引入了L1/L2缓存层级,显著改善了非合并内存访问的性能表现。由于所有内存事务均以缓存行为单位执行,因此Fermi使得缓存机制在GPU中首次扮演核心角色。尽管专用存储器的使用仍具重要意义,但其性能差异在后续架构中已趋于平缓,甚至在某些场景下难以察觉其显著效益。
2012年,NVIDIA推出了Kepler架构,AMD则推出了GCN(Graphics Core Next)架构。GCN摒弃了TeraScale架构中使用的VLIW,转而采用RISC SIMD架构,并引入了统一虚拟内存的支持。与Fermi不同,Kepler架构默认不对全局内存访问进行L1缓存,这使得其对非规则内存访问(irregular memory access) 更为敏感,并进一步突出了共享内存(shared memory) 在性能优化中的重要性。此外,Kepler默认的共享内存通道宽度为64位,这对32位数据的带宽优化提出了更高要求。
Kepler还引入了warp shuffle指令,并增强了纹理缓存的可编程性,允许其作为只读缓存使用。NVIDIA K20 GPU配备了第二个拷贝引擎,从而提高了通过流(streams)重叠CPU-GPU数据传输的效率。从CUDA 6开始,Kepler及之后的架构均支持统一内存(Unified Memory),也称为托管内存(Managed Memory),以简化CPU与GPU之间的数据管理。
Maxwell架构进一步优化了共享内存子系统,其L1缓存与纹理缓存实现共享,这也解释了在某些应用中,纹理内存访问在Maxwell及更高架构中不再表现出明显优势,而在Kepler上则颇为高效。此外,Maxwell架构中的SM(Streaming Multiprocessor)能够在每个周期调度多条指令,使得特殊功能单元(SFU) 与CUDA核心可以并行执行任务,从而提升计算吞吐能力。
Volta架构引入了张量核心(Tensor Cores),用于执行混合精度矩阵运算(mixed-precision matrix arithmetic)。三年后,AMD在其MI100 GPU中亦集成了矩阵核心单元(MCEs),借鉴了该设计理念。
Volta架构的另一重大变革是引入了独立线程调度(independent thread scheduling) 机制,与Pascal及更早架构采用的SIMT(Single Instruction, Multiple Threads) 模型不同,这一机制显著提升了线程调度的灵活性与效率。然而,Anzt 等人指出,在其稀疏矩阵应用中,Volta 架构所引入的任一子 warp 同步机制并未带来性能提升。与传统的离片 GDDR 显存相比,HBM2(高带宽内存第二代)的引入显著提高了设备的内存带宽。Tang 等人指出,在采用 HBM 的 GPU 上,共享内存对其应用的重要性有所下降。
AMD 的 GCN 5 架构引入了对 HBM2 的支持,并在硬件层面原生支持半精度浮点运算。Reis 等人对 GCN2 与 GCN5 架构在半精度应用下多项优化技术的影响进行了比较,结果表明,**向量化(Vectorization)**仅在支持半精度的硬件上才具有显著意义。
NVIDIA 的 Turing 架构将共享内存、纹理缓存与 L1 缓存统一为单一缓存单元,在不使用专用存储器的负载场景下,有效提升了 L1 缓存的容量与带宽,约为原来的两倍。这进一步削弱了使用专用存储器所带来的性能优势。同时,Turing 架构将共享内存的最大可配置容量限制为 64 KB,而 Volta 架构可超过 96 KB。共享内存容量的减少也限制了某些优化技术(如避免共享内存银行冲突)的有效性。
Yan 等人指出,得益于寄存器银行宽度从早期架构中的 32 位扩展到 64 位,在 Volta 与 Turing 架构中更容易避免寄存器银行冲突。
AMD 的 RDNA 架构首次采用了 warp(wavefront)长度为 32 的设计,旨在减少分支发散,并在控制逻辑、寄存器及缓存资源的粒度方面实现更精细的调度。然而,后续的 CDNA 架构又回归到 64 长度的 wavefront 设计。
NVIDIA 的 Ampere 架构引入了多项关键创新,包括多实例 GPU(MIG)、共享内存的异步操作,以及支持 warp 或 group 中心编程的异步屏障机制,从而进一步减少了同步开销。2022 年初,NVIDIA 宣布 Ampere 的继任架构——Hopper。
7.4 各优化技术的性能潜力定量概览
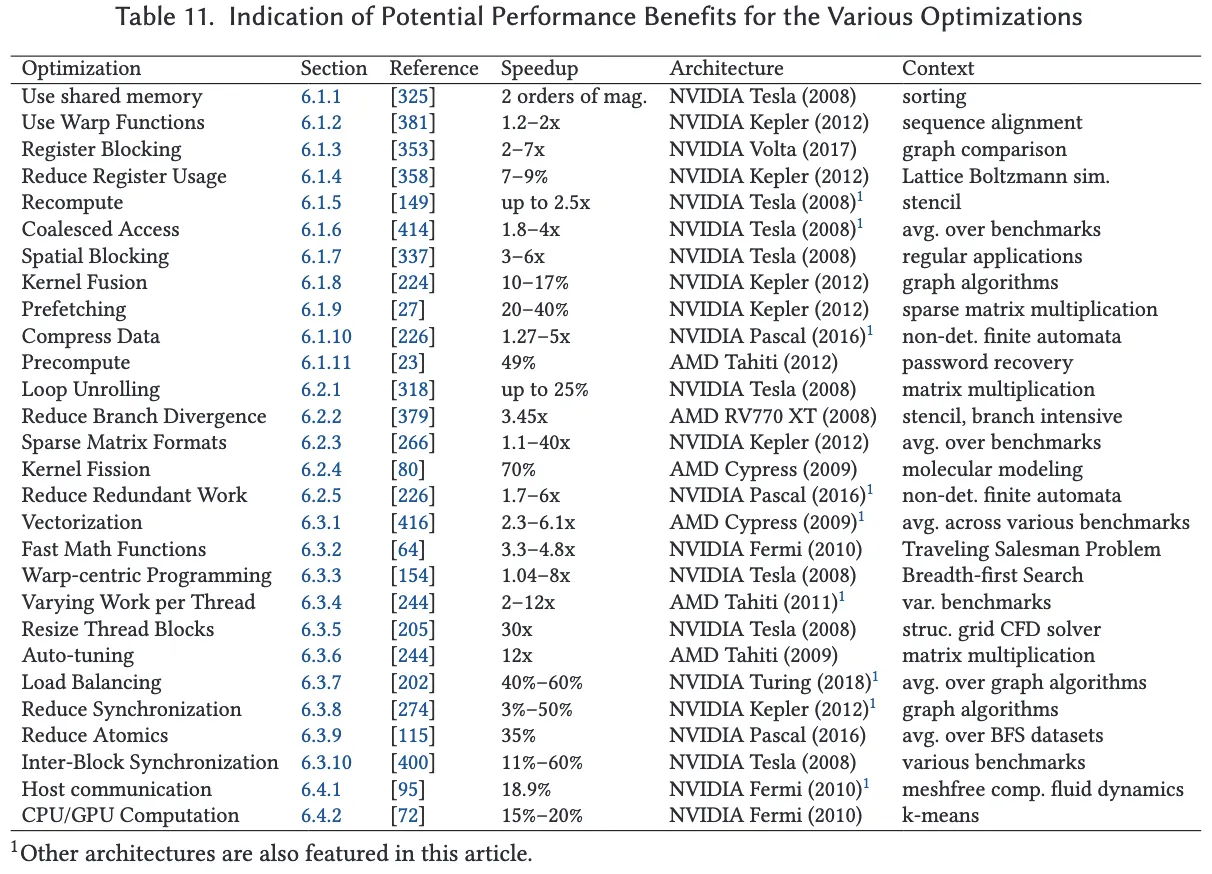
本节旨在对所回顾的各类优化技术提供其性能潜力的定量概览。尽管进行全面的定量分析将具有极高的价值,但在实际操作中,几乎不可能为每一项优化技术提供一个明确的性能潜力评估结果。这是因为性能表现高度依赖于具体上下文,而许多影响因素难以在隔离状态下进行测试,例如 GPU 架构、应用类型、不规则应用中的数据集、以及其它并行应用的优化手段等。
为了对各优化技术的性能潜力提供一定的参考,我们收集了与每项技术相关的代表性文献,这些文献在排除其他优化手段干扰的情况下,报告了各自技术的性能提升。表 11 总结了这些优化技术、所参考的文章、报告的加速比、所使用的硬件架构以及与性能提升解读相关的上下文注释。
需要特别指出的是,由于上下文条件千差万别,因此各项优化的加速比不能直接相互比较。然而,如果结合具体上下文来解读性能数据,该表格可以为理解各优化技术的潜力范围提供一个有益的定量参考。
8 讨论与结论
我们对 450 篇相关文献的系统研究揭示了众多 GPU 优化技术,并将其归纳为四大主题:内存访问、不规则性、并行性平衡以及主机交互。通过详细的归类与阐述,不仅体现了优化技术本身的多样性,也展现出实现性能提升的多种可能路径。
本研究从多个角度对这些优化技术进行了分析:首先从应用特性出发,例如面向计算密集型或内存密集型内核,或是否具有数据重用性;随后再以性能瓶颈为切入点展开分析。研究结果表明,针对特定的应用特性或性能瓶颈,往往存在多种适用的优化技术。换言之,这些优化手段及其作用效果之间具有高度的关联性与相互依赖性。
这一点再次得到了 Volkov 提出的简洁而极具洞察力的 GPU 利用率性能模型的印证。该模型明确揭示了实现高资源利用率所涉及的各类因素之间的相互制约关系,从而很好地解释并验证了 GPU 优化实践中对**自动调优(auto-tuning)**技术的广泛应用。
本研究回顾了过去 14 年间 GPU 性能优化的进展,旨在为以下群体提供有价值的参考:GPU 开发者可据此了解已被广泛应用的优化方法;编译器与编程语言研究者可洞悉开发者在性能调优中所面临的挑战;体系结构研究者及硬件制造商则可理解编程实践如何推动硬件潜能的释放。
我们的数据分析表明,GPU 优化仍具有持续的研究与应用价值。在 GPU 硬件、应用场景以及编程系统快速演进与多样化的背景下,尤其是在物联网、自动驾驶与百亿亿次(Exascale)计算等新兴领域不断发展的今天,深入理解和掌握这些优化技术变得愈发重要。
正文完