
Language Models for Code Optimization: Survey, Challenges and Future Directions
【综述解析·V】Language Models for Code Optimization: Survey, Challenges and Future Directions (推荐)
个人领域内强相关的综述(LMs,ML,Code Optimization,Compiler Optimization,Systems),链接🔗
元信息:
- 来源:Arxiv2025.01 的论文,感觉目标投稿为 CSUR,看样子已经投稿完毕了,但是 CSUR 审稿期很长,所以暂时还未到正刊。
- 作者:利兹大学 & TurinTech AI
- 利兹大学教授 Wang Zheng(王峥)算是领域内比较有名的人物之一了,至少在 AI for Compiler 和其他领域上从事十余年之久,他的很多论文和合著论文都是在领域内具有广泛影响力的,比较著名的就是一篇发在 CCF-A(Proceedings of the IEEE)的特邀论文 Machine Learning in Compiler Optimisation,他的合作单位广泛,Meta AI、爱丁堡大学较为出众,也和计算所编译的大团队有论文交集。
- TurinTech AI 是一家总部位于英国伦敦的 AI 初创公司,成立于 2018 年,由伦敦大学学院 (UCL) 的计算机和数据科学研究人员创办,他们的evoML 平台可以大规模自动化生成生产级 ML 模型;旗舰产品 Artemis更是一款“进化式 AI 平台”,能演化并验证 GenAI 生成的代码,据称可帮助用户在兼顾质量的前提下提升代码执行速度最多达 52%,今年(2025 年)3 月拿到了 2000 万美元的融资。
作者综述的 raw material 开源在: https://github.com/gjz78910/CodeOpt-SLR
浅谈
本文提供的是一个基于统计学的方法(数据驱动)的方式,来分析的语言模型在代码优化任务上的应用,并且以全栈(从数据集、技术路径到评估、测试)的形式来呈现。不过需要注意的是,这篇综述还是侧重于编译与编程,重点还是在系统软件这个层面,本文涵盖:
- 50 余篇重点文献
- 11 个专题性问题
- 5 大挑战
- 8 个未来研究方向
本文是重点围绕四大 RQs 和 11 个挑战和建议展开(从第四章开始):
- 用于代码优化的语言模型具有什么特征?
- 语言模型是如何应用于代码优化任务的?
- 代码优化问题是如何被定义的?
- 已有的代码优化方法是如何评估的?
每个作者提到的地方都可以作为小的论文切入点。但是问题也是在于对方法论的探讨有些欠缺,应该可以更加具体一些。
原文翻译
0. 摘要
近年来,构建于深度神经网络(DNN)之上的语言模型(LM)在代码生成、补全与修复等软件工程任务中展现出突破性的效果。这一进展为基于语言模型的代码优化技术的兴起奠定了基础,该技术对于提升现有程序的性能(例如加快程序执行速度)具有重要意义。然而,当前尚缺乏专门针对这一应用方向的系统性综述。为弥补这一空白,本文对50余篇相关研究进行了系统文献综述,识别了该领域的发展趋势,并围绕11个专题性问题展开深入探讨。研究结果揭示了五大关键挑战,包括模型复杂性与实际可用性的平衡、跨语言与跨性能的泛化能力、以及构建对人工智能驱动解决方案的信任等。此外,本文还提出了八个未来研究方向,旨在推动更高效、稳健且可靠的基于语言模型的代码优化技术的发展。因此,本研究为该快速演进领域中的研究人员与工程实践者提供了可行的研究建议与重要的基础性参考。
1. 引言
代码优化(Code Optimization, 亦称程序优化)历来是计算领域中的一项核心任务。代码优化旨在对程序进行多层次的转换——包括源代码层、中间表示(IR)层,乃至二进制层——以实现特定的性能目标,例如减少执行时间、减小代码体积或优化内存使用等。该任务在诸多软件工程活动中发挥着基础性作用,如代码生成、代码修复、代码编辑与代码重构等。
代码优化是一个覆盖编译全栈的过程,可以在任何阶段发生,上述三个确实是主要任务。
传统上,代码优化依赖于专家精心设计的启发式规则与策略,并通常结合基于编译器的程序分析,以提取程序中的关键属性(例如数据依赖与控制依赖),从而识别最优的优化路径。经过多年发展,研究者已提出了多种优化技术,从底层的指令调度、寄存器分配、向量化与循环变换(通常在编译器的中间表示或链接时应用)到更高层次的算法或数据结构替换(以提升源代码级的性能)。
然而,代码优化所面临的一项核心挑战在于其优化空间的巨大性。对于一个给定的程序,潜在的优化方式数以万计,穷尽搜索在计算上是极为昂贵的,往往需要耗费大量的计算资源与时间。在这一庞大的空间中,优质的优化方案稀疏且因程序而异。对于底层性能优化而言,最优解常常高度依赖于底层硬件体系结构,这进一步增加了人工设计有效优化策略的难度。即使制定出了精细的启发式方案,仍需随着应用负载及硬件环境的演进进行不断调整与适配。
过去几十年中,已有大量研究尝试将机器学习方法应用于代码优化任务。当前已有充足证据表明,机器学习技术在多种代码优化场景中展现出显著成效。近年来,随着基于深度神经网络的语言模型与生成式人工智能的发展,代码优化研究迎来了重要突破。这类先进模型展现出强大的能力,能够从训练数据中抽取知识,并有效迁移至测试样本,在多个任务中超越了传统的机器学习方法。其在建模与推理复杂代码结构方面的能力也极大激发了学术界对其在软件工程中应用的广泛兴趣,并在自动化与增强代码优化过程中取得了可喜成果。
随着机器学习、语言模型与代码优化之间融合的不断加深,该领域正迎来前所未有的研究机遇与技术革新。然而,尽管语言模型在代码相关任务中的重要性日益凸显,现有文献综述多集中于其在软件工程中的通用应用或特定领域(如自动程序修复),尚无系统性研究专门针对语言模型在代码优化方面的应用展开全面综述。
PS:APR 领域的论文确实特别多,我感觉 ISSTA 有一大半都是,当然人家会议主题就是这个。
如图 1 所示,为弥补这一空白,本文通过系统文献综述(systematic literature review, SLR)的方法,对当前基于语言模型的代码优化技术进行了系统性分析。具体而言,作者检索了六大主流学术文献数据库,识别并系统性评审了共计53篇主要研究文献。基于四个研究问题及其下设的11个子问题,本文对这些研究进行了分类整理,提炼出关键发现,并为读者提供了具有洞见性的研究建议。例如,我们的主要发现包括:
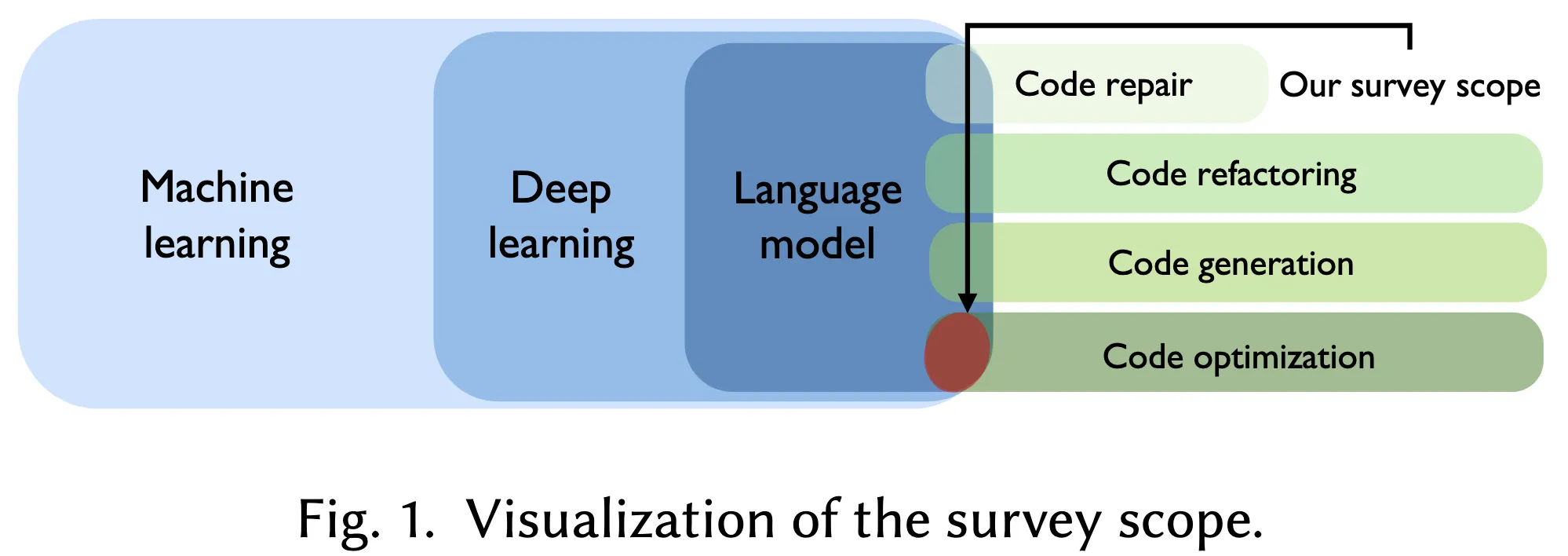
- 通用语言模型(如 GPT-4)因其更强的理解与推理能力而被更广泛采用(共61项实例),相较之下,专用于代码任务的语言模型则出现较少(43项实例)。
- 大多数研究(57%)采用了预训练模型,以节省开发时间与资源;而43%的研究则进行了模型微调,以满足特定任务需求。(注:
并非大多数) - 研究中最常被提及的挑战主要集中于性能与代码相关的问题,例如:单步优化的局限性(18项研究)、正确性与效率之间的权衡(15项研究)、以及代码语法的复杂性(10项研究)。
- 为应对这些挑战,多数研究选择构建专用模型(51项实例),尽管效果显著,但在泛化能力方面仍显不足。提示工程成为第二大常见策略(34项实例),因其数据效率较高而受到青睐,但依赖于专家经验。另有一类研究则通过重新定义代码优化问题(33项实例)来提升灵活性,尽管此方法在数据集准备方面成本较高。
上述单步优化的局限性是指没考虑多个优化的耦合性。
此外,本文还总结了现有文献中五项关键挑战,并提出了未来研究的潜在方向,具体包括:
- 随着语言模型规模与复杂度的不断提升,在大规模代码库上进行优化需消耗大量计算资源,因此亟需模型压缩与集成技术的发展;
- 当前基于语言模型的代码优化方法多在孤立环境中运行,缺乏与外部系统的有机集成,突显出发展具备自治能力(agentic)的语言模型的重要性;
- 研究普遍聚焦于单一编程语言(81%)和单一性能指标(79%),制约了方法的跨语言与多目标泛化能力,亟需推进多语言与多目标的优化方法研究;
- 多数研究采用合成数据集进行评估(68%),而非真实代码库,后者在规模与复杂性方面更具挑战性,表明需要建立能够反映真实开发场景的标准化基准数据集;
- 语言模型在生成优化结果时常出现不一致性或幻觉现象,因此在人机协同的优化流程中,应充分发挥人工智能的计算能力,同时确保结果的可靠性与可信性。
本文其余部分组织结构如下:第2节回顾了代码优化技术的发展历程;第3节介绍了系统文献综述所采用的方法论;第4至第7节分别呈现四个研究问题的分析结果与研究发现;第8节探讨当前存在的挑战与未来研究方向;第9节给出全文总结。
背景
本节概述了代码优化方法的相关概念和发展历史。
2.1 代码优化
本文聚焦于在保持原始功能语义不变的前提下,提升性能目标的代码优化技术,例如加快执行速度、减小二进制代码体积及降低内存使用。代码优化可应用于多个层级,包括源代码层、中间表示(IR)层以及二进制层。
你要说严格语义不变,那如何看待混合精度优化(Auto Mixed Precision)呢?值得评价一下…
在源代码层,通过替换算法、调整数据结构或改进实现细节,往往可以显著提升程序性能。例如,图2展示了两个用于计算前n个自然数之和的Python实现:图2a所示的为未优化版本,采用线性遍历求和,其时间复杂度为O(n);而图2b所示的优化版本采用公式直接计算,总体时间复杂度为O(1)。

在中间表示层,可应用多种优化与分析技术,如死代码消除、循环展开与向量化等,以减少冗余计算并充分利用底层硬件特性。在二进制层,诸如指令调度与内存布局优化等链接时优化手段,进一步提升计算与内存访问效率。
严格来说,指令调度属于机器级中间表示阶段,不是二进制,这里有失偏颇。
代码优化的一项核心挑战在于应对庞大而复杂的优化空间,其中蕴含大量可能的代码转换方式。在该空间中,优劣解并存,其效果往往依赖于具体的输入程序及底层硬件架构。有效的优化方法需具备稳健的策略以探索该搜索空间,并识别出高性能解。传统方法主要依赖人工设计的启发式规则、分析模型或经典的机器学习方法。
随着深度神经网络(DNN)与语言模型(LM)在复杂决策空间中取得的突破性进展,近年来越来越多的研究致力于将语言模型应用于代码优化任务,因其具备强大的泛化能力及生成可读解释的潜力。
虽然代码优化的核心目标是提升程序性能,但在更广义的软件开发过程中,若干相关活动同样扮演着关键角色。其中包括代码生成,即从结构化规格或自然语言描述自动生成代码,通常不依赖已有代码库;代码重构,旨在在不改变程序外部行为与性能的前提下,改善其内部结构与可读性;以及代码修复,指对程序进行修改以修复缺陷或引入新功能,确保其行为正确。
我们可以类比一下 autotuning,在编译器里是选项调优,但是放射到软件上,那可以是整个软件各个选项配置之间的自动优化。
在本综述中,我们将研究重点置于代码优化,因其对执行时间、内存占用等关键性能指标具有直接影响。优化后的代码不仅有助于构建更高效的软件系统,亦在资源受限环境下尤显重要,并在高性能计算等领域提供了显著的竞争优势。
2.2 代码优化方法的发展历程
自计算机发展初期以来,代码优化始终是软件开发中的关键组成部分。图3展示了代码优化技术的演进过程,概述了各阶段主要方法的优势与局限性。
这个图简直太完美了,把编译器的发展进程一图道破。但自己思考一下,有意思的是,手写 CUDA Kernel 算不算 Manual Optimization?
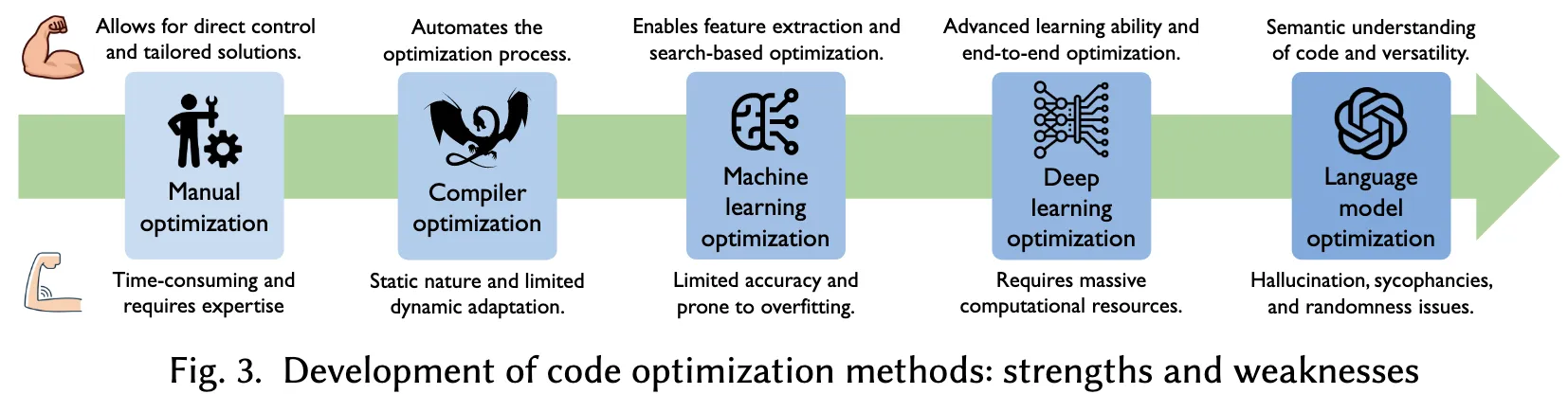
早期的代码优化主要依赖人工实现,开发者使用汇编语言手动编写与优化程序,采用如循环展开、函数内联与减少内存访问等技术,以提升执行效率并降低内存开销。随着高级编程语言的兴起,优化的职责逐步从开发者转移至编译器。现代编译器集成了多种优化策略,包括指令级优化(如窥孔优化),该技术通过重写局部指令序列以提高执行效率;循环优化技术(如循环展开与循环融合)用于降低循环控制开销;函数内联则通过将函数调用替换为函数体本身来减少调用开销。
近几十年来,机器学习(ML)逐渐成为提升代码效率的重要手段,其以数据驱动的方式推进优化流程。传统机器学习方法依赖精心设计的特征提取机制,以捕捉代码特性,从而识别性能瓶颈并指导优化策略。此外,ML模型可预测不同代码路径的性能表现,作为效用函数引导优化空间的搜索过程,寻找符合性能目标的转换方案。例如,Adler 等人提出基于搜索的方法,用以提升 SCRATCH 程序的可读性。基于ML的优化方案已被开源社区及工业界广泛采纳,例如,Artemis++ 利用变异算法自动生成优化后的 C++ 代码,在运行时间、CPU 占用及内存使用等方面取得明显改进。
深度学习(DL)作为机器学习的子领域,通过神经网络建模复杂代码关系,进一步推动了代码优化的发展。DL模型可自动学习代码的语义表示,发掘传统分析难以识别的优化机会。近年来,端到端优化方法受到广泛关注,其中DL模型可直接从源代码到可执行程序进行优化。例如,DeepTune 通过深度神经网络从原始源码中构建优化启发式规则,绕过了传统手工特征工程的过程。这类方法可以借助大规模代码及性能数据进行训练,从而简化并自动化整个优化流程。
尽管上述方法在某些场景中表现出色,但仍存在灵活性不足和可解释性差等问题,难以满足多样化应用需求。具体而言,手工优化要求开发者具备深入的软硬件知识;编译器优化尽管高效,但生成的代码未必是最优解,且其静态分析机制难以适应运行时条件变化。机器学习与深度学习模型虽具更强泛化能力,但高度依赖于特征提取与训练数据质量,难以准确建模代码中的复杂语义与上下文关系。此外,基于搜索的优化算法计算开销大,往往难以在合理时间内收敛到最优解。
重点还是可解释性差!
2.3 基于语言模型的代码优化
语言模型(Language Models, LMs)的最新发展为代码优化方法带来了范式转变。采用语言模型进行代码优化具有诸多优势。首先,语言模型在代码语义理解方面具备显著优势。通过在涵盖代码、功能、注释与文档等大量数据集上进行训练,语言模型能够掌握程序逻辑推理能力。这一能力使其在诸如循环重构、冗余计算消除与内存访问优化等复杂任务中优于传统的机器学习模型,并且能够根据用户目标实现精准优化。
注意,不是大语言模型,编译还是需要强调实时性的
例如,Li 等人提出的 AlphaCode 模型能够生成多样化的程序,进而通过筛选与分类机制识别出最优解,展现出在解决竞赛编程问题方面接近人类水平的性能。类似地,由 OpenAI 的 Codex 提供支持的 GitHub Copilot 工具也在集成开发环境(IDE)中通过实时建议与自动补全功能,提供了实用的代码优化支持。
语言模型的另一显著优势在于其在优化空间探索方面的能力。相较于依赖静态规则、预定义启发式方法或人工特征设计的手动或编译器优化方式,语言模型展现出更高的适应性与灵活性。得益于对大规模、多语言、多范式及多性能场景的数据集的训练,语言模型能够动态地推理、生成并优化代码,识别出传统静态方法常常忽视的优化机会。例如,Kang 与 Yoo 展示了语言模型在改进 Fibonacci 数列低效实现中的应用,表现出其在遗传改进(Genetic Improvement, GI)中的“变异器”角色,能够生成符合特定优化目标的变异体。
变异器,有点意思。
此外,语言模型在支持多种代码优化任务方面展现出卓越的多样性。其既可以作为“优化器”直接生成目标语言的优化代码,也可以作为“顾问”提供自然语言或代码与自然语言混合的优化建议,还能作为“编码器”将代码转化为特征向量供下游机器学习模型使用。同时,语言模型还可以作为“评估器”,预测特定代码变换可能带来的性能收益,从而指导优化策略的选择。这种多元功能使语言模型成为现代代码优化中的关键工具。
然而,使用语言模型进行代码优化也存在一定局限性。首先,训练与运行这类模型所需的计算资源较为庞大。其次,语言模型的效果在很大程度上依赖于其训练所使用数据的质量与多样性。此外,将语言模型集成进现有开发流程可能增加系统复杂性,需投入额外的专业资源,对于中小型团队而言可能构成障碍。尽管语言模型功能强大,但其并非万无一失,仍可能提出次优甚至错误的优化建议,因此仍需人类进行监督与验证。一项对语言模型与传统优化编译器在优化能力上的实证研究也表明,尽管语言模型在代码优化方面展现出巨大潜力,但在处理大型程序时仍存在困难,其优化效果往往仅相较传统工具有边际性提升。
3 方法论
本综述遵循 Kitchenham 和 Charters 提出的、在软件工程领域被广泛认可的系统化文献综述(Systematic Literature Review, SLR)指南,该方法已被大量 SLR 研究所采纳。如图 4 所示,本文的方法论主要分为三个关键阶段:
- 搜索阶段(Search):采用“准黄金标准(quasi-gold standard)”策略设计搜索字符串,进行全面的自动化文献检索,并辅以滚雪球式(snowballing)搜索,以确保覆盖尽可能全面的相关研究。
- 研究筛选阶段(Study Selection):通过严格的纳入与排除标准对检索结果进行过滤,并结合质量评估,仅保留高质量和可信度高的研究。
- 数据收集阶段(Data Collection):基于四个主要研究问题(RQs)构建了共 11 个细化问题,指导数据提取与分析工作,最终形成本综述的核心发现。
图 5 展示了本研究所有问题的分类体系。在后续章节中,将依次介绍每个研究问题的详细分类方法、主要发现及可行建议。

4 RQ1:用于代码优化的语言模型具有什么特征?
尽管语言模型已广泛应用于代码优化任务,但在如何高效利用这些模型方面,仍存在显著的研究空白。本节将探讨所使用语言模型的若干关键特征,提出每个子问题的详细分类体系,并分析其在代码优化中的具体意义。
4.1 RQ1.1:使用了哪些语言模型?
不同于专注于语言模型架构的综述文献,我们在本小节的目标是展示被用于代码优化任务中的基础语言模型的主要特征,并为未来研究者选择合适模型提供参考与启发。如表 1 所示,相关语言模型可被归为三大类:
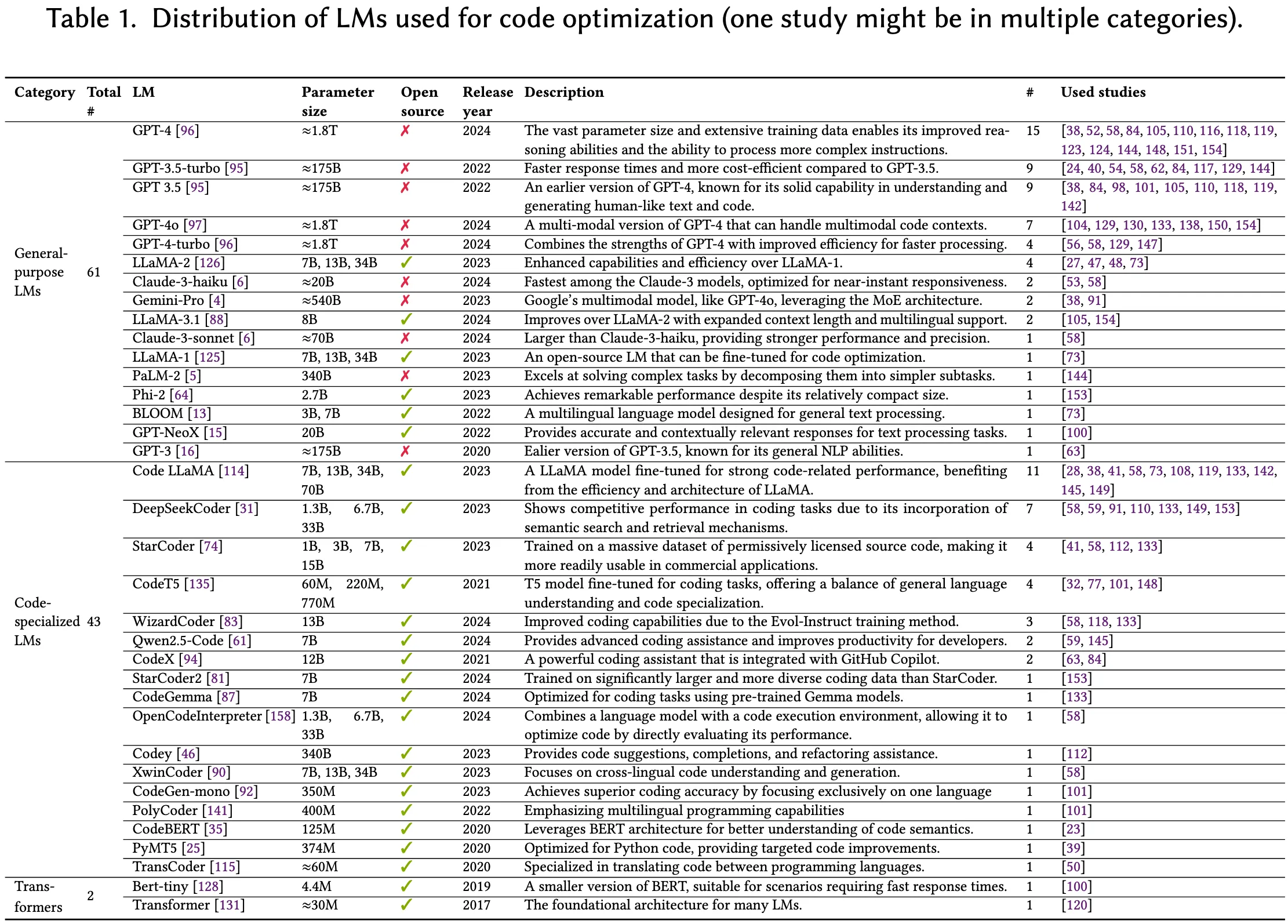
4.1.1 通用型语言模型(General-purpose LMs)
在纳入的原始研究中,共有 61 个通用型语言模型被使用。这类模型设计初衷并不局限于代码优化,而是面向多种自然语言处理任务。其中使用频率最高的是 OpenAI 的 GPT-3.5 与 GPT-4 两代生成式语言模型,尤其是 GPT-4,在 15 篇研究中被应用。Taneja 等人指出,GPT-4 在上下文理解与逻辑推理方面展现出卓越能力,尤其适合应用于高级代码理解与优化任务。除了 GPT 系列外,研究中还使用了 LLaMA 系列、Claude 系列及其他开源模型。例如,Han 等人选用 Claude-3-haiku,因其在处理大规模代码库时具备出色的语义理解与效率表现;Nichols 等人则在实验中发现 Gemini-Pro-1.0 在合成代码片段方面表现优异,因而加以采纳。
尽管这些通用模型并非专为编程任务而训练,但在代码优化中仍被广泛采用,其原因主要包括:
- 大规模多样化训练语料:模型具备更强的语言理解与上下文感知能力;
- 多功能性:不仅能生成优化代码,还可执行用户意图分析、自我评估等多种任务,适用于代码优化流程中的多个角色。
4.1.2 面向代码任务的专用语言模型(Code-specialized LMs)
在被审查的研究中,共有 43 个面向代码任务的专用语言模型被使用。这些模型专为处理编程相关任务而设计,因其在编程特定数据集上的定向训练,通常表现出更优异的性能。其中使用频率最高的包括:Code LLaMA(11 次)、DeepSeekCoder(7 次)、StarCoder(4 次)和 CodeT5(4 次)。例如,Li 等人选择了 Code LLaMA,该模型在 LLaMA-2 基础上结合了面向代码的结构调整,从而更适用于编码任务;Huang 等人则采用 DeepSeekCoder,理由是其在现有代码基准测试上表现优异,且便于后续微调。
相较于通用型语言模型,这类专用模型具有若干优势:
- 其设计更注重对代码语义的建模能力,能够更好地捕捉代码中的依赖关系、函数调用及复杂控制流程,从而更准确地理解代码结构与细粒度语义;
- 如表 1 所示,这些模型通常体积更小且为开源,便于针对特定任务(如代码修复、补全与翻译)进行微调。然而,这些模型在通用性方面可能不如通用型语言模型。
4.1.3 基于 Transformer 架构的语言模型(Transformer LMs)
最后,有两类代表性的基础语言模型基于标准的 Transformer 架构被采用。具体而言,Pan 等人使用了多个 BERT-tiny 实例进行特征提取,该模型是一种轻量级 Transformer,具有双向注意力机制和 440 万参数,因其计算效率高,可根据不同输入类型提取定制特征;Shypula 等人则使用了标准 Transformer 结构,用于指令级代码优化,旨在降低计算负担。
尽管这类基础模型在精度和表现上不及其后续发展模型,但在对响应时间和计算成本要求较高的应用中仍具有重要意义。由于其计算资源需求较低,可直接在开发者的本地计算机或局部集群上运行,无需将数据上传至云端,从而非常适合不愿将代码或数据传输至第三方服务平台的企业用户。
- 发现 1: 通用型语言模型因其广泛的理解与推理能力,在代码优化任务中被最广泛采用;面向代码的专用语言模型在特定优化任务中表现优越,但在通用性方面存在一定局限;而基于 Transformer 架构的基础模型尽管精度较低,仍在资源受限的应用场景中具有关键作用。
- 建议 1: 基于表 1 中不同语言模型特征的总结,未来研**究可依据具体需求选择最合适的模型** ,亦可探索将多种模型类型集成至同一工作流中,从而最大化其互补优势。
4.2 RQ1.2:所使用语言模型的参数规模如何?
本小节探讨用于代码优化的基础语言模型的参数规模,相关信息如图 6 所示。依据 Minaee 等人提出的语言模型规模划分标准,我们将模型按参数数量分为四个等级:
- 超大型(Very large):参数量超过 1000 亿;
- 大型(Large):参数量在 100 亿至 1000 亿之间;
- 中型(Medium):参数量在 10 亿至 100 亿之间;
- 小型(Small):参数量不超过 10 亿。
该分类体系有助于揭示不同规模模型在性能与资源开销方面的差异,从轻量高效模型到能完成高级任务的复杂模型,展现出语言模型在代码优化任务中多样化的能力范式。
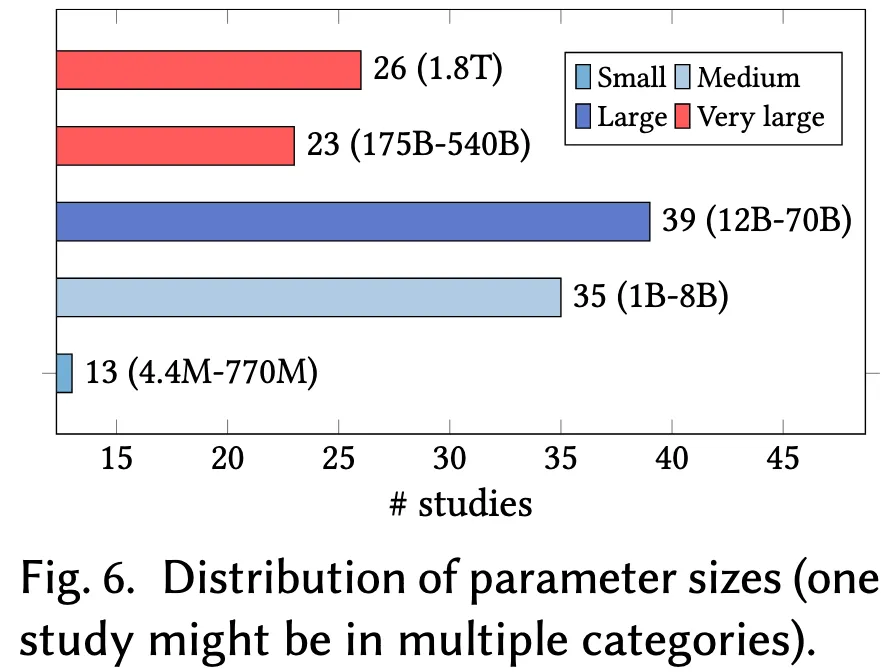
4.2.1 超大型模型(Very Large Models)
研究中共使用了 49 个超大型语言模型,其参数规模从 1750 亿(如 GPT-3.5)到 5400 亿(如 Gemini-Pro),甚至达到 1.8 万亿(1.8T)(如 GPT-4)。这类模型具备处理高度复杂代码优化任务的能力,例如代码性能预测、代码翻译以及代码向量化。Sun 等人提供了一个代表性示例,其将 GPT-4 融入代理式工作流程中,使其同时担任任务顾问、代码优化器与性能评估器,在多个复杂优化角色中表现出强大的综合能力。
AutoSAT: Automatically Optimize SAT Solvers via Large Language Models
4.2.2 大型模型(Large Models)
大型模型的参数量介于 120 亿至 700 亿以上,被应用于 39 个研究场景,尤其适用于更深层次的上下文理解任务,如基于“快-慢代码对”的学习、问题推理以及代码表示的解码等。例如,Ridnik 等人使用 DeepSeek-33B 模型进行代码问题推理与极端测试用例生成,该模型因其对代码上下文的深刻理解,能够有效优化复杂程序。
4.2.3 中型模型(Medium Models)
中型模型的参数量在 10 亿至 80 亿(1~8B)之间,在文献中出现了 35 次。这类模型在性能与资源开销之间实现良好平衡,适用于适度复杂的任务,如测试用例生成、初始(低效)代码生成与优化路径采样等。以 Grubisic 等人为例,他们使用 LLaMA-2-7B 生成代码优化路径,根据输入内容生成高效的优化指令序列,在优化能力与计算效率之间取得了良好折中。
4.2.4 小型模型(Small Models)
研究中还采用了 13 个小型语言模型,参数规模从 440 万到 7.7 亿不等,适用于一些基础但关键的任务,如输入预处理、自然语言分析以及类型推断等。例如,Pan 等人使用 Bert-tiny(4.4M 参数)对多种代码上下文进行编码,该模型在资源消耗极低的前提下提供了足够的准确性。
本分类体系概述了用于代码优化的语言模型在规模上的多样性,并强调了根据任务特点选择合适模型的重要性。不同任务对模型能力的需求差异显著,因此选择适配的模型规模对于实现高效、有效的优化至关重要。此外,还应指出,这一分类是暂时性的。随着更高效硬件与训练范式的发展,参数量更大的模型可能成为常规,推动“大模型”的定义不断向上演进。因此,模型规模划分标准也需动态调整,以反映人工智能领域不断变化的发展格局。
- 发现 2: 用于代码优化的语言模型在参数规模上呈现显著差异,通常任务越复杂,所选用的模型越大,而大型模型在实践中整体更受青睐。
- 建议 2:
- 研究人员应根据具体的优化需求,慎重选择最适用的语言模型;
- 随着语言模型技术的快速发展,“大型模型”的参数标准可能会不断演变,因此在使用该术语时应保持谨慎,避免混淆。
4.3 RQ1.3:这些语言模型是如何训练的?
本节探讨语言模型的预训练与微调过程,相关内容如图 7 所示。理解这些训练流程对于提升模型性能并使其适配特定任务至关重要。
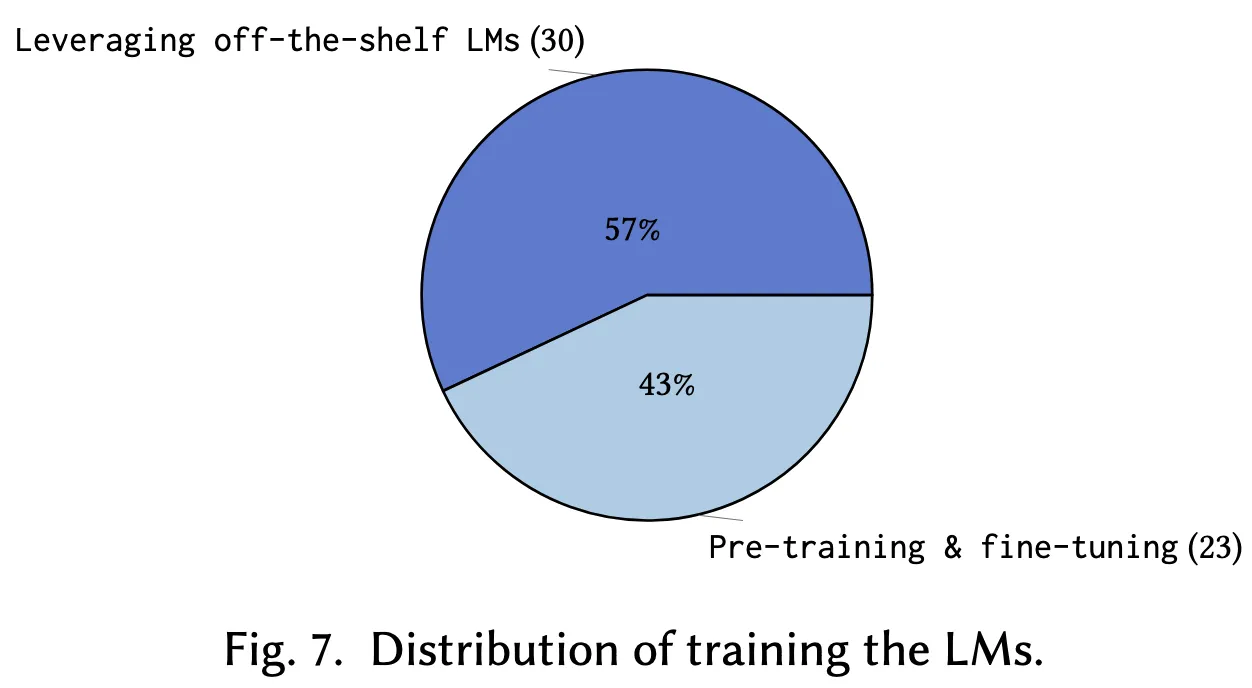
4.3.1 使用预训练模型(Leveraging Off-the-shelf LMs)
深度神经网络的核心在于从数据中学习。模型训练的本质是通过大规模数据暴露,使语言模型能够捕捉代码中的复杂模式与结构关系。许多语言模型在包含代码的数据集上预训练,从而具备了代码推理的能力。因此,研究人员可以利用现成的预训练模型,借助提示工程(prompt engineering)等方法进行任务适配,而无需进行模型微调。
如图 7 所示,在被纳入的研究中,有 57% 直接使用了现成的预训练模型。这种方式允许研究者在无需承担高昂训练成本的前提下,访问大型语言模型资源,而这些成本通常超出一般学术机构或个人研究者的承受范围。
然而,完全依赖预训练模型也存在挑战,例如预训练数据中可能存在的偏差、模型对特定领域任务适应能力有限,以及模型行为的不可解释性等问题。
4.3.2 预训练与微调(Pre-training and Fine-tuning)
相较之下,有 43% 的研究选择对语言模型进行微调,以适应更小范围且更具针对性的任务需求,从而提升模型在特定代码优化任务中的准确性与有效性。例如,Shypula 等人构建了包含“低效代码-高效代码”对的原始数据集,并在此基础上对模型进行微调,使其能更具上下文相关性地生成优化方案;又如,Cummins 等人将预训练的 Code LLaMA 在大规模 LLVM-IR 与汇编代码语料上进一步微调,以加强其对编译器语义与优化技术的理解,并通过指令调优(instruction tuning)提升其在编译器优化任务上的性能。
尽管微调带来了显著提升,但也存在一定风险,例如过拟合,即模型在特定任务上表现优异但失去泛化能力。此外,仅有两项研究选择从零开始训练模型,且规模均较小——如 Garg 等人从头训练了参数为 3.4 亿的 PyMT5 模型,训练数据包括英文语料与开源代码;Shypula 等人则预训练了一个 8000 万参数的标准 Transformer 模型,数据集包含超过 161 万个开源程序,用以学习通用编程模式。
这一分布反映出训练语言模型对硬件与能耗的高度依赖。因此,研究者应在性能与资源效率之间权衡,谨慎选择是直接使用预训练模型,还是进行微调甚至从头训练。
- 发现 3: 虽然多数研究(57%)为了节省时间与计算资源而直接采用预训练模型,仍有 43% 的研究强调微调在实现任务适配与提升模型性能方面的重要作用,是不可忽视的关键环节。
- 建议 3: 未来的研究者应根据自身的具体需求,慎重权衡是采用预训练模型还是进行微调,以在模型性能与计算资源之间取得合理平衡。
5 RQ2:语言模型是如何应用于代码优化任务的?
理解语言模型在代码优化任务中的具体应用方式,有助于识别研究者与开发者所面临 的关键挑战,并提供如何利用先进模型克服这些障碍的启示。因此,本节将探讨语言模型在代码优化中的多种应用方式,重点分析社区面临的挑战、应对方案以及语言模型在这些方案中所扮演的角色。
5.1 RQ2.1:所应对的常见代码优化挑战有哪些?
表 2 总结了主要研究中所关注的常见挑战。我们将这些挑战划分为五大类,以便识别其中的共性问题,并为构建更有效的优化策略提供理论基础与实践指导。
值得收藏这张表
| Category | Total # | Challenge(挑战) | # studies | Reference |
|---|---|---|---|---|
| Performance | 49 | 一步生成能力的局限性 | 18 | [32, 53, 54, 58, 62, 77, 84, 101, 105, 108, 110, 117, 120, 124, 142, 145, 150, 154] |
| 正确性与性能的权衡 | 15 | [41, 58, 59, 91, 98, 100, 101, 104, 108, 124, 129, 130, 133, 149, 153] | ||
| 对人工专家的依赖 | 13 | [23, 24, 39, 40, 53, 56, 98, 123, 129, 142, 145, 147, 151] | ||
| 代码可维护性差 | 2 | [52, 118] | ||
| 性能受硬件影响较大 | 1 | [119] | ||
| Code | 24 | 代码复杂性 | 10 | [28, 50, 84, 112, 117, 124, 138, 144, 147, 150] |
| 本地化代码修改的受限能力 | 4 | [27, 38, 100, 119] | ||
| 不完整的代码表示 | 4 | [28, 47, 63, 77] | ||
| 对低级语言探索不足 | 3 | [28, 50, 138] | ||
| 难以适用于真实世界中的代码 | 2 | [24, 120] | ||
| 问题表示能力有限 | 1 | [110] | ||
| Dataset | 18 | 缺乏效率相关的数据集 | 9 | [32, 39, 41, 59, 91, 101, 119, 133, 149] |
| 对人工标注数据的依赖 | 3 | [84, 116, 153] | ||
| 缺乏低级语言数据集 | 2 | [28, 56] | ||
| 缺乏真实世界数据集 | 1 | [120] | ||
| 缺乏可维护性相关的数据集 | 1 | [118] | ||
| 缺乏代码编辑相关的数据集 | 1 | [73] | ||
| 缺乏类型推理相关的数据集 | 1 | [148] | ||
| LM | 15 | 跨领域泛化能力有限 | 3 | [23, 40, 56] |
| 语言模型查询效率低 | 2 | [145, 151] | ||
| 采样方法存在局限 | 2 | [48, 110] | ||
| 微调成本高 | 2 | [32, 40] | ||
| 语言模型的幻觉问题 | 2 | [105, 123] | ||
| 语言模型的迎合倾向 | 1 | [105] | ||
| 语言模型结果的随机性 | 1 | [147] | ||
| 难以处理多种类型的输入 | 1 | [100] | ||
| 解空间探索不充分 | 1 | [112] | ||
| Compiler | 3 | 编译器优化能力有限 | 3 | [23, 27, 147] |
5.1.1 性能相关挑战(Performance-related Challenges)
最常见的挑战与性能问题相关,共计出现 49 次。其中,18 项研究指出在语言模型的一步式推理过程中缺乏性能反馈。例如,Madaan 等人指出,语言模型在首次生成输出时往往难以达到最优结果,因而需要反馈机制来从错误中学习并逐步提升性能。对此,他们提出了 SELFREFINE 框架,使语言模型能够对自身输出生成反馈,通过迭代式的性能增强与自反馈循环显著提升代码推理能力。
Self-Refine: Iterative Refinement with Self-Feedback(NeurIPS 2023)
此外,有 15 项研究关注性能与正确性之间的权衡问题。在代码生成过程中,生成结果虽然语法正确,但在效率上常常表现不佳,导致程序执行时间延长与资源消耗增加。
另有 13 项研究指出对人类专业知识的高度依赖构成挑战,凸显了手工解释与代码优化所需资源的密集性。其他性能相关问题还包括代码可维护性差以及硬件依赖性带来的性能波动。例如,Shypula 等人指出,在不同硬件平台上测量优化效果可能导致结果不一致,从而影响优化评估的可信度。为了解决这一问题,他们使用如 gem5 等硬件模拟器获取确定性的运行时间测量值。然而,精确的硬件仿真速度远低于真实硬件执行效率,限制了可用于实验的程序规模与复杂度。
5.1.2 代码相关挑战(Code-related Challenges)
在被审查的研究中,有 24 项挑战直接与代码本身相关。具体而言,代码 语法复杂性 成为语言模型面临的主要困难之一,已有 10 项研究对此进行了分析。例如,Cummins 等人指出,庞大的优化空间、嵌套结构及其复杂交互极大增加了优化任务的复杂度,阻碍模型生成有效解决方案的能力。
- 其次,有 4 项研究探讨了当前方法对于局部代码修改的局限性,现有优化手段往往集中在局部层面,难以有效触达算法与数据结构层级的性能瓶颈。Gao 等人进一步指出,缺乏对跨代码片段的组合式优化策略限制了全局性能提升的潜力。
- 另外,有 4 项研究指出代码表示的不完整性问题,该问题可能导致优化过程中关键信息的缺失,进而影响优化效果。
- 另有 3 项研究指出,低级语言(如汇编语言)结构化语义较少、冗长冗余性高,使其更难被准确解释与优化。
- 最后,有 2 项研究专门讨论了将优化推广至真实世界代码的挑战,强调了构建包含真实程序的数据集的必要性。Ridnik 等人指出,真实应用场景下的代码优化问题往往存在高度细致与模糊的自然语言描述,使得问题表达和建模本身就构成显著难点。
最后一点还蛮容易被忽略了,可以下手
5.1.3 数据集相关挑战。
数据集的有限可用性被认为是第三大主要挑战,共被提及18次。其中,以缺乏与效率相关的数据集最为突出,在9项研究中出现。例如,Huang 等人指出,现有数据集通常缺乏评估与提升代码效率所需的性能分析数据,凸显了对同时覆盖正确性与效率指标的高质量数据集的迫切需求。另有三项研究指出对人工标注数据的依赖,这类数据的获取代价高昂且耗时,限制了代码优化方法的可扩展性。此外,低级语言数据集的匮乏在两项研究中被单独提及,另有四项研究分别指出在特定任务中存在数据集缺失的问题,包括代码编辑与类型推断等方面。
5.1.4 语言模型相关挑战。
与语言模型(LM)相关的挑战共被提及15次,其中跨领域泛化能力最为频繁地被提及。正如有研究指出,现有优化技术往往难以在不同编程风格与模式间实现良好泛化,导致其适用性受限。此外,语言模型存在幻觉问题,即生成与事实不符或无意义的输出,这可能误导用户并降低模型的可靠性;又如模型微调在资源受限的情境下存在困难,也是两项研究中指出的挑战。例如,Zelikman 等人发现多数现有方法依赖于手动优化提示或输出,这种方式效率低下、难以扩展,因此他们设计了一种自我改进的脚手架程序以结构化地与语言模型交互,从而提升查询效率。另有若干挑战各被单独提出一次,包括:语言模型的迎合倾向,即模型在无批判性评估的前提下过度顺应用户提示;模型内在的随机性,导致输出不稳定,进而影响代码优化结果的可预测性与一致性;模型处理多类型输入的困难,限制了其在复杂代码上下文中的适用性;以及对解空间探索不足的问题,即模型未能充分挖掘所有可能的优化策略,从而产生次优性能改进。
5.1.5 代码分析相关挑战
最后,有三项研究指出现有代码分析工具(如编译器)能力受限的问题,表明这类工具在某些方面存在改进空间,语言模型或可在此类任务中发挥补充作用。例如,Yao 等人指出现有基于编译器的方法常难以处理复杂的寄存器传输级(RTL)模式。类似地,另有研究认为,尽管编译器能够执行一系列自动优化,但其往往无法捕捉需依赖高级代码语义理解与上下文分析的优化操作,如重构低效算法或调整数据结构。而语言模型具备更强的语义理解与上下文分析能力,有望在此领域弥补编译器的不足。
- 发现4: 最常被强调的挑战集中在性能与代码层面,主要包括一步式优化的局限性(18项研究)、正确性与效率之间的平衡(15项研究)以及代码语法的复杂性(10项研究)。
- 建议4: 研究者应关注常见挑战的同时,也不可忽视那些虽然提及频次较低但同样关键的问题,例如语言模型的幻觉现象。
5.2 RQ2.2:语言模型如何应对这些挑战?
本节探讨了当前语言模型(LM)在应对代码优化挑战中的应用方式,整体上可归为三类:构建专用模型、利用提示工程(prompt engineering)、以及提出新的代码优化问题,如表3所示。通过分析这些技术及其针对的挑战,研究人员与实践者可从中获取有价值的见解,从而在选择技术路径时结合自身约束与需求(如算力、任务复杂度或数据可用性)做出更加合理的决策。
表 3 是代码优化工具的领域分布(一篇论文可以在多个类别)
| Category | Total # | Technique(技术) | # studies | Reference | Addressed challenge(所应对的挑战) |
|---|---|---|---|---|---|
| Model-based | 51 | 基于反馈的迭代优化 | 35 | [24, 32, 38, … 153, 154] | 一步生成局限性 (14), 正确性与性能权衡 (12), 代码复杂性 (8), 对人工专家依赖 (8), 数据集效率低 (5), 依赖人工标注数据 (4), 查询效率低 (3), 幻觉问题 (2), 微调成本高 (1), 解空间探索不足 (1) |
| Agentic 工作流 | 6 | [104, 116, 123, … 154] | 正确性与性能权衡 (2), 代码复杂性 (2), 对人工专家依赖 (1), 依赖人工标注数据 (1), 幻觉问题 (1) | ||
| 编译器模拟 | 4 | [27, 28, 47, 50] | 代码复杂性 (2), 代码表示不完整 (2), 低级语言探索不足 (2), 本地化修改受限 (1), 编译器优化能力有限 (1) | ||
| 直接偏好优化 | 3 | [41, 91, 153] | 正确性与性能权衡 (1), 数据集效率低 (2), 依赖人工标注数据 (1) | ||
| 编译器传递采样 | 1 | [48] | 采样方法局限 (1) | ||
| 集成学习 | 1 | [149] | 正确性与性能权衡 (1), 数据集效率低 (1) | ||
| 编码器-解码器架构 | 1 | [100] | 本地化代码修改受限 (1), 多输入类型处理 (1) | ||
| Prompt engineering | 34 | 少样本提示 | 11 | [54, 73, 84, … 153] | 一步生成局限性 (3), 代码复杂性 (3), 对人工专家依赖 (3), 正确性与性能权衡 (2), 数据集效率低 (2), 查询效率低 (1) |
| 上下文提示 | 9 | [56, 58, 63, … 148] | 一步生成局限性 (2), 正确性与性能权衡 (2), 代码复杂性 (2), 代码表示不完整 (2), 可维护性差 (1), 泛化能力有限 (1) | ||
| Chain-of-thought(思路链提示) | 8 | [38, 62, 116, … 150] | 一步生成局限性 (3), 本地化修改受限 (2), 对人工专家依赖 (2), 正确性与性能权衡 (1), 代码复杂性 (1), 查询效率低 (1), 幻觉问题 (1) | ||
| 基于检索的增强生成 | 5 | [38, 40, 119, 142, 147] | 本地化修改受限 (2), 对人工专家依赖 (2), 一步生成局限性 (1), 性能受硬件影响 (1), 微调成本高 (1), 泛化能力有限 (1) | ||
| Problem formulation | 33 | 支架式优化 | 1 | [151] | 查询效率低 (1) |
| 数据集设计 | 19 | [23, 27, 28, … 153] | 数据集效率低 (8), 正确性与性能权衡 (7), 一步生成局限性 (2), 本地化修改受限 (2), 对人工专家依赖 (2), 代码表示不完整 (2), 低级语言探索不足 (2), 类型推理 (1), 可维护性 (1), 编辑能力 (1) | ||
| 强化学习 | 6 | [32, 53, 62, … 119] | 一步生成局限性 (3), 数据集效率低 (3), 正确性与性能权衡 (1), 依赖人工标注数据 (1), 代码表示不完整 (1) | ||
| 基于搜索的方法 | 4 | [38, 54, 112, 120] | 一步生成局限性 (1), 代码优化目标冲突 (1), 代码复杂性 (1), 本地化修改受限 (1), 解空间探索不足 (1) | ||
| Code token tree(代码标记树) | 1 | [108] | 正确性与性能权衡 (1) | ||
| 模块化生成 | 1 | [144] | 本地化修改受限 (1) | ||
| 评估指标设计 | 1 | [101] | 解空间探索不足 (1) | ||
| 差异合成 | 1 | [23] | 一步生成局限性 (1), 正确性与性能权衡 (1) |
5.2.1 基于模型的技术
最常见的应对策略是设计专用模型以直接应对代码优化中的挑战,共计在51项研究中出现。其中,基于反馈的迭代优化技术最为突出,在35项研究中被采用。这类方法利用来自评估过程中的不同类型的反馈信息来应对多种挑战,其中最常涉及的包括:一步式优化的局限性(14项研究)、正确性与性能的平衡(12项)、代码复杂性(8项)以及对人类专家的依赖(8项)。例如,Duan 等人提出的 PerfRL 将语言模型与强化学习框架结合,借助单元测试中编译与运行时的反馈数据,迭代优化代码的运行效率(《Leveraging Reinforcement Learning and Large Language Models for Code Optimization》)。Peng 等人则使用 agent 化工作流优化代码的能耗,其中包括一个生成型语言模型代理用于生成并迭代优化代码,以及一个评估型语言模型代理,用于基于正确性和能耗提供反馈。此外,SELF-REFINE 模型展示了使用同一个语言模型同时完成代码优化与性能评估的可行性。然而,这类基于反馈的技术可能会带来较高的计算成本,并需要大量资源来生成与处理反馈信息。
Agent 化方法在6项研究中被探索,主要应对诸如正确性与性能平衡、代码复杂性以及语言模型幻觉等挑战。例如,Sun 等人提出了 AutoSAT 框架,将语言模型代理分别作为:
- 行动者,用于决策与执行;
- 代码优化器,根据反馈生成优化代码;
- 评估器,根据已有代码提供反馈。该方法有助于验证与细化语言模型生成的启发式规则,降低幻觉影响,提升输出可靠性。然而,此类方法可能面临可扩展性问题,且多代理系统之间的协调复杂性较高。
另有四项研究设计了模拟编译器的模型,以应对代码复杂性与探索范围有限、不完整的代码表示以及传统编译器优化能力受限等挑战。例如,Cummins 等人提出的系统不仅生成优化指令序列(pass list),还能直接像编译器一样生成优化后的代码,从而跳过传统编译流程,并减少多次编译以评估不同优化策略的需求。此类模型通常需要特定领域知识与数据集的支持。
其他方法还包括:
- 直接偏好优化(Direct Preference Optimization, DPO):通过训练语言模型根据预设标准对输出进行排序与筛选,从而提升优化质量;
- 编译器 passes 采样:使用确定性采样技术引导语言模型结构化地探索优化 passes;(这个应该还要配合插桩)
- 集成学习(ensemble learning):融合多个语言模型的参数或输出,构建统一的模型;
- 编码器-解码器结构:例如由多个 BERT-tiny 编码器和一个 GPT-NEO 解码器组成,以有效处理多种代码上下文。
5.2.2 提示工程技术
通过精心设计和结构化输入提示以引导语言模型(LM)生成期望输出,提示工程成为应对代码优化挑战的第二大类策略,共在34项研究中被采用。多种提示方式被用于指导语言模型执行优化任务,主要包括以下几种:
- 首先,少样本提示(few-shot prompting) 被11项研究采用,该技术通过向语言模型提供少量输入-输出示例,使其能够泛化到新的优化任务,进而应对诸如一步式优化的局限性以及对人工标注数据的依赖等挑战。例如,有研究构造提示时组合多个程序数据库中表现最佳的程序样例,以帮助模型学习高效的模式并进行推广。然而,该方法的有效性在很大程度上依赖于所提供示例的质量与代表性,可能存在泛化能力受限的风险。
- 其次,上下文提示(contextual prompting) 在9项研究中出现,主要针对代码复杂性与代码表示不完整等挑战。该方法通过为语言模型提供全面且相关的上下文信息来增强其对优化任务中代码的理解,常以提示模板的形式呈现。例如,有研究通过在提示中引入任务描述、测试用例、初始代码、开销分析与优化规则等多种类型的上下文,从而提升语言模型生成高质量优化结果的能力与效率。然而,上下文提示也存在信息量过大可能导致模型性能下降的风险。
- 思维链提示(Chain-of-Thought, CoT) 被8项研究采用,用以增强语言模型在复杂优化任务中的推理能力。该技术通过引导模型生成中间推理步骤,再得出最终结论,以应对一步式优化限制与局部代码修改受限等挑战。特别地,有研究提出了一种自我检查式的代码-CoT方法,引导语言模型将优化任务分解为若干逻辑步骤,包括生成测试用例、自检和迭代修正代码,从而保障最终输出在性能与正确性方面的双重目标。需注意,此类方法通常要求更多的计算资源,且对中间步骤设计提出更高要求。
- 检索增强生成(Retrieval-Augmented Generation, RAG) 在5项研究中被探索,用于引入外部知识,以缓解局部代码修改受限、对人类专家依赖及微调成本高昂等挑战。例如,当用户提供待优化代码与相关说明时,系统通过索引检索机制从定制代码库中匹配最相关的代码嵌入,并将检索结果与原始提示结合,引导语言模型生成更优的代码。与上下文提示不同,RAG 可动态从外部数据库实时检索并整合信息,提供更具时效性与针对性的支持。然而,其面临的关键挑战在于如何选择合适的检索指标,并确保检索结果的准确性与相关性。
- 最后,还有研究提出了脚手架优化(scaffolding optimization) 方法,构建一个结构化提示语言模型的脚手架程序,使其能够在多轮迭代中自我优化提示与输出,从而提升整体优化效果。
5.2.3 基于问题建模的技术
最后一类方法通过重新建构任务目标、提出新的问题形式来应对代码优化中的基础性挑战,在文献中共出现33次。其中,有19项研究选择了数据集建构的策略,即构建新的代码优化数据集,以应对现有数据集在多种任务目标下的不完整性问题,例如针对正确性与效率权衡、低级语言、真实世界场景、类型推断与代码编辑等方面。例如,Shypula 等人提出了 PIE 数据集,这是一个包含超过77,000对 C++ 竞赛代码提交的集合,每对样本由同一用户提交的较慢与对应较快版本组成,为代码优化提供了基础数据支持。在此基础上,Ye 等人进一步构建了 PIE-problem 数据集,不仅要求样本对来源于同一用户,还来自同一题目,并筛选出在运行时间上至少有90%相对提升的样本对。这类技术的关键挑战在于如何确保构建的数据集具有高质量,并能覆盖多样化的代码优化场景。
另有6项研究将代码优化任务建模为强化学习(Reinforcement Learning, RL)问题,将其视为一个序贯决策过程,语言模型依据环境反馈(如代码执行结果、编译器分析信息、语言模型评估代理等)逐步进行优化操作。与基于搜索的方法不同,RL 通过与环境交互不断调整优化策略,具备动态适应性。然而,该方法面临的主要挑战包括奖励函数或反馈机制的设计难度,以及探索与利用之间的权衡。
同样地,有4项研究将代码优化形式化为基于搜索的问题。此类方法试图通过系统性地在庞大的可能解空间中寻找最有效的修改方案,发掘那些常规一步式优化方法难以捕捉的复杂优化模式。例如,Gao 等人采用进化搜索算法并结合执行反馈,引导语言模型在其提出的 Search-Based LLM(SBLLM)框架中不断改进优化方案。然而,搜索空间的复杂性可能导致计算开销显著,且易陷入局部最优,限制了最终优化效果。
此外,还存在若干较少采用但具有启发性的技术路径,包括:
-
代码标记树(Code Token Tree, CTT):一种动态更新机制,利用历史性能数据引导代码生成过程,逐步提升代码表现;
-
模块化生成(Modular Generation):按需动态生成模块,以高效应对代码结构复杂性;
-
指标设计(Metric Design):提出新的评估指标(如归一化性能指数 NPI),激励语言模型在输出中更加注重效率;
-
差异合成(Diff Synthesis):将优化后的代码视为原始代码的差异文件,仅保留必要的代码修改,从而降低引入新 bug 的风险。
-
发现5: 模型驱动技术最为普遍且有效(51项研究),但可能面临可扩展性问题;提示工程方法数据使用效率高,但其设计依赖专家知识(34项研究);而基于问题建模的策略具备高度灵活性,但在问题定义与数据集准备上需投入大量工作(33项研究)。
-
建议5:
- 研究者可结合表3中的总结,识别最适合当前具体挑战的技术路径;
- 亦可融合已有研究中的方法洞见,设计出适用于特定代码优化任务的创新性解决方案。
5.3 RQ2.3:语言模型在代码优化流程中扮演了哪些角色?
本节回顾并总结了语言模型(LM)在代码优化流程中的关键角色,如表4所示。该问题对于研究人员与实践者尤为重要,能够帮助他们理解语言模型在优化过程各阶段中的贡献,并据此决定是否以及如何引入其他技术,以进一步提升语言模型的性能。
表 4. 语言模型扮演的角色
| Category | Total # | Role | # studies | Reference |
|---|---|---|---|---|
| Generation | 73 | Optimizer | 46 | [24, 32, 38–41, 48, 52–54, 56, 58, 59, 62, 63, 73, 77, 84, 91, 98, 101, 104, 105, 108, 110, 112, 116–120, 123, 124, 129, 130, 133, 138, 142, 144, 145, 147, 149–151, 153, 154] |
| Generator | 21 | [24, 41, 53, 54, 58, 63, 77, 84, 98, 105, 108, 110, 112, 116, 117, 123, 129, 130, 144, 150, 154] | ||
| Compiler | 4 | [27, 28, 47, 50] | ||
| Decoder | 1 | [100] | ||
| Diff generator | 1 | [23] | ||
| Evaluation | 10 | Evaluator | 10 | [54, 84, 100, 104, 116, 123, 124, 145, 150, 154] |
| Preprocessing | 6 | Advisor | 2 | [123, 124] |
| Encoder | 2 | [100, 142] | ||
| Type inferencer | 2 | [52, 148] |
5.3.1 生成(Generation)
生成类角色是当前研究中最为广泛探讨的一类,在所有主要研究中共出现73次。其中最基础的角色是优化器(optimizer) ,出现在46项研究中,语言模型直接用于优化已有的低性能代码。而生成器(generator) 的角色则聚焦于根据自然语言规范生成初始代码种子,在21项研究中被使用。此外,还有4项研究尝试让语言模型模拟编译器,通过学习编译器转换策略来生成低级代码;另有研究则使用语言模型生成 差异文件(diff) 表示代码改进,或将编码器语言模型得到的嵌入信息解码为优化后的代码。这些生成类角色通常与多种辅助技术结合使用,以增强其能力,包括:编译器等正确性分析工具、单元测试、静态分析器、代码性能分析工具、长/短期记忆机制,以及检索型知识库等。
5.3.2 评估(Evaluation)
评估器(evaluator)角色在10项研究中被探讨,语言模型被用于评估代码的正确性、性能或质量,定位缺陷、验证输出,并确保其符合规范要求。该角色往往能提供具有解释性的反馈信息。此外,它们常结合单元测试、问题描述等代码上下文信息实现更为准确的判断,亦可与优化器结合,反向传递评估反馈,从而迭代改进代码。虽然基于语言模型的评估器相比传统编译器、静态分析器或人工审查速度更快,但由于其固有的幻觉问题,可能存在准确性与一致性方面的隐患。
5.3.3 预处理(Preprocessing)
语言模型亦在预处理环节中发挥关键作用,在6项研究中得到体现。此类角色包括:
- 顾问(advisor):常用于 agent 流程中,为其他语言模型代理提供决策建议与流程监管;
- 编码器(encoder):从不同的代码上下文中提取隐式表示,用以理解代码语义;
- 类型推断器(type inferencer):通过分析变量命名与结构模式,推断变量类型,而无需程序员显式标注类型。
这些预处理功能为后续的解码、评估或优化任务奠定基础,但通常对计算资源要求较高。 - 发现6: 生成类语言模型在代码优化中扮演最基础角色(共73项研究),且常与多种辅助工具结合使用;评估类模型可提供具有解释性的反馈(10项研究),但其准确性仍受幻觉问题影响;预处理类模型为后续任务提供关键语义支持,但计算成本较高(6项研究)。
- 建议6: 未来研究可考虑融合语言模型的多重角色优势,以更有效地应对复杂的代码优化问题,并结合多种辅助工具以弥补各角色的潜在不足。
6. RQ3:代码优化问题是如何被定义的?
本节旨在探讨在语言模型(LM)应用于代码优化时所涉及的编程语言及性能评估指标。深入理解这些要素对于研究人员与实践者至关重要,有助于其选择合适的技术路径,并根据具体环境定制优化策略,推动代码性能优化领域的进一步发展。
6.1 RQ3.1:研究涉及了哪些编程语言?
我们首先在表5中列出了当前研究中使用语言模型进行优化的编程语言,随后在图8中展示了每项研究所涉及编程语言的数量分布情况。
表 5. 代码优化论文中语言的分布
| Category | Total # | Language | # studies | Reference |
|---|---|---|---|---|
| High-level languages | 53 | Python | 30 | [32, 38, 41, 53, 54, 58, 59, 62, 63, 73, 77, 84, 91, 100, 101, 105, 108, 110, 112, 116–118, 129, 130, 133, 144, 148, 150, 151, 153] |
| C++ | 9 | [23, 38, 91, 98, 104, 110, 119, 145, 149] | ||
| C | 6 | [23, 50, 52, 98, 110, 124] | ||
| Rust | 3 | [110, 116, 150] | ||
| C# | 3 | [39, 40, 110] | ||
| Java | 2 | [24, 91] | ||
| Low-level languages | 6 | LLVM-IR | 4 | [27, 28, 47, 48] |
| Assembly code | 2 | [28, 120] | ||
| Domain-specific languages | 6 | Tensor processing code | 1 | [56] |
| Mapper code | 1 | [138] | ||
| Heuristic code | 1 | [123] | ||
| High-Level Synthesis (HLS) | 1 | [142] | ||
| Register Transfer Level (RTL) | 1 | [147] | ||
| Structured Text (ST) | 1 | [52] |
6.1.1 目标编程语言
从表5可见,大多数研究聚焦于高级语言,共计53项。其中,Python 占据主导地位,出现在30项研究中。由于其广泛应用于数据科学、机器学习和脚本编程等场景,Python 成为代码优化任务的理想候选语言。C++ 和 C 作为底层系统编程的基础语言,分别在9项和6项研究中被关注,因其在性能敏感型应用中的广泛应用而具有较高的优化价值。Rust、C# 和 Java 代表了新兴或企业级的开发语言,也在部分研究中被纳入优化对象,表明其在性能优化方面的需求亦日益增长。
相较之下,仅有6项研究涉及低级语言,其中4项聚焦于 LLVM-IR。这是一种中间表示形式,抽象出简化的程序结构,便于实现编译器级别的优化。另外2项研究关注汇编语言,利用助记符、标签与指令直接操控硬件,从而实现更细粒度的性能调优。研究重心偏向高级语言的一个显著优势是用户基数大、评估基准丰富,便于实验验证;但这也可能导致对低级优化挑战的覆盖不足,限制了针对接近底层硬件语言的优化创新。
此外,还有6项研究探讨了领域特定语言(DSL) 的优化问题,每项研究聚焦于一种特定DSL,如张量处理代码、映射器代码、启发式代码等。这表明语言模型在不同应用领域中的优化潜力广泛。然而,由于DSL研究往往局限于特定场景,其所提出方法的通用性和迁移能力仍需进一步验证。
6.1.2 涉及语言的数量
除了具体语言类型,研究中所涉及语言的数量也是值得关注的维度。如图8所示,大多数研究(81%)仅关注单一编程语言,反映出在多语言环境中推广优化技术面临较大困难,原因包括不同语言在语法、语义及性能特征上的差异。约13%的研究(共7项)同时涉及两种语言,常见的组合包括用途互补或生态互通的语言对,例如 Python 与 C++、C 与 C++、Python 与 Rust、结构化文本(ST)与 C、LLVM-IR 与汇编等。
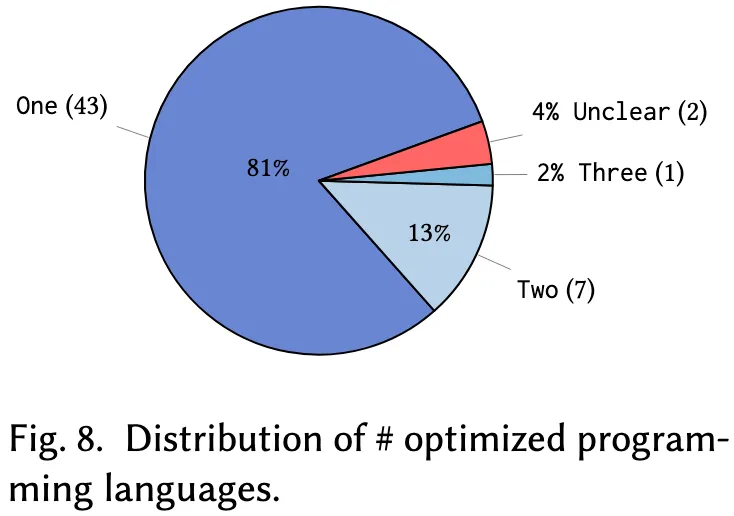
相比之下,仅有一项研究同时处理三种语言,另有两项研究未明确其涉及语言的具体信息。这一分布特征进一步说明,当前基于语言模型的优化研究仍以语言内优化为主,跨语言泛化能力尚有较大发展空间。这些多语言优化技术虽较为罕见,但具有拓展适用范围的潜力。然而,其在不同语言之间实现鲁棒性与准确性平衡方面可能面临挑战。
- 发现7:
- 基于语言模型的代码优化主要集中于高级语言(共53项研究),这得益于其广泛的实际应用基础及丰富的数据资源;
- 单语言研究的高占比(81%)凸显了跨语言泛化难度较大的现实问题。
- 建议7:
- 尽管低级语言与领域特定语言(DSL)仅分别在六项研究中被涉及,它们在各自应用领域中往往承担关键的优化任务,未来研究应给予更多关注;
- 多语言研究数量有限,表明开发跨语言代码优化框架仍具有广阔的发展空间。
6.2 RQ3.2:优化了哪些性能指标?
性能指标是衡量优化技术有效性的基础。因此,本节统计了各项研究中被作为优化目标的性能指标及其数量,详见表6与图9。
表 6.性能优化指标的分布
| Category | Total # | Metric | # studies | Reference |
|---|---|---|---|---|
| Efficiency | 27 | Runtime | 24 | [23, 32, 38, 41, 54, 58, 59, 84, 91, 98, 100, 101, 105, 108, 110, 119, 120, 124, 133, 145, 149–151, 153] |
| Latency | 2 | [104, 142] | ||
| Throughput | 1 | [138] | ||
| General quality | 16 | Code size | 5 | [27, 28, 41, 47, 48] |
| Complexity | 5 | [24, 77, 112, 117, 118] | ||
| Readability | 3 | [52, 77, 118] | ||
| Maintainability | 3 | [52, 77, 118] | ||
| Task-specific | 14 | Task completion rate | 2 | [144, 154] |
| Convergence quality | 2 | [129, 130] | ||
| Synthesis accuracy | 1 | [63] | ||
| Number of instances solved | 1 | [123] | ||
| Success rate | 1 | [53] | ||
| Synthesis performance | 1 | [147] | ||
| Hardware performance | 1 | [56] | ||
| Reference match | 1 | [50] | ||
| Code edit accuracy | 1 | [73] | ||
| Decision-making performance | 1 | [116] | ||
| Driving score | 1 | [62] | ||
| Type inference speed | 1 | [148] | ||
| Resource usage | 9 | Memory usage | 6 | [23, 39, 58, 59, 110, 133] |
| CPU usage | 2 | [39, 40] | ||
| Energy | 1 | [104] |
6.2.1 被优化的性能指标
在所有被优化的性能指标中,与效率相关的指标最为常见,共被提及27次。其中,运行时间(runtime) 是最主要的指标,在24项研究中作为优化目标。这是因为运行时间直接影响用户体验,并且在众多应用场景中,减少执行时间具有普遍意义。延迟(latency) 与吞吐量(throughput) 在对实时性或高性能计算有严格要求的应用中尤为关键,分别在两项和一项研究中被使用。这些结果反映出运行时间作为性能核心指标的重要地位,但也揭示了其他关键效率指标可能被相对忽视的现象。
通用质量指标是被研究频次第二高的类别,共在16项研究中被涉及。具体而言,有5项研究选择优化代码体积,该指标通常以指令数或二进制体积衡量;另有5项研究关注圈复杂度(cyclomatic complexity),该指标用于度量代码中线性无关路径的数量,反映其逻辑复杂性。尽管可读性与可维护性分别仅在3项研究中被提及,但它们对于避免技术债务至关重要,即因历史上采用简单但次优的解决方案而在未来引发的代码维护成本。这些结果表明,研究者已关注到代码长期可用性与开发者体验的重要性,然而,这类质量指标通常更具主观性,且相比效率指标更难量化。
此外,共有14项研究引入任务特定指标,以评估优化代码在特定目标下的表现,涵盖多种任务导向的衡量方式,如任务完成率、收敛质量、程序合成准确率及成功率等,反映出语言模型驱动的代码优化所面向任务的多样性与专业性。例如,有研究致力于优化面向硬件加速器的DSL代码性能,并结合名为 Ansor 的硬件成本模型提供反馈。尽管此类领域特定指标有助于在特定上下文中实现精准评估,其适用范围狭窄也限制了评估结果的可泛化性。
最后,资源使用指标在9项研究中被探讨,其中以内存使用最为常见(6项研究),因为内存资源直接影响程序的可扩展性与实际可部署性,尤其是在资源受限环境下(如嵌入式系统或竞赛编程任务)。CPU 使用率与能耗分别在2项与1项研究中被涉及,虽然关注度相对较低,但在强调硬件效率或可持续性的场景中(如移动设备、高性能计算系统)具有关键意义。这些结果显示,当前研究对代码可持续性与资源效率关注不足,部分原因在于这类指标需要借助专业工具进行性能剖析,难度较高。
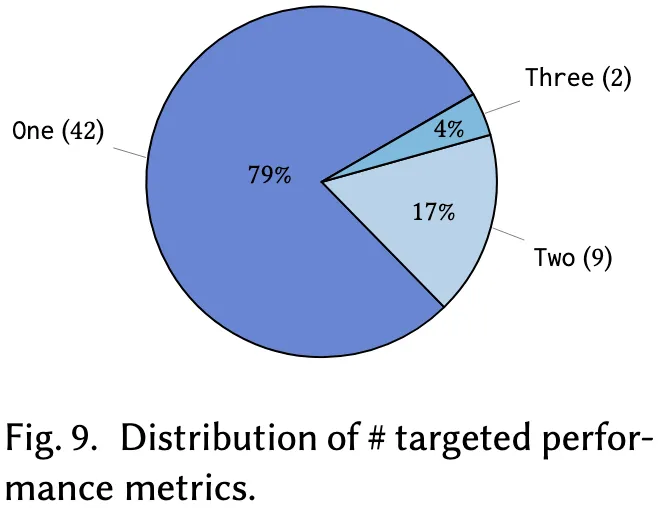
6.2.2 被优化性能指标的数量
图9进一步展示了各研究所涉及的性能指标数量。显著地,大多数研究(共42项,占比79%)仅关注单一性能指标,9项研究(17%)同时优化两个指标,仅有2项研究(4%)尝试同时优化三个指标。这一分布反映出当前研究多聚焦于单一优化目标,但这种方式可能难以全面反映优化方案的整体性能提升。例如,提升运行时间可能导致 CPU 使用率增加,从而带来负面影响。因此,在代码优化中权衡多个指标、协调彼此间潜在冲突显得尤为重要。
- 发现8: 结果显示,当前研究高度集中于单一性能指标优化(占比79%),其中以代码效率类指标最为主流(27项研究),这一趋势凸显了运行时性能在优化任务中的核心地位,同时也反映出不同指标之间存在竞争关系。
- 建议8: 当前对多指标优化的关注较少,未来研究可在此方面深入探索,发展能兼顾多样化性能目标的综合优化技术。
7 RQ4:已有的代码优化方法是如何评估的?
评估方法在代码优化研究中至关重要,它不仅关系到所提方法的可信度和实际可行性,还能揭示其优劣势,进而为后续研究与实际应用中的方法改进提供指导。因此,本章聚焦于现有研究中采用的数据集与基准测试,是否在真实世界数据上进行了评估,以及使用了哪些性能指标。
7.1 RQ4.1:已有研究使用了哪些数据集和基准测试?
本节识别并按照应用领域对所使用的数据集和基准进行了分类。为全面展现各数据集的优势与特征,研究还收集了其来源论文、代码出处、数据集规模、使用语言、性能指标信息与代码仓库链接,详见表7。
表 7. 数据集和基准测试的分布
| Category | Total # | Dataset | Source | Size | Languages | Performance | Repo | Reference |
|---|---|---|---|---|---|---|---|---|
| Competitive programming | 35 | HumanEval [21] | Hand-crafted by experts | 164 programming tasks | Python | Correctness | Link | [41, 58, 59, 77, 105, 116, 153] |
| MBPP [8] | Programming problems | 974 programming tasks | Python | Correctness | Link | [41, 58, 77, 105, 116, 153] | ||
| PIE [119] | CodeNet | 77K slow-fast code pairs | C++ | Runtime | Link | [32, 38, 84, 119] | ||
| LeetcodeHardGym [116] | Leetcode | 40 questions | Python, Rust | Runtime | Link | [116, 150, 154] | ||
| EffiBench [60] | Leetcode | 1K efficiency coding problems | Python | Runtime, memory | Link | [58, 59] | ||
| CodeContests [76] | Aizu, AtCoder | 13,610 samples | Python, C++, Java | Runtime, memory | Link | [110, 117] | ||
| APPS [55] | Coding websites | 10K coding problems | Python | Correctness | Link | [77, 105] | ||
| ECCO [133] | CodeNet | 50K solution pairs | Python | Runtime, memory | Link | [133] | ||
| FunSearch [112] | Algorithmic problems | 10⁶ samples | Python | Complexity, readability, maintainability | Link | [112] | ||
| Supersonic [23] | CodeNet | 314,435 samples | C, C++ | Runtime, memory | Link | [23] | ||
| GEC [99] | CodeForces | 31,577 slow-fast code pairs | Python | Runtime | Link | [100] | ||
| CodeNet [107] | AIZU, AtCoder | 14 million samples | Many | Runtime, memory, code size | Link | [50] | ||
| ACEOB [101] | CodeForces | 95,359 pairs | Python | Runtime | ❌ | [101] | ||
| Effi-Code [59] | Coding datasets | 9,451 tasks | Python | Runtime, memory | Link | [59] | ||
| SAPIE [145] | CodeNet | 77K slow-fast code pairs | C++ | Runtime | ❌ | [145] | ||
| PIE-problem [149] | CodeNet | 18,242 slow-fast code pairs | C++ | Runtime | ❌ | [149] | ||
| DeepDev-PERF [39] | GitHub | 45k repos | C# | CPU, memory | ❌ | [39, 40] | ||
| AnghaBench [30] | GitHub | 1 million samples | C | Runtime, code size | Link | [50] | ||
| InstructCoder [73] | GitHub | 114K I/O triplets | Python | Complexity, readability, maintainability | Link | [73] | ||
| Energy-Language [106] | Repos | 10 problems | 27 languages | Energy, memory, runtime | Link | [104] | ||
| BetterPython [118] | CommitPackFT, CodeAlpaca | 34,139 samples | Python | Complexity, readability, maintainability | Link | [118] | ||
| General SE | 13 | Defects4J [66] | Open-source projects | 17 projects | Java | Complexity | Link | [24] |
| PP4F [68] | HLS | 699 examples | HLS | Latency | Link | [142] | ||
| RewriterBench [147] | Industry cases | 55 cases | RTL | Synthesis performance | Link | [147] | ||
| ST-to-C [52] | Industry cases | 2 case studies | ST, C | Readability, maintainability | ❌ | [52] | ||
| PandasEval [63] | StackOverflow, Hackathon | 89 tasks | Python | Correctness | Link | [63] | ||
| Big Assembly [120] | GitHub | 25,141 functions | x86-64 ASM | CPU-clock cycles | Link | [120] | ||
| CSmith [146] | Synthesis | Unlimited | C | — | Link | [146] | ||
| Compiler | 7 | PolyBench [1] | Benchmarks | 30 kernels | Python, C | Runtime, memory | Link | [56, 91, 148] |
| LLMACCompiler [27] | GitHub, synthesis | 1 million functions | LLVM-IR | Code size | ❌ | [27, 47] | ||
| TSVC [85] | Synthesis | 149 test cases | C | Runtime, code size | Link | [124] | ||
| Priority Sampling [48] | GitHub | 50K functions | LLVM-IR | Code size | ❌ | [48] | ||
| Data science | 2 | Big-DS-1000 [108] | StackOverflow | 1000 problems | Python | Runtime | Link | [108] |
| DS-1000 [70] | StackOverflow | 1000 problems | Python | Correctness | Link | [153] |
7.1.1 竞赛编程类数据集
最常用的数据集类型是面向竞赛编程任务的,共出现35次。此类数据集通常包括问题描述、测试用例、源代码及性能数据。尽管 HumanEval 和 MBPP 等数据集并不专为性能评估设计,但它们在保障优化后代码正确性方面起到了关键作用。此外,PIE、EffiBench 与 CodeContests 等数据集则更侧重于不同语言下的运行时间与内存表现,这些数据集通常构建自大型代码仓库,如 CodeNet、Leetcode 和 Aizu Online Judge。这类数据集因其获取便利性和在受控环境中可重复性强,成为评估优化方法的常用选择,但其往往难以覆盖现实世界程序的复杂性,从而在一定程度上限制了研究结论的可泛化性。
7.1.2 通用软件工程类数据集
第二大类为通用软件工程任务数据集,共13项。这些数据集通常来源于 GitHub、StackOverflow 或行业案例研究。例如,Garg 等人整理的数据集收录了 C# 开发者在 GitHub 开源项目中实际进行的性能优化变更;另一个数据集则包含从开源项目中收集的61万条 C/C++ 手写函数,并以 LLVM-IR 表示;AnghaBench 是一个大型 C 语言样本数据集,含有100万个样本及其运行时与代码体积元数据。通用 SE 数据集的使用反映出当前研究对方法在真实应用场景中有效性的重视。
7.1.3 编译器相关数据集
编译器任务相关数据集在6项研究中被使用,通常包括输入代码、输出代码与优化序列。例如,PolyBench 包含30个用于线性代数、矩阵运算和物理模拟等任务的合成计算内核,被用于3项研究中评估编译器优化的性能;另有一个包含100万个 LLVM-IR 函数的数据集被用于训练与评估 LLaMA-2-7B 模型,以搜索最优的编译器优化序列。
7.1.4 数据科学类数据集
最后,有两项研究使用了数据科学任务中的代码进行模型评估。其中,DS-1000 是一个用于评估 LLM 生成代码在数据科学任务中执行性能的数据集,包含1000个测试用例;Big-DS-1000 在此基础上扩大了测试用例的数据规模(10至1000倍),从而支持对代码优化方法更严格的性能评估。
- 发现9: 当前研究采用了多样化的数据集,体现了代码优化任务在领域、语言与性能指标方面的广泛覆盖。其中,竞赛编程类数据集最为常见(35项),但由于其缺乏对真实程序复杂性的刻画,可能限制研究结论在实际场景中的推广能力。
- 建议9: 在评估优化方法时引入更多样化的数据集,有助于全面理解不同技术在不同环境下的表现优势与局限性。
7.2 RQ4.2:是否在真实世界数据上进行了评估?
为进一步剖析现有代码优化方法的评估方式,本节考察已有研究中有多少使用了真实世界数据进行评估(详见图10),以帮助研究人员和开发实践者认识到现实数据验证的重要性。
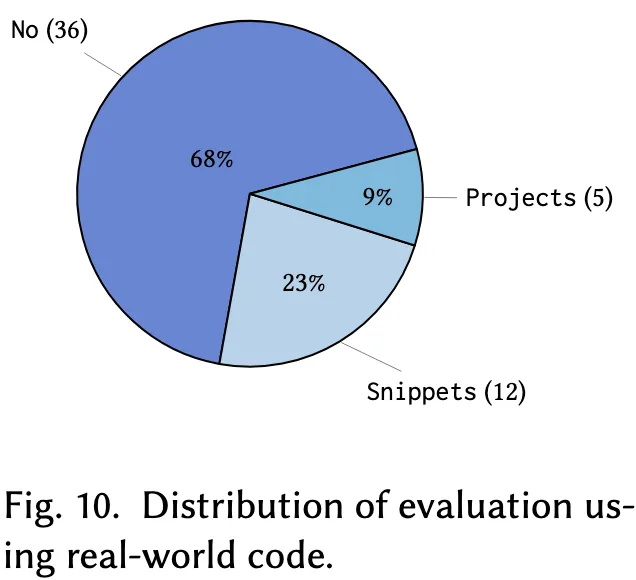
结果显示,大多数研究(共36项,占比68%)并未在复杂的真实软件项目上进行评估,而仅限于竞赛编程代码【如Codeforces、Leetcode】、合成程序,或标准优化算法代码。这一现象表明当前研究对诸如竞赛类或合成数据集有显著偏好,可能由于这些数据集具有良好的可获取性和实验可重复性。然而,这种偏好也暴露出对真实世界验证的明显忽视,而后者对于展示优化方法在复杂真实环境中是否稳健、适用至关重要。在剩余的研究中,约有12项(23%)引入了源自现实应用场景的代码片段,如开源软件仓库、编译器优化任务及数据科学任务。尽管这些片段能在一定程度上提供实际上下文,但它们仍不足以覆盖真实软件工程项目的复杂度与动态性,从而对评估结果的有效性构成潜在威胁。
此外,仅有9%的研究(共5项)直接使用了完整的真实世界项目进行优化方法的评估。例如:
- Choi 等人使用了 Defects4J 数据集,该数据集涵盖开源 Java 项目及其代码缺陷、复杂度和测试用例,旨在推动软件工程研究;
- Garg 等人收集了 GitHub 上45,000个 C# 项目中的性能优化提交,用以评估优化对 CPU 和内存分配等性能指标的影响;
- Han 等人基于三个工业案例研究,展示了大型语言模型如何将结构化文本翻译为具备高可读性和可维护性的 C 代码,满足工业标准。
这一现象表明:当前在使用完整真实项目进行评估方面存在显著空白,主要受限于真实环境下数据收集的困难性(例如数据的动态性、噪声问题等)。因此,为确保优化方法在实际场景中的准确性、可靠性与相关性,**必须加强真实世界验证的力度。
- 发现10: 目前多数研究(68%)未使用真实程序进行代码优化评估,只有9%的研究使用了完整的真实项目,其余仅评估了现实中的代码片段,这突显了现有文献在真实性评估方面的显著不足。
- 建议10: 后续研究应优先将完整的真实项目数据纳入优化技术评估流程中,以确保所提方法具备实际适用性与稳健性,同时重视数据质量与可信度的保障。
7.3 RQ4.3:评估指标有哪些?
评估指标规范了优化技术的评估方式,确保对比具有可比性与可靠性。因此,本节对已有研究中使用的评估指标进行梳理,并根据图11将其划分为三类,旨在帮助读者根据具体需求选择最合适且有效的优化技术。
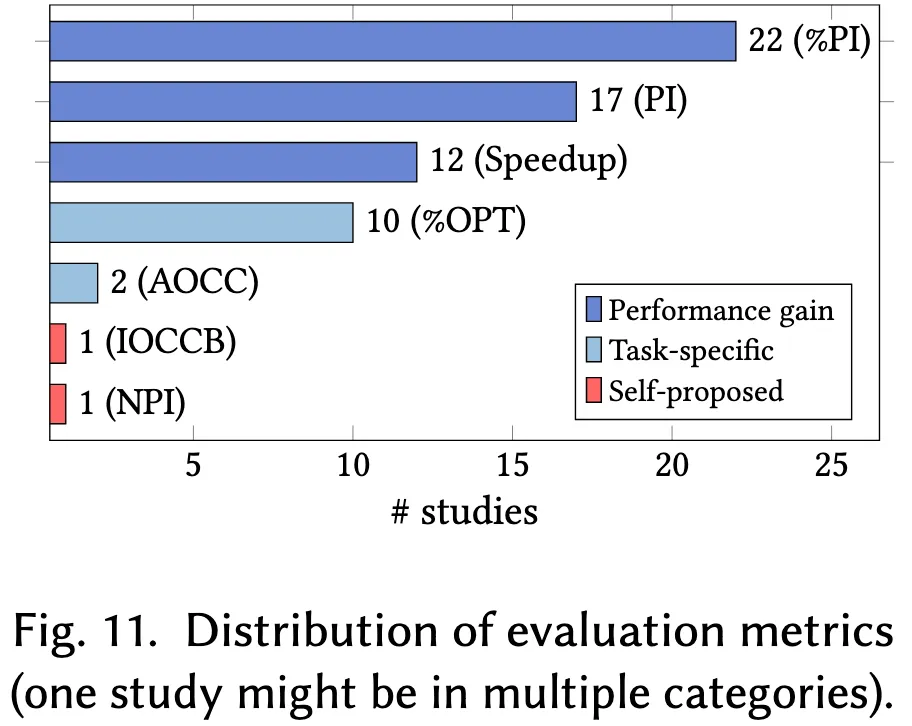
7.3.1 性能增益类指标
共有51项评估指标属于性能增益类,其中22项研究采用了百分比性能提升(%PI)指标,该指标通过优化前后性能差值与优化前性能的比值计算得出,便于不同测试用例与性能指标之间的对比。另有17项研究使用了性能提升(PI)指标,即优化前后性能指标的绝对差值,能够直接展示性能提升的幅度。此外,12项研究采用了加速比(SP)指标,定义为优化前性能与优化后性能的比值,用于衡量性能提升的倍数。总体而言,此类指标适用于宏观层面的对比分析,但可能在刻画性能特性复杂性方面存在一定简化。
7.3.2 任务特定指标
鉴于代码优化目标的多样性,共有12项研究采用了任务特定的评估指标。具体而言,10项研究通过优化程序比例(%OPT)评估语言模型的优化能力,该指标表示被成功优化的代码片段在所有测试样本中的占比。另有两项研究使用收敛曲线下面积(AOCC)来评估优化算法收敛至最优或近最优解的速度与效率。相较于通用性能增益指标,此类指标能够更有针对性地反映特定任务下的优化挑战与成效。
7.3.3 自定义指标
此外,Pan等人设计了两项用于特定研究目标的定制化评估指标。其一为同构最优比较CodeBLEU(IOCCB),用于评估语言模型生成的优化代码与理想优化版本之间的相似性,体现模型达成最优或近最优解的能力;其二为归一化性能指数(NPI),衡量在实现相同功能的代码中,目标代码执行时间相对于最优与最劣代码的相对性能表现,从而反映代码的相对效率。
- 研究发现11:性能增益类指标(如%PI、PI和SP)在优化有效性评估中被广泛采用(共51例);任务特定指标(如%OPT和AOCC)则可提供针对具体任务的深入洞察(共12例);自定义指标在满足特定研究需求方面展现出独特优势(共2项研究)。
- 建议11:
- 综合运用不同类型的评估指标对于全面评估代码优化技术至关重要
- 研究者可探索并采用更具表达力的新型指标,以更好地刻画优化问题与方案的多维特征。
8 挑战与未来方向
尽管近年来基于语言模型(LM)的代码优化技术取得了迅猛发展,但本调研结果揭示出若干关键的知识空白仍未被充分填补。本节将系统地梳理这些亟待解决的挑战,并提出若干值得探索的未来研究方向。
8.1 挑战一:模型复杂度与实用性的平衡
如第4.1节所述,当前语言模型的规模持续扩大,2024年提出的主流GPT-4模型参数量已达到约1.8万亿。这一“更大更复杂”的发展趋势虽然提升了模型的代码生成与优化能力,但也带来了对计算资源的巨大依赖,严重制约了其在实际代码优化场景中的应用。同时,随着现代软件系统在规模和复杂性上的持续增长,基于LM的代码优化方法亟需具备处理大规模代码库的能力。因此,如何在模型能力与实用性、成本之间寻求合理权衡,仍是当前的重要研究难题。
8.1.1 未来研究方向
模型压缩:已有研究表明,模型压缩可在性能几乎不受影响的前提下显著降低模型体积。Zhu等人综述了当前主流压缩技术,包括剪枝冗余参数、权重量化、以及通过知识蒸馏训练小模型(学生模型)以逼近大模型(教师模型)的行为,从而在模型复杂度与实用性之间取得平衡。例如,Sun等人提出了Wanda方法,根据权重的幅值及其对应的输入激活进行剪枝,在提高效率的同时仍保持良好的性能表现。然而,压缩过程可能导致关键参数的丢失,进而影响模型理解复杂代码语义和执行精细优化的能力。因此,未来研究应深入探讨压缩策略对模型行为及其在代码优化任务中表现的具体影响。
小模型集成:集成技术通过组合多个小型语言模型以协同完成任务,旨在在保持模块化与灵活性的同时,整体性能接近甚至匹敌单一大型模型。Chen与Varoquaux对小模型在工程实践中的优势、挑战与应用进行了深入综述,指出通过集成框架可有效克服单模型的性能瓶颈。Lu等人也调研了当前在模型融合、集成协作等方向上的进展,表明此类方法可提升模型的效率、适应性及优化能力。然而,小模型集成在部署与管理方面的复杂性,可能会抵消其在计算资源上的节约。因此,如何提升模型间协作的有效性与知识共享机制,是后续研究需要重点解决的问题,以避免重复计算和效率低下。
8.2 挑战二:与外部系统交互能力的局限
如第5.1节所述,目前多数基于LM的代码优化方法仍运行于封闭计算环境中,远不及人类程序员那样能够灵活调用互联网资源、借助外部代码分析工具,或与他人协作以完成最优代码修改。虽然已有研究尝试通过上下文提示、反馈机制或初步代理方法等手段加以缓解(详见第5.2节),但这些方法在与外部系统的交互能力上仍极为有限,难以实现与专家知识库、预测模型、集成开发环境(IDEs)等工具的无缝整合,导致优化效果受限。因此,亟需增强语言模型的外部交互能力,使其在真实软件开发场景中更接近人类程序员的工作方式。
8.2.1 未来研究方向
代理型语言模型(Agentic LMs):代理型LM通过引入具备感知外部资源与工具、参与多智能体系统与人机交互等能力的模块,扩展了传统LM的功能边界,使其更适用于处理如代码优化等复杂任务。已有研究表明,此类模型能够胜任许多端到端的软件工程任务,单一LM难以胜任的工作可以通过代理系统协同完成。此外,多代理协作机制也使得模型能够利用专业化资源,进一步提升编码任务的效率与效果。然而,系统集成的复杂性带来了更高的计算资源消耗,尤其是在大规模应用场景下。同时,关于系统鲁棒性、安全性与公平性的研究仍相对滞后,未来亟需系统性研究以应对这些潜在风险并确保代理型LM的可靠应用。
8.3 挑战三:在编程语言与性能指标之间的通用性不足
为了实现代码优化技术的广泛适用性,其必须具备良好的跨语言与跨性能指标的泛化能力。然而,不同编程语言在语法、语义以及性能特征上的差异会显著阻碍优化策略的迁移与复用。因此,目前尚存在一个明显的研究空白,即如何在不同编程语言与性能指标之间有效应用已有的优化策略。如第6.1节与第6.2节所示,分别有81%与79%的研究仅聚焦于单一语言或单一性能指标的优化。
8.3.1 未来研究方向
面向代码优化的跨语言模型:已有研究训练了多语言数据集上的模型(如PolyCoder),以提升其在不同编程语言间的泛化能力。然而,此类模型主要面向通用代码生成任务,缺乏在代码性能优化方面的专门设计。未来研究可进一步扩展这些模型,使其能够学习在不同编程语言中通用的优化模式,处理语法与语义上的变异性,从而提高优化策略的可迁移性与适应性。
多目标代码优化:多目标优化框架(如NSGA-II)已在演化算法与通用优化任务中取得显著成效,但在代码优化领域的应用仍十分有限。这主要由于多个性能指标(如运行效率、内存使用、能耗等)之间常存在冲突,难以实现统一的优化目标。因此,未来研究需重点关注多性能指标之间的权衡关系,推动基于LM的代码优化方法向平衡化、多维度的方向发展。
8.4 挑战四:对真实世界代码的评估不足
如第7.2节所示,仅有32%的研究在真实世界数据上验证其代码优化方法,表明当前语言模型在理论优化能力与实际应用之间存在显著鸿沟。相比于竞赛类编程题目或合成数据集,真实代码库通常包含结构复杂、文档缺失或遗留系统相关的代码内容,这类高复杂度语境易导致基于LM的优化技术性能显著下降。因此,如何缩小理论方法与实际场景之间的差距,是未来推动LM在工业级代码优化与软件开发中落地的关键。
8.4.1 未来研究方向
建立标准化的真实世界基准集:构建标准化且公开可用的真实代码库基准是未来的重要方向之一。如表7所示,尽管已有10个数据集关注通用软件工程代码优化任务,但其中四个并非开源,其余也多局限于单一语言或特定领域,限制了其通用性与代表性。因此,后续研究应构建涵盖多样化与复杂性特征的工业级代码基准,涵盖遗留系统与低文档环境等实际问题场景,并引入可衡量优化结果全面性的指标,如可扩展性、兼容性、效率与可维护性等,以评估方法在真实约束条件下的实用性。
实现上下文感知的优化:上下文感知优化旨在结合多模态输入(如文档、代码注释与版本历史)来更精准地调整优化策略,或通过引入代理机制使语言模型能与外部环境动态交互,从而迭代地深化对代码的理解。然而,将这些复杂模块与现有LM架构高效集成,仍是一项技术挑战,亟需系统性的方法和架构创新来解决。
8.5 挑战五:AI驱动的代码优化中的可信性与可靠性问题
正如相关研究所揭示的那样,语言模型(LM)本质上存在输出随机、不一致,甚至产生虚构结果的倾向,这在真实软件系统中可能降低其生成优化代码的可信度与可靠性。因此,人类专业知识在验证、解释与完善LM建议中仍不可或缺。事实上,已有研究表明,将人类监督与AI能力相结合可以产生互补协同效应:人类开发者提供领域知识与批判性判断,而AI则贡献计算效率与预测洞察力。最终,实现人类开发者与语言模型之间的高效协作,是达成优质代码优化结果的关键。
8.5.1 未来研究方向
基于人类反馈的强化学习(RLHF):现有的代码优化方法已通过偏好引导的优化方式融入人类经验,即通过微调使模型输出更符合人类偏好。在此基础上,RLHF框架进一步将人类反馈作为动态奖励信号,引导语言模型执行特定优化任务。然而,人类提供的反馈信息可能引入不一致性或文化偏见,影响模型输出的公平性与中立性,这些问题应在未来研究中予以充分考虑。
9 结论
本文系统性地回顾了语言模型(LM)在代码优化领域的应用,综合分析了50余篇近期高质量研究成果。尽管无法穷尽所有相关文献,我们力图对主要研究方向与未来发展趋势进行全面且易于理解的梳理。具体而言,我们识别出当前阻碍该领域发展的五项关键知识空白,包括模型复杂度与实用性之间的权衡、以及提升AI驱动优化方案通用性与可信度的迫切需求。填补这些空白有赖于更有效的技术方法与标准化评估基准的建立。
通过描绘语言模型在代码优化领域的演进图景,本综述为克服当前限制、推动AI驱动的软件开发提供了研究路线图。值得强调的是,语言模型与深度学习技术并非解决软件工程与代码优化全部挑战的“万能钥匙”。语言模型的能力受其所接收数据的固有限制,因此具备特定边界。与其担忧此类技术将削弱软件工程师的角色,不如视其为激发创造力、拓展研究边界的新契机。