CINM (Cinnamon): A Compilation Infrastructure for Heterogeneous Compute In-Memory and Compute Near-Memory Paradigms
【存算一体编译·I】CINM (Cinnamon): A Compilation Infrastructure for Heterogeneous Compute In-Memory and Compute Near-Memory Paradigms
本文来源于 ASPLOS2024,德国德累斯顿大学发表的存算一体编译论文。(QS 173)
摘要:数据密集型应用的兴起暴露了传统以处理器为中心的冯·诺依曼架构在满足片外内存带宽需求方面的局限性。因此,近来计算机体系结构领域提出了计算-内存融合(compute-in-memory, CIM) 和近内存计算(compute-near-memory, CNM) 等非冯·诺依曼范式,在性能和能耗方面均实现了数量级的提升。尽管过去几年中取得了显著的技术突破,这些系统的可编程性依然是一大挑战——其编程模型过于低级,且高度依赖特定系统实现。鉴于未来此类架构预计将呈现高度异构的特征,开发新型编译器抽象和框架势在必行。为此,我们提出了 CINM(Cinnamon),这是首个端到端的编译流程,它通过分层抽象对不同的 CIM 与 CNM 设备进行统一建模,并支持与设备无关与设备感知的多级优化。Cinnamon 在逐层下沉输入程序的过程中,于每个下沉阶段执行针对性优化。为验证其效能,我们在真实的 CNM 系统(UPMEM)和基于忆阻器的 CIM 加速器上进行了多项基准测试。实验结果表明,Cinnamon 在支持多种硬件目标的前提下,所生成的代码性能可与乃至优于当前最先进的实现。
之前仅仅涉猎传统编译,这是阅读的第一篇存算一体论文,所以会做详细的笔记~
引言
应用领域如社交与流媒体、万物互联、通信与服务、以及虚拟助手技术(如 Alexa 和 Siri)正在以惊人的速度生成数据,日数据量已达到百万亿字节量级。这种惊人的数据规模大多为原始数据,亟需进行处理与分析。在传统的以处理器为中心的冯·诺依曼计算范式中,由于数据需在中央处理器和存储器之间通过带宽受限的内存通道移动,这些应用迅速面临性能瓶颈和能效限制。在移动设备上,单是数据传输就消耗了系统总能量的62%。为克服数据移动以及存储子系统相关的其他挑战,计算架构正朝向非冯·诺依曼系统模型发展,如近存计算(Computing Near Memory, CNM)与存内计算(Computing In Memory, CIM)。其核心思想是在数据所在位置附近进行计算。
在近存计算中,专用的CMOS逻辑电路被集成进存储芯片中,以缓解数据移动问题。从概念上讲,这种逻辑与存储器件的紧密耦合可应用于存储层级结构中的任意层级,并可结合多种内存技术实现。在动态随机存取存储器(DRAM)中,已有平面和堆叠结构被用于构建CNM系统,如Micron的混合内存立方体、AMD与SK海力士的高带宽内存,以及三星的宽IO存储器。尽管CNM显著减少了CPU总线上的数据移动,它仍然需要在存储器与计算单元之间传输数据。
相较之下,存内计算模型则通过利用存储器件的物理特性在存储器内部实现各种逻辑与计算操作,从而完全消除了数据向计算单元的移动。基于具有内在计算能力的新型存储器件(如相变存储器、阻变式存储器、磁性随机存取存储器,以及基于自旋电子学的赛道存储器)构建的CIM系统,已在机器学习及其他应用领域展现出数量级的性能与能效提升。
近年来,众多创新性的近存计算(CNM)与存内计算(CIM)系统相继被提出,其中部分系统已实现商业化。这些系统包括面向特定应用领域的体系结构,如 Neurocube、ISAAC、Microsoft Brainwave 神经处理单元(NPU),以及多种深度神经网络(DNN)加速器等。这些系统在性能和能效方面相较于通用冯·诺依曼架构具有数量级的提升,但其应用范围通常局限于特定领域。UPMEM 展示了在更通用的现成系统中实现 CNM 的案例研究。近期,三星与 SK 海力士提出了基于 HBM2 和 GDDR6 DRAM 标准、支持 TFLOPS 级性能的面向机器学习的 CNM 系统。
在存内计算方面,仅在过去几年中,所有主要的存储技术厂商,包括三星、台积电、英特尔、格罗方德及 IBM,均已成功制造出基于忆阻器和 CMOS 技术的 CIM 芯片,展现出前所未有的性能和能效优势。尽管目前已有众多企业(如 Axelera、d-Matrix、Synthara、UPMEM 等)提供适用于机器学习及其他应用领域的 CIM 与 CNM 系统,但其可编程性仍是一大挑战。多数系统仅提供底层设备库,程序映射、同步机制及优化任务则完全依赖开发者手动实现,极大增加了系统的可编程性与可操作性难度。
尽管已有部分研究提出编译器方案以实现计算原语的自动映射、负载均衡及面向特定技术的优化,但这些方案大多面向同构架构,且仅支持特定应用场景,如基于忆阻交叉阵列的矩阵乘(GEMM)计算。鉴于未来体系结构将趋向高度异构化并具备更强的通用性,迫切需要构建新的编译器抽象模型与编译框架,以实现对设备无关及设备特定优化的统一支持。Meta(Facebook)等多个研究机构亦在近期文献中指出此方向的重要性,其中明确表示:“我们尝试将存内计算应用于内部工作负载,但发现该方法面临诸多挑战,其中最大的挑战便是其可编程性。”
为此,本文旨在构建一个面向高层次的框架,以对存内计算(CIM)与近存计算(CNM)设备进行抽象,使其能够通过高层框架与领域特定语言进行编程,并为其生成高效的目标代码。我们提出了 CINM(发音为“Cinnamon”),这是一个基于多级中间表示(MLIR)的新型编译框架,能够支持抽象的逐级降解,并在多个抽象层次上对计算原语及其内存行为与操作方式进行建模与优化分析。CINM 支持基于相变存储器(PCM)和阻变式存储器(RRAM)的 CIM 加速器,以及 UPMEM 的 CNM 架构。
在实验平台上,我们采用高性能的实际 UPMEM 系统以及扩展版本的 gem5 模拟器,分别用于评估为 CNM 与 CIM 系统生成的代码。在支持 PCM 与 RRAM 的加速器方面,CINM 实现并扩展了 OCC 编译流程,该流程可对忆阻交叉阵列进行自动编译。CINM 中的层级式降解机制能够为输入应用中的每个计算原语选择最适合的目标平台,并在不同抽象层次上进行转换,从而针对具体设备实现优化。
在评估方面,我们采用了 CNM 系统的 PrIM 基准测试集与适用于 CIM 系统的机器学习基准程序。具体而言,本文作出了如下贡献:
- 系统性地分析了当前 CIM 与 CNM 系统的设计格局,研究其架构特性与所支持的计算原语;
- 提出了 CINM——一个基于 MLIR 的端到端编译框架,能够将计算模式无缝映射至不同的后端目标;
- 在 CINM 中实现了多种既与硬件无关又面向特定硬件的抽象层,具体提出了 cim/cnm 抽象,用于实现面向 CIM/CNM 计算范式的通用操作,并在面向具体设备的方言中进行差异化的降解;
- 引入了高层次的 cinm 方言,用于统一抽象 CINM 系统中的所有设备,并为后续实现成本模型与自动化内核区域到异构设备的映射提供支撑;
- 实现了多个面向特定设备的抽象,能够执行感知设备特性的优化,并将计算映射至相应的设备库;
- 实验结果表明,CINM 在所选基准测试集中能够有效重现甚至超越手工优化代码的性能表现。
背景
本节将介绍 MLIR 编译基础设施,以及基于多种存储技术的近存计算(CNM)与存内计算(CIM)模型。
MLIR 编译器基础架构
MLIR 是一个用于表示与转换中间表示(IR)的工具集,支持在不同抽象层级上跨越多个应用领域和异构硬件目标进行编译优化。其设计理念是非限定性的,即 IR 本身仅提供极少的内建组件,大多数表示形式均可自定义。MLIR 允许编译器开发者将自定义抽象集成进编译流程,并在适当的抽象层级进行匹配,从而实现针对特定领域或硬件目标的优化。
MLIR 中的抽象通过“方言”(dialect)机制实现。方言是由一组自定义类型、操作与属性构成的逻辑集合。操作是中间表示的基本构件,负责接收输入值并产生新值。MLIR 中的每个值在编译时均与已知类型相关联。属性用于将编译时信息附加至操作上。
MLIR 中的方言机制确保了在中间表示上的变换保持正确性前提条件,以降低分析与优化过程的成本与复杂度。各类方言通常与应用领域(如用于线性代数的 linalg,或用于张量操作的 TOSA)、表示模型(如多面体模型中的 affine,或控制流中的 scf),或硬件目标(如 gpu、cim)相对应。
MLIR 所提供的抽象支持渐进式的降解与提升,即可从高层次的领域特定表示逐步降解至底层平台相关的方言,也可进行反向提升,以支持跨层次的编译与优化。
近存计算(Compute Near Memory)
近存计算是一种以数据为中心的计算范式,其目标是在靠近存储的位置处理数据。为减少数据移动,计算单元(如 CPU、GPU、FPGA、ASIC 或 CGRA)被物理地部署在接近存储器的位置,例如位于内存控制器中、外围电路中、内存芯片上,或通过共享交叉开关连接至内存芯片。近存计算的概念最早可追溯至20世纪70年代,在90年代,一些架构如 EXECUBE 与 IRAM 已展示出在多个应用中的显著性能提升。然而,设计复杂性和制造成本一度阻碍了其商业化进程。近年来制造与堆叠技术的进步有效缓解了这些工程实践难题,推动了多种新型 CNM 架构的兴起。
堆叠式 DRAM 结构(如混合内存立方体 HMC 与高带宽存储器 HBM)被视为 CNM 系统的关键推动技术。这类架构通过硅通孔(TSV)将多个 DRAM 晶粒堆叠于逻辑层之上,逻辑层可实现特定功能单元。相比传统 DRAM 家族,堆叠式解决方案在带宽与性能方面具有显著优势,但也可能带来刷新功耗增加与容量受限等问题。
UPMEM 将协处理器与 DDR4 DRAM 集成于同一 DRAM 晶粒上,其协处理器(即数据处理单元 DPU)为通用的 32 位 RISC 处理器。凭借高本地带宽、总体带宽与并行性,UPMEM 在多种应用中展现出数量级的性能与能效提升。每个 DPU 配备有一块私有的工作存储器(WRAM),并可访问共享的主存储器(MRAM)。UPMEM 提供了软件开发工具包(SDK)与相关工具链,以支持处理器内存一体化(PIM)编程模型。
近年来,三星与 SK 海力士相继推出了 FIMDRAM 与 AiM 架构。与 UPMEM 类似,这些架构也在 DRAM 晶粒上集成了协处理器(分别基于 HBM2 与 GDDR6 DRAM)。但不同于 UPMEM,它们的协处理器被专门优化用于机器学习负载。
存内计算(Compute In Memory)
存内计算范式在体系结构上实现了根本性转变,通过利用存储器件的物理特性来实现特定计算模式。忆阻器件如相变存储器(PCM)与阻变式存储器(RRAM)可在外部电压或电流作用下被编程至不同的电阻状态,每一状态代表一类信息。当这些器件以交叉阵列方式组织时,可在常数时间内实现固定尺寸的矩阵-向量乘法(MV)运算。然而,该类运算通常在模拟域中进行,需配合数模与模数转换器完成输入输出转换。
在另一类交叉阵列结构中,忆阻器可在数字域内实现全套逻辑运算。尽管如此,这类电阻型存储器写入速度较慢,且写操作会缩短器件寿命,因此在选择应用场景以实现 CIM 加速时需格外审慎。
磁性存储技术如磁性随机存取存储器(MRAM)与赛道存储器(RTM)也可用于在位实现部分计算操作。MRAM 单元中的磁隧道结(MTJ)具备自然实现异或(XOR)逻辑的能力,可用于构建更复杂的逻辑功能。类似于忆阻器,MRAM 单元也可组成交叉阵列结构,以执行矩阵-向量运算。RTM 器件同样以 MTJ 为访问接口,并可采用类似机制实现多种逻辑操作。此外,其独特的访问机制使其能够高效实现如计数与多数投票等复杂操作。
传统的基于电荷的 SRAM 与 DRAM 技术亦可在原位实现一系列逻辑与计算操作,进一步拓展了 CIM 范式的适用范围。
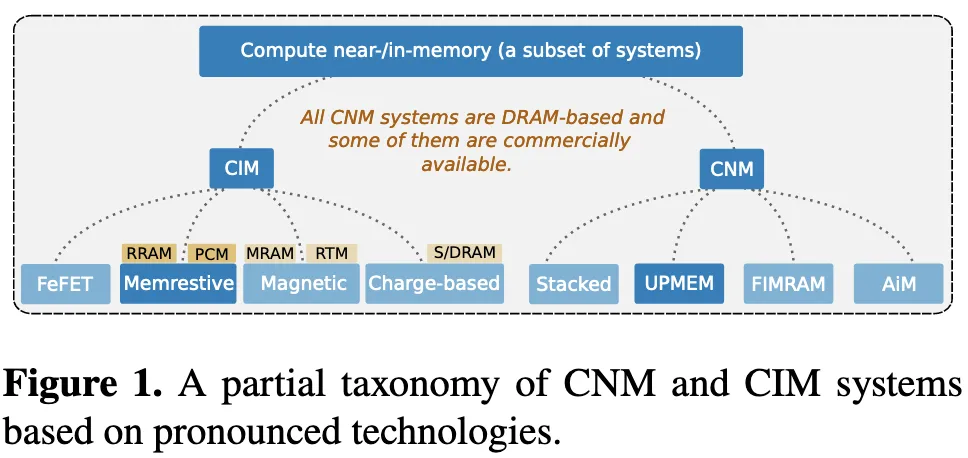
对 CIM 与 CNM 抽象的需求
图 1 展示了主流近存计算(CNM)与存内计算(CIM)系统的部分分类体系。在 CNM 部分,仅列出了已投入实际应用的系统;而在 CIM 部分,则呈现了当前较为成熟且具有发展前景的技术方案。