Useful Linux Commands & Tools
实用linux命令和工具
给你一台新的服务器,你会做什么?
高级linux使用指南——for smooth use
- ①装高级指令
sudo apt get install -y htop bat ncdu fd-find exa fzf ripgrep parallel - ②修改vim编辑器配置
vim ~/.vimrc然后写入set hlsearch set incsearch - ③下载
zsh然后使用万能的oh-my-zsh:
htop
htop是Linux系统中的一个互动的进程查看器,与Linux传统的top比较的话,htop更人性化并且还支持鼠标操作!
(1) 在htop中,可以垂直和水平滚动列表,查看所有进程和完整的命令行。
(2) 在top中,您按下的每个未分配的键都有延迟(尤其是当多键转义序列意外触发时)。
(3) htop启动得更快(top似乎在显示任何东西之前会收集一段时间的数据)。
(4) 在htop中,您不需要输入进程号来终止进程,而在top中,您需要这样做。
(5) 在htop中,您不需要输入进程编号或优先级值来重新分配进程,而在top中,您需要这样做。
(6) 在htop中,您可以同时杀死多个进程。
(7) top更老,因此更容易测试。
CPU Usage

- (1)蓝色的表示low-prority(低优先级)使用
- (2)绿色的表示normal(标准)使用情况
- (3)红色的表示kernel(内核)使用情况
- (4)青色的表示virtuality(虚拟性)使用情况
Memory Bar

- (1)绿色的表示已经使用内存情况
- (2)蓝色的表示用于缓冲的内存使用情况
- (3)黄色的表示用于缓存的内存使用情况
- 当你发现你的
交换分区(swap)已经派上用场的时候,说明你的物理内存已经不足,需要考虑增加内存了。
%%缓冲::是一种用于临时存储数据的技术,主要用于解决数据生产与消费速率不一致的问题。%%
整体状态区域

- (1)Tasks显示进程总数,当前运行的进程数
- (2)Load average显示的是系统的1分钟,5分钟,10分钟的平均负载情况
- (3)Uptime显示系统运行了多长时间
进程状态区域
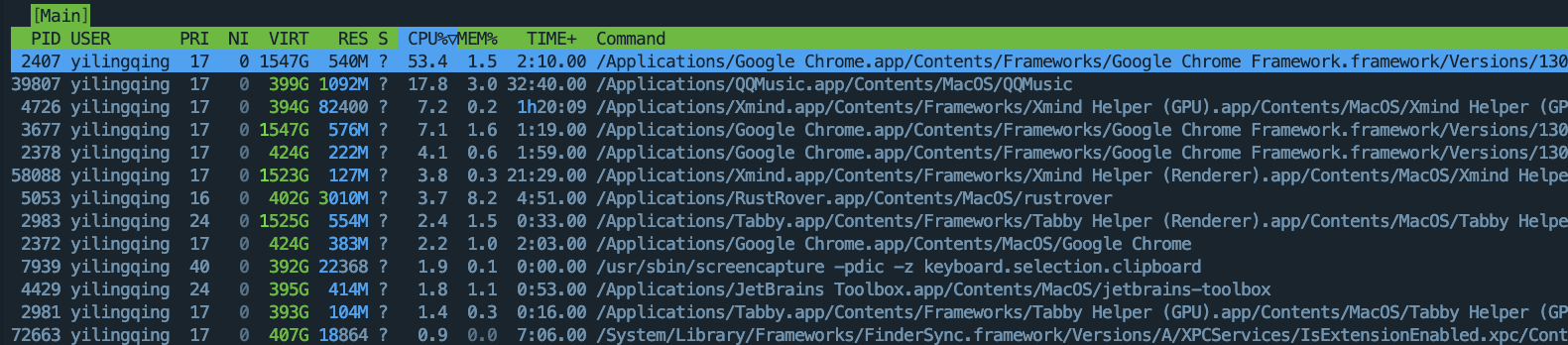
PID:表示进程号,是非零正整数
USER:发起该进程的用户名
PRI:进程优先级
NI:(nice)进程的优先级别数值
VIRT:进程占用的虚拟内存
RES:进程占用的物理内存
SHR:进程使用的共享内存
S:进程的运行状况(1) R 表示正在运行
(2) S 表示休眠
(3) Z 表示僵死状态
(4) N 表示该进程优先值是负数CPU%:进程占用的CPU使用率
MEM%:此进程占用的物理内存和总内存的百分比
TIME%:启动进程后占用CPU的累计时长
Command:进程启动的启动命令名称即路径
为什么一个进程虚拟内存可能高达几百G?
控制台
- F1;查看htop说明
- F2;htop设定
- F3;搜索进程
- F4;进程过滤器
- F5;显示属性结构
- F6;折叠或展开(新版本里的),或选择排序方式(旧版本里的)
- F7; 减少nice值,提高进程优先级
- F8; 增加nice值,降低进程优先级
- F9; 可对进程传递信号
- F10; 退出
命令行
- -d:设置刷新时间,单位为秒;
- -C:设置界面为无颜色;
- -u:显示指定用户的进程;
- -s:以指定的列排序;
free
free 命令显示系统内存的使用情况,包括物理内存、交换内存(swap)和内核缓冲区内存。
# -h(human-readable)要求不以字节数以M、G等显示,-s刷新时间
free -h -s 3free命令输出来源于/proc/meminfo,其输出为:

- Mem 行(第二行)是内存的使用情况。
- Swap 行(第三行)是交换空间的使用情况。
- total 列显示系统总的可用物理内存和交换空间大小。
- used 列显示已经被使用的物理内存和交换空间。
- free 列显示还有多少物理内存和交换空间可用使用。
- shared 列显示被共享使用的物理内存大小。
- buff/cache 列显示被 buffer 和 cache 使用的物理内存大小。
- available 列显示还可以被应用程序使用的物理内存大小。
其中free 是真正尚未被使用的物理内存数量。至于 available 是从应用程序的角度看到的可用内存数量。Linux 内核为了提升磁盘操作的性能,会消耗一部分内存去缓存磁盘数据,就是我们介绍的 buffer 和 cache。所以对于内核来说,buffer 和 cache 都属于已经被使用的内存。当应用程序需要内存时,如果没有足够的 free 内存可以用,内核就会从 buffer 和 cache 中回收内存来满足应用程序的请求。所以从应用程序的角度来说,available = free + buffer + cache。请注意,这只是一个很理想的计算方式,实际中的数据往往有较大的误差。
swap space 是磁盘上的一块区域,可以是一个分区,也可以是一个文件。所以具体的实现可以是 swap 分区也可以是 swap 文件。当系统物理内存吃紧时,Linux 会将内存中不常访问的数据保存到 swap 上,这样系统就有更多的物理内存为各个进程服务,而当系统需要访问 swap 上存储的内容时,再将 swap 上的数据加载到内存中,这就是常说的换出和换入。交换空间可以在一定程度上缓解内存不足的情况,但是它需要读写磁盘数据,所以性能不是很高。
现在的机器一般都不太缺内存,如果系统默认还是使用了 swap 是不是会拖累系统的性能?理论上是的,但实际上可能性并不是很大。并且内核提供了一个叫做 swappiness 的参数,用于配置需要将内存中不常用的数据移到 swap 中去的紧迫程度。这个参数的取值范围是 0~100,0 告诉内核尽可能的不要将内存数据移到 swap 中,也即只有在迫不得已的情况下才这么做,而 100 告诉内核只要有可能,尽量的将内存中不常访问的数据移到 swap 中。在 ubuntu 系统中,swappiness 的默认值是 60。如果我们觉着内存充足,可以在 /etc/sysctl.conf 文件中设置 swappiness:
vm.swappiness=10什么是buff/cache::buffer 在操作系统中指 buffer cache, 中文一般翻译为 “缓冲区”。要理解缓冲区,必须明确另外两个概念:“扇区” 和 “块”。扇区是设备的最小寻址单元,也叫 “硬扇区” 或 “设备块”。块是操作系统中文件系统的最小寻址单元,也叫 “文件块” 或 “I/O 块”。每个块包含一个或多个扇区,但大小不能超过一个页面,所以一个页可以容纳一个或多个内存中的块。当一个块被调入内存时,它要存储在一个缓冲区中。每个缓冲区与一个块对应,它相当于是磁盘块在内存中的表示。buffer cache 只有块的概念而没有文件的概念,它只是把磁盘上的块直接搬到内存中而不关心块中究竟存放的是什么格式的文件。cache 在操作系统中指 page cache,中文一般翻译为 “页高速缓存”。页高速缓存是内核实现的磁盘缓存。它主要用来减少对磁盘的 I/O 操作。具体地讲,是通过把磁盘中的数据缓存到物理内存中,把对磁盘的访问变为对物理内存的访问。页高速缓存缓存的是内存页面。缓存中的页来自对普通文件、块设备文件(这个指的就是 buffer cache 呀)和内存映射文件的读写。
kill
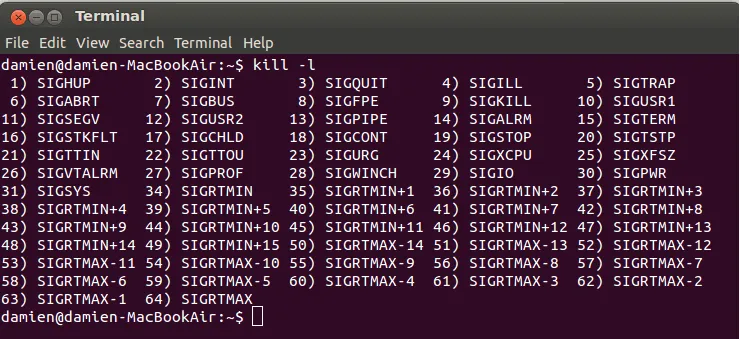
基本用法:kill [options] pid(s),可以同时杀死多个进程
| -l | 列出所有可能的信号 |
|---|---|
| signal | 终止指定的信号 |
| pid | 进程号 |
常用:
- SIGTERM - 此信号==请求==一个进程停止运行。此信号是可以被忽略的。进程可以用一段时间来正常关闭,一个程序的正常关闭一般需要一段时间来保存进度并释放资源。换句话说,它不是强制停止。(kill -15)
- SIGKILL - 此信号==强制进程立刻停止运行。程序不能忽略此信号,而未保存的进度将会丢失==。(kill -9)
可以使用ps -ef或ps uf列出当前进程。
pkill
kill的扩展,允许以进程名杀死进程,如pkill firefox。还可以使用正则表达式匹配,如pkill fire。但是为了避免有错误正则一起杀死的事,可以使用pgrep -l chro先匹配名称。
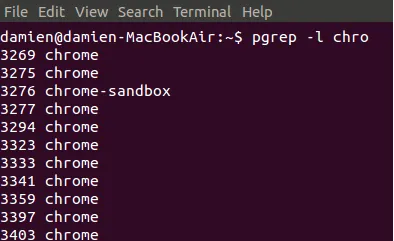
killall
使用方法同pkill
strace
strace 是 Linux 系统中的一个调试工具,用于跟踪系统调用(system calls)和信号(signals)的执行情况。它能够截取和记录一个进程执行期间所调用的所有系统调用及其返回结果,因此它特别适合用于调试、分析程序执行过程中的问题,或理解程序与内核的交互。
场景
- 在操作系统运维中会出现程序或系统命令运行失败,通过报错和日志无法定位问题根因。
- 如何在没有内核或程序代码的情况下查看系统调用的过程。
- strace是有用的诊断,说明和调试工具,Linux系统管理员可以在不需要源代码的情况下即可跟踪系统的调用。
- strace显示有关进程的系统调用的信息,这可以帮助确定一个程序使用的哪个函数,当然在系统出现问题时可以使用 strace定位系统调用过程中失败的原因,这是定位系统问题的很好的方法
-c 统计每一系统调用的时间、调用次数和错误等信息
-f 跟踪由fork调用所产生的子进程
-p 跟踪指定的进程ID
-e trace=系统调用 只跟踪指定的系统调用
-o 文件名 将strace的输出写入指定的文件中
-t 在输出的每一行前加上时间信息
-s strsize 指定输出的字符串最大长度
-v 输出更详细的信息
-tt 显示系统调用的时间KVM::KVM 全称为 Kernel-based Virtual Machine,是 Linux 内核中的一种虚拟化技术,它将 Linux 内核转变为一个 Type-1 Hypervisor(硬件虚拟化层),从而支持在虚拟机中运行多个独立的操作系统实例。
Fork::Fork 是 Unix 和 Linux 操作系统中用于创建进程的系统调用。fork() 调用用于在运行中的进程中创建一个新的子进程,这个子进程是父进程的副本。
grep
grep 是 Linux 和类 Unix 系统中的一个非常常用的命令行工具,主要用于在文件或文本中搜索符合指定模式的行。它支持正则表达式,能够快速高效地查找、筛选和显示匹配的文本行。全称:Global Regular Expression Print
-a --text # 不要忽略二进制数据。
-A <显示行数> --after-context=<显示行数> # 除了显示符合范本样式的那一行之外,并显示该行之后的内容。
-b --byte-offset # 在显示符合范本样式的那一行之外,并显示该行之前的内容。
-B<显示行数> --before-context=<显示行数> # 除了显示符合样式的那一行之外,并显示该行之前的内容。
-c --count # 计算符合范本样式的列数。
-C<显示行数> --context=<显示行数>或-<显示行数> # 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作> --directories=<动作> # 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e<范本样式> --regexp=<范本样式> # 指定字符串作为查找文件内容的范本样式。
-E --extended-regexp # 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
-f<范本文件> --file=<规则文件> # 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F --fixed-regexp # 将范本样式视为固定字符串的列表。
-G --basic-regexp # 将范本样式视为普通的表示法来使用。
-h --no-filename # 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H --with-filename # 在显示符合范本样式的那一列之前,标示该列的文件名称。
-i --ignore-case # 忽略字符大小写的差别。
-l --file-with-matches # 列出文件内容符合指定的范本样式的文件名称。
-L --files-without-match # 列出文件内容不符合指定的范本样式的文件名称。
-n --line-number # 在显示符合范本样式的那一列之前,标示出该列的编号。
-P --perl-regexp # PATTERN 是一个 Perl 正则表达式
-q --quiet或--silent # 不显示任何信息。
-R/-r --recursive # 此参数的效果和指定“-d recurse”参数相同。
-s --no-messages # 不显示错误信息。
-v --revert-match # 反转查找。
-V --version # 显示版本信息。
-w --word-regexp # 只显示全字符合的列。
-x --line-regexp # 只显示全列符合的列。
-o # 只输出文件中匹配到的部分。
-m <num> --max-count=<num> # 找到num行结果后停止查找,用来限制匹配行数规则表达式:
^ # 锚定行的开始 如:'^grep'匹配所有以grep开头的行。
$ # 锚定行的结束 如:'grep$' 匹配所有以grep结尾的行。
. # 匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
* # 匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。
.* # 一起用代表任意字符。
[] # 匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] # 匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
(..) # 标记匹配字符,如'(love)',love被标记为1。
< # 锚定单词的开始,如:'<grep'匹配包含以grep开头的单词的行。
> # 锚定单词的结束,如'grep>'匹配包含以grep结尾的单词的行。
x{m} # 重复字符x,m次,如:'0{5}'匹配包含5个o的行。
x{m,} # 重复字符x,至少m次,如:'o{5,}'匹配至少有5个o的行。
x{m,n} # 重复字符x,至少m次,不多于n次,如:'o{5,10}'匹配5--10个o的行。
\w # 匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
\W # \w的反置形式,匹配一个或多个非单词字符,如点号句号等。
\b # 单词锁定符,如: '\bgrep\b'只匹配grep。 实例:
grep "match_pattern" file_1 file_2 file_3 ...:在多个文件中查找grep -v "match_pattern" file_1 file_2 file_3 ...:反向查找没有模式的内容grep -rin:最常用的,查找当前文件夹所有文件,忽略大小写,注明行号grep -E "[1-9]+":使用“扩展正则表达式”,或者egrepgrep -c "模式" file或者grep -cr "模式":用来统计出现的次数grep -e "is" -e "line" -o:匹配多个模式grep "5" -A 3:打印匹配到5后的三行内容 (-B为前面,-C是上下文3行)
crontab
用于设置周期性被执行的指令。该命令从标准输入设备读取指令,并将其存放于“crontab”文件中,以供之后读取和执行。该词来源于希腊语 chronos(χρ?νο?),原意是时间。通常,crontab储存的指令被守护进程激活, crond常常在后台运行,每一分钟检查是否有预定的作业需要执行。这类作业一般称为cron jobs。当安装完成操作系统之后,默认便会启动此任务调度命令。crond 命令每分锺会定期检查是否有要执行的工作,如果有要执行的工作便会自动执行该工作。注意:新创建的 cron 任务,不会马上执行,至少要过 2 分钟后才可以,当然你可以重启 cron 来马上执行。
crontab -l:查看任务列表crontab -r:删除当前用户的 crontab 文件(即删除所有定时任务)。crontab -i:删除 crontab 文件之前确认。
crontab格式如下:
* * * * * command_to_be_executed
- - - - -
| | | | |
| | | | +----- 星期几 (0 - 7) (周日 = 0 或 7)
| | | +---------- 月份 (1 - 12)
| | +--------------- 日期 (1 - 31)
| +-------------------- 小时 (0 - 23)
+------------------------- 分钟 (0 - 59)0 0 * * * cd /Users/yilingqinghan/Documents/BaiduPan/专著/aisystem-doc && /usr/bin/git pull >> /Users/yilingqinghan/Documents/BaiduPan/专著/aisystem-doc/git_pull.log 2>&1:每日凌晨自动更新git仓库
ulimit
ulimit 是 Linux 和 Unix 系统中的一个内置命令,用于控制 shell 会话中可用的系统资源限制。通过 ulimit 命令,你可以查看或设置用户进程所能使用的资源上限,如 CPU 时间、文件大小、堆栈大小、打开文件数等。这在系统管理和调试中非常有用,可以防止单个进程占用过多的资源而影响系统的稳定性。
ulimit是临时性的修改,只对当前窗口有效,/etc/security/limits.conf可以做到永久更改。
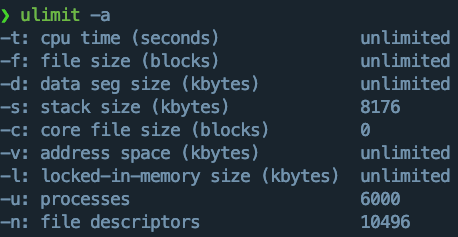
通过 ulimit,你可以设置某个特定资源的限制,通常可以设置为一个具体的值或 unlimited,表示不限制。以下是一些常见的资源限制选项:
- -c:核心文件(core file)大小,单位是块。
- -d:数据段大小,单位是 KB。
- -f:最大文件大小,单位是块。
- -m:内存大小,单位是 KB。
- -n:最大打开文件数。
- -s:堆栈大小,单位是 KB。(比较常用)
- -t:最大 CPU 时间,单位是秒。(限制一个进程在CPU上的时间)
- -v:虚拟内存大小,单位是 KB。
- -u:用户可以创建的最大进程数。
ulimit -s unlimited:取消栈大小限制
taskset
在Linux系统中,taskset 命令用于查询或设置进程(线程)与CPU的绑定关系,也就是设置进程的CPU亲和性。CPU亲和性是指进程在系统中运行时,被绑定在特定的CPU核心上,Linux调度器会遵守这一设定,进程将不会在其他CPU上运行。
线程是最小的内核执行调度单元,因此,准确地说是将某个线程与某个CPU核心绑定,而非某个进程。
- 查询线程(PID(TID)=2857115)的线程可用的CPU核心

- 以掩码形式表示(32位为1,即0-31都可用)

❯ taskset -p 2857115
pid 2857115 的当前亲和力掩码:ffffffff- 使用列表形式指定线程可用核心:taskset -pc 0,3,7-11 300
ncdu(df的高级版)
(NCurses Disk Usage)一个基于文本的磁盘使用率查看器,用于分析和查找使用空间最大的文件和文件夹。它比传统的 du 命令可视化效果更好,操作更直观。
- 使用方法:
ncdu 目录 - 在可视化界面中利用↑、↓和回车进行访问
xargs
xargs 是 Linux 中一个非常有用的命令,主要用于将输入的数据列表转换为另一条命令的参数,从而实现批量操作。它特别适合处理输入较长或需要逐项处理的情况。xargs 通常与其他命令(如 find、grep、cat)组合使用,从标准输入或管道中读取数据,然后按需生成和执行其他命令。
- -n num 每次传递 num 个参数给命令。
- -L num 每次读取 num 行输入作为参数。
- -d char 使用指定字符作为分隔符,通常用于自定义分隔符。
- -0 使用空字符(\0)作为分隔符,适合处理包含空格的文件名(常与 find -print0 一起使用)。
- -p 执行前提示用户确认。
- -I {} 将 {} 作为占位符,将每个输入逐项替换 {} 并执行命令。
- -t 显示命令执行的详细信息,打印每次执行的完整命令。
实例
https://ruanyifeng.com/blog/2019/08/xargs-tutorial.html
cat files.txt | xargs -I {} mv {} /backup/directory/:这里的 {} 是占位符,表示每个文件名会被逐个替换到 {} 位置,mv 命令会把每个文件移动到 /backup/directory/find . -name "*.txt" | xargs -I {} gzip {}:每个 .txt 文件都会作为参数传递给 gzip,完成压缩echo "one two three" | xargs mkdir:创建三个文件夹,注意mkdir本身不支持创建多个文件夹,所以必须采用此方式
rename
rename 命令用于批量修改文件或目录的名称,尤其在 Linux 和 macOS 系统上很有用。不同系统上 rename 的实现有所不同,常见的有两种版本:
- Perl 版本 (rename):通过 Perl 正则表达式匹配模式替换文件名,广泛应用于 Debian、Ubuntu 等系统。
- Util-linux 版本 (rename.ul):支持简单的字符串替换,不使用正则表达式,适用于 CentOS 和 RHEL 等系统。
#1. Perl 版本的 rename 命令
rename 's/旧模式/新模式/' 文件或目录列表
示例:
rename 's/\.txt$/.bak/' *.txtrename 's/^/prefix_/' *: 在文件名前添加前缀rename 'y/A-Z/a-z/' *: 批量转换文件名为小写rename 's/\s+/_/g' *: 删除文件名中的空格
#2. Util-linux 版本的 rename 命令 (rename.ul)
rename.ul .txt .bak *.txt: 将扩展名 .txt 改为 .bakfor file in *; do rename.ul "$file" "prefix_$file"; done: 在文件名前添加前缀(需要逐个添加)
不支持正则表达式匹配
bat(cat高级版)
bat 是 cat 的克隆,但它具有一些现代特征。其 GitHub 页面上的标语是“有翅膀的猫克隆(a cat clone with wings.)”。在Linux中,bat是一个更好看的cat替代品,它在显示文件内容时支持语法高亮、行号和分页等功能,常用于查看代码或配置文件的内容。
基本用法:bat [选项] 文件名
bat file1.txt file2.txt: 可以查看多个文件的内容bat -n example.txt: 显示行号bat -p example.txt: 显示纯文本,禁用语法高亮和行号bat -l python example_script: 手动指定语法高亮语言bat --list-languages: 显示支持的语言列表bat --theme="Nord" example.txt: 选择不同的高亮主题
fd(find高级版)
安装方法:apt install fd-find -y,基本语法如下所示:
fd [选项] [模式] [路径]- -H – 在搜索结果中包含隐藏文件和目录。
- -I – 显示将被 .gitignore、.ignore 或 .fdignore 文件忽略的搜索结果。
- -s – 执行区分大小写的搜索。
- -i – 执行不区分大小写的搜索。(ignore)
- -a – 显示绝对路径而不是相对路径。
- -L – 遵循符号链接。
- -j – 用于定义用于搜索的线程数。
用法示例: fd -H: 显示当前所有文件和隐藏文件fd -p ~/Desktop: 显示指定目录所有文件fd -F myfile: 查找字符串匹配的文件fd -e png: 按扩展名查找文件fd -tx: 显示所有可执行文件fd -S +50k,fd -S -50k: 按文件大小显示文件
exa(ls高级版)
exa 是一个命令行工具,可以列出指定路径(如未指定则是当前目录)的目录和文件。这也许听起来很熟悉,因为这就是 ls 命令所做的事情。exa 被视作从 UNIX 旧时代延续至今的古老的 ls 命令的一个现代替代品。如其所声称的那样,它有比 ls 命令更多的功能、更好的默认行为。
用法:
exa -ls: 同ls -lexa -ls --git: 附加显示Git信息exa -abghHliS: 所有选项exa --tree: 显示树形结构
最新版已经扩展为
eza
fzf
fzf是一款使用 GO 语言编写的交互式的 Unix 命令行工具。可以用来查找任何 列表内容、文件、历史命令、 本机绑定的host、 进程、 Git 分支、进程 等。所有的命令行工具可以生成列表输出的都可以再通过管道 pipe 到 fzf 上进行搜索和查找。
详细使用方法暂无,等待大家补充
rg(grep高级版)
rg(ripgrep)是一个快速、功能强大的命令行工具,用于在文件中搜索文本内容。它是 grep 的现代替代品,结合了速度、易用性和强大的功能,特别适合处理大型代码库或文本文件。安装:sudo apt install ripgrep
用法:
rg "pattern": 和grep类似,搜索当前目录及其子目录中匹配 “pattern” 的所有文件rg "main" --type c: 搜索所有 .c 文件中包含 “main” 的行rg "debug" --glob '!logs/*': 忽略 logs 目录及其内容rg "pattern" --hidden: 搜索隐藏文件rg "pattern" --binary:默认不搜索二进制文件,需要这么包含rg "TODO" --glob '*.py': 仅搜索 .py 文件中包含 “TODO” 的行。rg "TODO"| bat: 命令组合,高亮rg "pattern1|pattern2": 多模式搜索rg "def .*function_name": 搜索大型代码库中的函数定义rg "error" --count: 统计特定词汇出现的次数rg "import numpy" --files-with-matches: 快速查找并定位文件rg "pattern" -C 3: 搜索并显示上下文
| 选项 | 作用 |
|---|---|
--ignore-case |
忽略大小写搜索。 |
--fixed-strings |
按字面含义搜索,不解析正则表达式。 |
--count |
仅输出匹配的总次数。 |
--files |
列出搜索目录中的所有文件,而不进行内容搜索。 |
--line-number |
显示匹配行的行号(默认开启)。 |
--context n 或 -C n |
显示上下文行数(默认上下各 2 行)。 |
--invert-match |
显示不匹配搜索模式的行(反向搜索)。 |
--files-with-matches |
仅列出包含匹配行的文件路径。 |
--heading |
为每个文件的匹配结果添加标题(默认开启,使用 --no-heading 关闭)。 |
| 特性 | rg | grep | ag (Silver Searcher) | ack |
|---|---|---|---|---|
| 性能 | 极快 | 快 | 快 | 较慢 |
| 正则支持 | 是 | 是 | 是 | 是 |
| 递归搜索 | 默认启用 | 手动添加 -r |
默认启用 | 默认启用 |
| 支持文件类型 | 是 (--type) |
否 | 是 | 是 |
| 支持忽略规则 | 支持 .gitignore |
否 | 支持 | 支持 |
at
at 是 Linux 中的一种计划任务工具,允许用户安排一次性任务在未来的某个时间点运行。与 cron 不同的是,at 只运行一次,而不是重复执行。以下是关于 at 命令的详细介绍。基本用法at [时间]
描述方式:
at 14:00at 2:00 PMat now + 2 hoursat now + 3 daysat 10:00 AM tomorrowat 5 PM Friat 2:00 PM 2024-12-25- 查看已安排的任务:
atq - 删除任务:
atrm [任务ID]
实例: echo "mysqldump -u root -p database_name > backup.sql" | at 11:00 PMecho "rm -rf /tmp/test" | at 2:00 AM tomorrowecho "/path/to/script.sh" | at now + 1 hour
tmux
tmux(Terminal Multiplexer)是一个非常强大的终端复用工具,可以在一个终端窗口中管理多个会话(session)、窗口(window)和窗格(pane)。它特别适合需要在远程服务器上运行多个任务的用户,因为即使断开连接后,tmux会话也可以继续运行。
主要功能:
- 多窗口管理:在一个tmux会话中可以打开多个窗口,每个窗口相当于一个独立的终端。
- 多窗格支持:在一个窗口内可以分割为多个窗格(横向或纵向分割)。
- 会话持久化:会话断开后,程序依然运行,重新连接即可恢复之前的状态。
- 共享会话:支持多个用户同时访问同一个tmux会话,适合协作任务。
- 自定义配置:通过配置文件(如~/.tmux.conf)自定义快捷键和行为。
基本用法: - tmux
pstree:ps的高级版
pstree 是一个用于以树形结构显示进程的 Unix/Linux 命令行工具。它可以显示系统中正在运行的所有进程,并通过层级结构直观地展现父子进程之间的关系。一般为预装的。使用方法pstree [选项] [PID|用户名]
pstree -a: 显示进程的完整命令行pstree -p: 显示进程名后括号中的 PIDpstree -u: 显示进程的用户信息pstree -n: 以 PID 的升序显示进程pstree -h: 高亮显示当前用户的进程pstree -G: 启用图形化的树结构(可能用 Unicode 线条)
与 ps 的对比
| 特性 | pstree | ps |
|---|---|---|
| 显示方式 | 树形显示父子关系 | 表格显示进程信息 |
| 侧重内容 | 进程的层级和关系 | 进程的详细属性和状态 |
| 易读性 | 更直观(树结构) | 需结合参数分析 |
可以直接pstree -apuhG
more & less: 文件查看命令
more 和 less 是 Linux 系统中用于查看文本文件内容的命令行工具。它们的主要功能是分页显示文件内容,便于用户浏览大文件。more 是较早的文本查看工具,功能相对简单。它以一页一页的形式显示文件内容,允许用户向下滚动查看。
用法:more filename
less 是 more 的增强版本,功能更加强大,支持双向滚动、更多的搜索和导航功能。支持vim的搜索。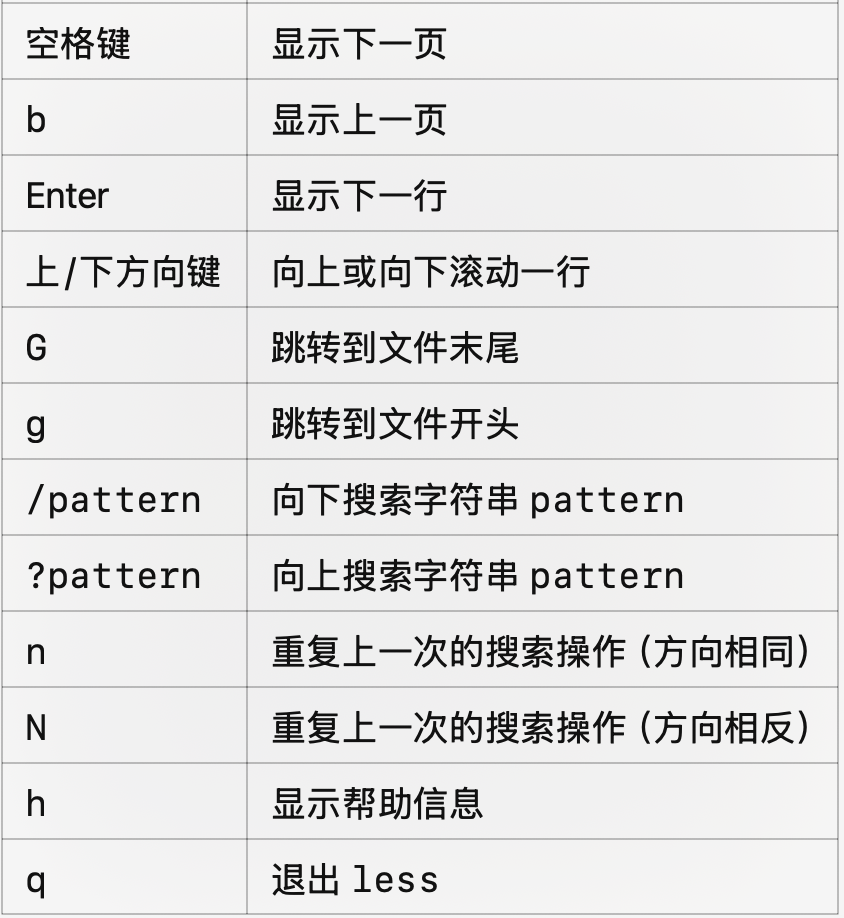
- 支持向前和向后滚动。
- 支持更强大的搜索和导航功能。
- 可以处理大文件而无需加载整个文件到内存中。
- 兼容性强,可替代 more 使用。
parallel: 并行命令
parallel 是一个强大的命令行工具,用于在 Linux 环境下并行执行任务。它的主要功能是并行化串行的 shell 命令或脚本,从而充分利用多核处理器的计算能力,显著提高任务的执行效率。以下是整理后的 parallel 常用命令及其解释:
parallel ::: "cmd1" "cmd2"- 解释: 并行运行多个命令(cmd1 和 cmd2),任务数默认为 CPU 核心数。
parallel --jobs N ::: "cmd1" "cmd2"- 解释: 指定最多并行运行的任务数为 N。
parallel -k ::: "cmd1" "cmd2"- 解释: 按提交任务的顺序输出结果,而不是按完成任务的顺序。
cat input.txt | parallel- 解释: 从标准输入读取命令或参数并并行执行。
ls *.txt | parallel gzip- 解释: 将所有 .txt 文件作为参数传递给 gzip 并行压缩。
echo {1..5} | parallel echo- 解释: 输出数字 1 到 5 的并行任务,每个任务输出一个数字。
echo -e "file1\nfile2" | parallel cp {} backup/- 解释: 使用 {} 替换每个文件名,将 file1 和 file2 复制到 backup/。
seq 100 | parallel --block 10 echo- 解释: 将任务分成块,每次处理 10 个任务。
parallel --results output_dir ::: "cmd1" "cmd2"- 解释: 将任务的输出保存到 output_dir 目录中。
parallel --timeout 5 ::: "sleep 10" "echo done"- 解释: 设置任务超时时间为 5 秒,超时的任务会被终止。
parallel --halt now,fail=1 ::: "cmd1" "cmd2"- 解释: 任务中只要有一个失败,立即停止所有任务。
parallel --eta ::: "cmd1" "cmd2"- 解释: 显示预计完成时间。
parallel --bar ::: "cmd1" "cmd2"- 解释: 显示任务进度条。
parallel --dry-run ::: "cmd1" "cmd2"- 解释: 显示 parallel 将执行的命令,但不实际运行。
parallel -a input.txt --jobs 4- 解释: 从 input.txt 文件中读取任务,并指定同时运行 4 个任务。
parallel echo {1} {2} ::: a b ::: 1 2- 解释: 生成两组参数的组合(a 1,a 2,b 1,b 2),并将它们传递给 echo。
cat urls.txt | parallel wget- 解释: 从 urls.txt 读取 URL,并用 wget 并行下载。
parallel --load 80% ::: cmd1 cmd2- 解释: 当系统负载低于 80% 时才启动新任务。
parallel gzip ::: file1 file2 file3- 解释: 并行压缩 file1,file2 和 file3。
即便是简单的命令,用 parallel 可以:
- 解释: 并行压缩 file1,file2 和 file3。
- 节省执行时间(充分利用多核和 I/O 并行性)。
- 简化任务管理(自动限制资源,动态调度任务)。
- 提高代码可读性和开发效率。
- 增强控制力(错误停止、超时、结果保存等)。
lspci
https://blog.csdn.net/songpeiying/article/details/131793155
lspci 是 Linux 系统中用于显示 PCI(Peripheral Component Interconnect,外部设备互连)设备信息的命令行工具。它是由 pciutils 软件包提供的工具之一,通常用于查看和管理计算机中的硬件设备,特别是 PCI 和 PCI Express 总线上的设备。
常见参数:
-
-v:显示详细信息,包括驱动程序、总线和端口等信息
-
-t:生成树形结构显示
-
-k:显示设备所使用的内核模块
-
-s [总线号]:[设备号].[功能号]:仅显示指定的设备信息
-
-D:仅显示PCI设备
-
-d [Vendor:Device ID]:仅显示指定的厂商和设备信息
-
-mm:显示机器可读格式
-
-M:显示设备的DMA通道
-
-vvv:显示更详细的信息,包括IRQ和IO端口
-
-n:显示数字标识符(Vendor:Device ID)
-
-nn:显示数字化的设备ID和供应商ID,以及详细的设备信息。
一般可以使用树形显示:lspci -t
-
根节点 0000:00 表示主板的根总线(Root PCI Bus),是所有 PCI 设备连接的起点
-
子节点是直接连接到根总线的设备,每个设备由它的总线地址标识
-
± 00.0、± 00.2 等表示直接连接到 0000:00 总线的设备
-
某些设备会作为桥(Bridge)连接到其他 PCI 总线。例如:
+- 02.1-[02-0f][02-0f]表示这个桥接设备连接了一个新的总线范围,从 02 到 0f

后续需要进一步了解可以看那个csdn,非常详细
lsof: 端口占用
lsof 是 Linux/Unix 系统中的一个强大的命令行工具,用于列出当前系统中所有被打开的文件信息。它的名字是 List Open Files 的缩写。在 Linux 系统中,几乎所有的资源(如文件、目录、套接字、设备、管道等)都被表示为文件,因此 lsof 能够帮助用户监控和管理这些资源。
不加任何选项时,lsof 会列出系统中所有打开的文件,输出的每一行包含以下信息:
- COMMAND: 打开文件的进程名。
- PID: 打开文件的进程 ID。
- USER: 进程所属用户。
- FD: 文件描述符(cwd、txt、mem 等)。
- TYPE: 文件类型(REG 文件、DIR 目录、CHR 字符设备等)。
- DEVICE: 设备号。
- SIZE/OFF: 文件大小或偏移量。
- NODE: 文件节点号。
- NAME: 文件路径或名称。
具体用法: lsof /path/to/file: 查看某个文件被哪个进程占用lsof -u 用户名: 列出某个用户的打开文件lsof -u ^用户名: 排除 root 用户,列出其他用户的打开文件lsof -p PID:查看某个进程打开的文件lsof -i :80:查看特定端口(如 80)的占用情况lsof -i:查看当前系统所有网络连接和监听套接字lsof /dev/sda1:列出某个设备上的打开文件kill -9 $(lsof -t /path/to/file):如果某个文件被占用,可以使用以下命令杀死相关进程
主要面向对象为系统管理员
mount
mount 命令用于在 Linux 系统中挂载文件系统,将设备(如硬盘分区、光盘、网络共享等)或虚拟文件系统(如 proc、sysfs 等)关联到系统的目录结构中,供用户访问。基本语法为:mount [OPTIONS] DEVICE DIRECTORY
- DEVICE:要挂载的设备或文件系统(如 /dev/sda1、nfs://server/share 等)。
- DIRECTORY:挂载点,必须是一个已存在的目录。
- [OPTIONS]:指定挂载选项,如只读挂载、文件系统类型等。
常见场景: mount /dev/sda1 /mnt: 将 /dev/sda1(如硬盘分区)挂载到 /mnt 目录(挂载前需要确保 /mnt 目录存在)mount -t ext4 /dev/sda1 /mnt: 将分区挂载为 ext4 文件系统类型mount -o ro,noexec /dev/sda1 /mnt: 以只读模式挂载分区,并禁止执行分区中的二进制文件mount -o loop /path/to/image.iso /mnt: 使用 loop 选项挂载 ISO 文件到 /mntmount -t nfs server:/share /mnt: 将 NFS 服务器的共享目录挂载到本地mount --bind /data /mnt: 将 /data 目录绑定到 /mnt,两者共享内容mount -o remount,rw /mnt: 将挂载在 /mnt 的文件系统重新挂载为读写模式mount -a:挂载 /etc/fstab 中定义的所有文件系统
fdisk
fdisk 是一个用于管理磁盘分区的命令行工具,主要用于 Linux 和类 Unix 系统中。它支持对磁盘进行分区创建、删除、修改和查看等操作。基本用法:fdisk [选项] [设备]
用法:
fdisk -l: 列出所有磁盘及其分区信息fdisk -u: 以扇区为单位显示分区信息fdisk -b: 指定每个扇区的大小,默认是 512 字节
等待补充交互式命令
mkfs
mkfs 是 Linux 中用于格式化文件系统的命令,完整名称是 “make filesystem”。它在指定的设备(如硬盘分区、USB 驱动器等)上创建新的文件系统。基本语法是:mkfs [选项] <设备>
常见形式是:mkfs -t <文件系统类型> <设备>
- -t:指定要创建的文件系统类型,例如 ext4、xfs、vfat 等。
- <设备>:要格式化的设备路径,例如 /dev/sda1、/dev/sdb1。
文件系统类型支持
mkfs 支持多种文件系统类型。以下是一些常见文件系统类型及其用途:
| 类型 | 说明 |
|---|---|
ext2 |
第二代扩展文件系统,较旧,不支持日志功能。 |
ext3 |
第三代扩展文件系统,支持日志功能,兼容 ext2。 |
ext4 |
第四代扩展文件系统,现代 Linux 的默认文件系统,支持大文件和性能优化。 |
xfs |
高性能文件系统,适合大文件操作,常用于企业级存储。 |
vfat |
FAT32 文件系统,适用于 U 盘和与 Windows 兼容的设备。 |
ntfs |
Windows 文件系统,适用于需要与 Windows 系统共享数据的设备。 |
btrfs |
一个新型文件系统,支持快照和子卷,强调高可靠性和可扩展性。 |
f2fs |
专为闪存设备优化的文件系统。 |
iso9660 |
CD/DVD 光盘文件系统。 |
常用选项
| 选项 | 作用 |
|---|---|
-t |
指定文件系统类型(如 ext4、xfs)。 |
-V |
显示命令的版本信息,但不执行任何操作。 |
-n |
模拟模式,不真正格式化,仅显示将要执行的操作。 |
-c |
检查设备上的坏块。 |
-L <标签> |
设置卷标(label),便于挂载时使用标签名称。 |
-v |
显示更多详细信息(verbose)。 |
env
env 是一个非常常用的命令,主要用于显示、修改和运行程序时设置环境变量。在 Linux 和 Unix 系统中,环境变量是影响进程运行行为的重要参数,比如 PATH、HOME 等。基本语法:env [OPTION]... [-] [NAME=VALUE]... [COMMAND [ARG]...]
env: 显示当前环境变量env NAME=VALUE COMMAND: 设置临时变量
和export的区别:
| 功能 | env |
export |
|---|---|---|
| 作用范围 | 仅对执行的命令生效 | 持续影响当前会话的环境变量 |
| 是否改变全局变量 | 不改变当前 shell 环境 | 会改变 shell 中的环境变量 |
| 使用示例 | env VAR=value command |
export VAR=value |
| 临时/永久性 | 仅一次性使用,命令结束后失效 | 在当前 shell 会话中永久生效 |
一般适用于脚本里保证环境捷径洁净
alias
Linux alias 命令用于设置指令的别名,用户可利用 alias,自定指令的别名。语法为alias[别名]=[指令名称]
例如:
alias ll='ls -alF'alias: 显示别名unalias ll: 删除ll的别名alias history='history | awk '"'"'{CMD="date +\"[%Y-%m-%d %H:%M:%S]\""; print CMD " " $0 }'"'"' | cut -c 29-': 向历史记录中添加时间戳
shell脚本之set
set 是 Linux Shell 中的一个内置命令,用于修改当前 Shell 的行为或列出当前 Shell 的环境变量及选项。它是一个非常灵活和强大的工具,提供了丰富的选项来控制脚本执行和调试。
在脚本中的常见用法:
| 选项 | 描述 | 示例 |
|---|---|---|
-e |
当命令返回非零状态时,立即退出脚本(错误退出)。 | set -e 或 set -o errexit |
-u |
使用未定义的变量时,报错并退出脚本。 | set -u 或 set -o nounset |
-x |
打印每条命令及其参数(调试用)。 | set -x 或 set -o xtrace |
-o pipefail |
管道中的任意一个命令失败,整个管道返回失败。 | set -o pipefail |
-n |
只检查脚本语法但不执行(调试用)。[写在开头] | set -n 或 set -o noexec |
+e |
取消 -e 的效果。 |
set +e |
+u |
取消 -u 的效果。 |
set +u |
+x |
取消 -x 的效果。 |
set +x |
set还可以用来设置shell的参数,比如:
set arg1 arg2 arg3
echo $1 # 输出: arg1
echo $2 # 输出: arg2
echo $3 # 输出: arg3jq
jq 是一个轻量级且灵活的命令行 JSON 处理工具。它专门用于解析、筛选、转换和格式化 JSON 数据。在处理 API 响应、日志文件或任何 JSON 格式数据时,jq 是非常强大的工具。
基本用法:echo '{"name":"Alice","age":25,"city":"New York"}' | jq
- 提取某个键的值:
echo '{"name":"Alice","age":25}' | jq '.name' - 提取嵌套键:
echo '{"person":{"name":"Alice","age":25}}' | jq '.person.name' - 提取数组元素:
echo '[1, 2, 3, 4]' | jq '.[1]' - 过滤JSON数据:
echo '[{"name":"Alice","age":25},{"name":"Bob","age":20}]' | jq '.[] | select(.age > 20)' - 修改json数据:
echo '{"name":"Alice","age":25}' | jq '.age = 30' - 增加新键:
echo '{"name":"Alice"}' | jq '.city = "New York"' - 遍历输出:
echo '[1, 2, 3, 4]' | jq '.[]' - 转json为csv:
echo '[{"name":"Alice","age":25},{"name":"Bob","age":30}]' | jq -r '.[] | [.name, .age] | @csv' - 合并json:
jq -s '.[0] + .[1]' file1.json file2.json - 打印出行数:
cat ~/yangz/fromall.json | jq length
| 表达式 | 作用 |
|---|---|
.key |
提取某个键的值 |
.[index] |
获取数组的某个元素 |
.[] |
遍历数组的每个元素 |
select(condition) |
根据条件筛选数据 |
@csv / @tsv |
将 JSON 转为 CSV 或 TSV 格式 |
.key1, .key2 |
提取多个键值 |
map() |
对数组中的每个元素进行操作 |
xsv
xsv 是一个高效的 CSV 文件处理工具,适用于 Linux 系统。它能够快速处理和操作 CSV 文件,尤其是在需要处理大量数据时表现出色。xsv 提供了多种命令,可以对 CSV 文件进行各种操作,例如查找、筛选、合并、统计等。
用法:
- 查看文件信息:
xsv stats <file.csv> - 选择列(或者使用列索引):
xsv select column1,column2 <file.csv> - 筛选数据:
xsv search "column1 > 100" <file.csv> - 排序数据:
xsv sort column1 <file.csv> - 查找数据:
xsv search hello <file.csv> - 合并文件:
xsv cat file1.csv file2.csv > combined.csv - 计算统计信息:
xsv stats column1 <file.csv> - 转换格式:
xsv tojson <file.csv> > output.json - 列数统计:
xsv headers <file.csv> - 获取文件的某些行:
xsv slice 0 10 <file.csv> - 查看文件内容的预览:
xsv preview <file.csv>
xsv 的优势在于它的高效性。相比于一些脚本语言(如 Python)中的 CSV 处理库,xsv 由于是用 Rust 编写的,具有更好的性能。特别是在处理大规模 CSV 文件时,xsv 的速度表现更加突出。
pv
pv(Pipe Viewer)是一个Linux命令行工具,用于在数据通过管道传输时显示进度信息、估计完成时间、显示数据传输速度等。这对于需要处理大文件或长时间运行的命令链条非常有用,能够实时监控数据流的情况。基本方法:pv [options] <input> | <command>或者command | pv | another_command
- 显示进度条
- 会显示一个进度条,显示通过管道的数据量。
- 显示数据传输速率
- pv 会实时显示数据传输的速度(比如 MB/s 或 GB/s)。
- 显示估算的剩余时间
- 基于当前的传输速度,pv 会显示完成任务所需的估算时间。
- 显示已传输数据量
- 会显示已经传输的数据量(比如 10GB)。
例如: - 使用pv来估计文件传输速度:
pv large_file.iso > /path/to/destination/large_file.iso - 查看压缩进度:
tar -czf - /path/to/directory | pv | gzip > archive.tar.gz - 将 bigfile.iso 通过管道压缩后发送到远程主机:
cat bigfile.iso | pv | gzip | ssh user@remotehost 'cat > remote_file.gz'
常用选项: - -p:显示进度条。
- -t:显示传输的总时间。
- -e:显示估算的剩余时间。
- -r:显示数据的传输速率。
- -b:显示已传输的字节数。
- -s :告知 pv 数据流的总大小,可以使进度条更加精确。比如,-s 10G 表示总数据量为 10GB。
- -a:显示通过管道的块数(而非字节数)。
- -q:静默模式,禁止显示任何信息。
btop
htop 的最新替代品,界面更加酷炫。
hyperfine
Hyperfine 是一个命令行基准测试工具,用于精准、可复现地测量任意命令的运行时间。相比手动使用 time 或脚本循环执行,Hyperfine 提供了以下优势:
- 统计分析:自动进行多次运行,并给出平均值、中位数、标准差、置信区间等统计信息。
- 自动化对比:可同时比较多个命令的性能差异,并以表格形式展示。
- 预热(warmup):在正式测量前进行预热运行,避免首次启动开销对结果造成偏差。
- 并行化:支持并发测量,以评估多进程或多线程情况。
- 输出格式:支持人类易读格式、JSON、CSV 等多种输出,方便做后续可视化或自动化分析。
基本使用方法与选项: -n, --runs <NUMBER>:指定要执行的测试次数。默认自动根据命令耗时确定(通常 10~100 次)。-w, --warmup <NUMBER>:指定预热运行次数,默认 3 次。-p, --parameters <NAME> <VALUES>...:参数化测试,可传入多组数值或字符串,自动对所有组合跑测试。-P, --parameter-file <FILE>:从文件加载参数列表。-c, --cleanup <COMMAND>:在每次测试后执行清理命令,例如删除临时文件。-L, --list:列出上次测试的历史记录。--export-json <FILE>:将结果导出为 JSON,便于用脚本或工具进一步处理。--export-csv <FILE>:导出为 CSV 格式。--export-markdown <FILE>:导出为 Markdown 表格。--timeout <SECONDS>:设置单次运行的超时,超时则跳过并报告错误。--parameter-scan <PARAM>=<START>:<END>[:<STEP>]:对数值参数做扫描测试。--min-runs <NUMBER>/--max-runs <NUMBER>:手动限制最少或最多执行次数。--verbosity <LEVEL>:设置输出详细程度(quiet,normal,verbose,debug)。
使用方法举例
#include <stdio.h>
int main(){
int iterations=1000000,b=0;
for (int nl = 0; nl < 2*iterations; nl++) {
b+=1;
}
}
#include <stdio.h>
int main(){
int iterations=1000000;
float b=1;
for (int nl = 0; nl < 2*iterations; nl++) {
b*=1.1;
}
}然后分别编译:clang -O0 1.c 和 clang -O0 2.c -o b.out
然后使用如下命令即可:
hyperfine \
--warmup 3 \
--min-runs 10 --max-runs 50 \
--prepare 'sync; echo 3 > drop_caches || true' \
--cleanup ':' \
--parameter-list prog ./a.out,./b.out \
--ignore-failure \
--time-unit millisecond \
--export-json results.json \
--export-csv results.csv \
--export-markdown results.md \
--show-output \
--command-name "{prog}" \
'{prog}'然后即会打印一些日志,同时生成一些文件记录:
Benchmark 1: ./a.out
Time (mean ± σ): 1.1 ms ± 0.2 ms [User: 1.0 ms, System: 0.2 ms]
Range (min … max): 0.8 ms … 1.7 ms 50 runs
Warning: Command took less than 5 ms to complete. Results might be inaccurate.
#
Benchmark 2: ./b.out
Time (mean ± σ): 7.1 ms ± 0.3 ms [User: 6.9 ms, System: 0.3 ms]
Range (min … max): 6.7 ms … 7.6 ms 50 runs
Summary
'./a.out' ran
6.27 ± 1.34 times faster than './b.out'dd
很少用到的命令,一般面向对象为系统管理员、嵌入式工程师、底层开发者或搞镜像/恢复的人。(略)
zoxide
zoxide 是一个用 Rust 编写的现代化目录跳转工具,旨在替代传统的 cd 命令,提升命令行操作效率。
zoxide 受到 z 和 autojump 的启发,记录并学习你访问过的目录,构建一个数据库,通过模糊匹配快速跳转到目标目录。
安装完毕后,使用方法很简单:
z foo:跳转到最常访问且名称包含foo的目录。意思就是 z 是支持模糊匹配的,会按你访问最多的优先z foo bar:跳转到名称同时包含foo和bar的目录。z foo/:跳转到以foo开头的子目录。z ~/foo:像传统cd命令一样工作,跳转到指定目录。z ..:返回上一级目录。(这个不如 zsh 的直接跳转)z -:返回之前的目录。(这个不如 zsh 的直接跳转)zi:列出zoxide所管理的目录列表,帮助查看记录的目录。
broot
broot 是一个现代化的终端文件管理器,旨在简化和加速 Linux、macOS 和 Windows 上的文件系统导航与管理。它由 Rust 编写,结合了树状目录视图、模糊搜索、面板操作和可自定义命令等功能,提供了比传统 tree 命令更强大和交互性更强的体验。【重在交互】
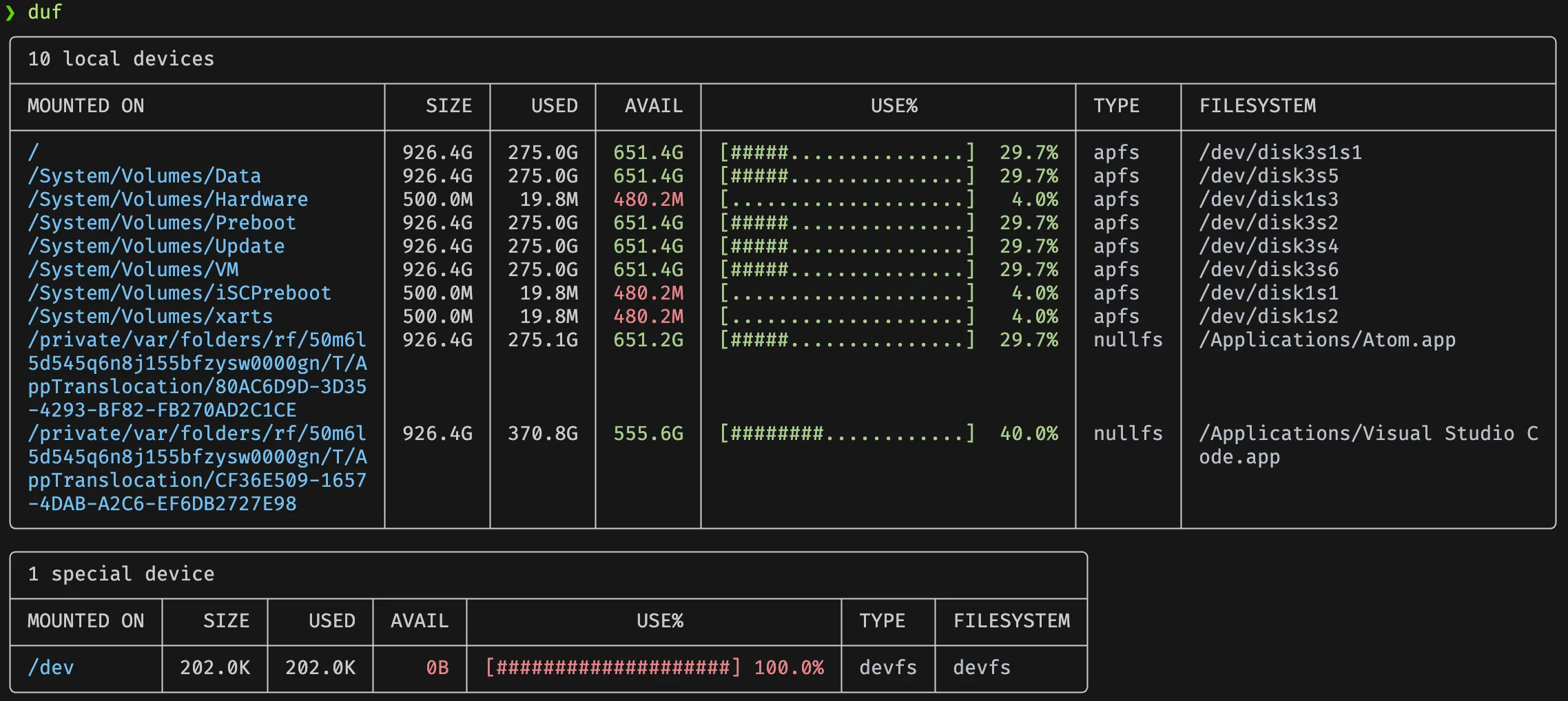
duf
duf 是一个用 Go 语言编写的现代化命令行工具,旨在替代传统的 du 和 df 命令,提供更直观、丰富的磁盘使用信息展示方式。
- 整合
du和df功能:同时显示磁盘使用量和剩余空间,避免切换多个命令。 - 彩色表格输出:以自适应的彩色表格形式展示信息,提升可读性。
- 支持排序与过滤:可根据使用量、总容量等字段排序,并通过选项过滤显示特定设备或文件系统。
- JSON 格式输出:支持以 JSON 格式输出,便于与其他工具集成或进行进一步处理。
- 查看 inode 信息:通过
--inodes选项查看 inode 使用情况,辅助诊断文件系统问题。
其他使用方法: duf --inodes:显示 inode 信息duf /Users:显示特定目录状况duf --jsonduf --sort used:按已用空间排序
dust
dust 是一个用 Rust 编写的命令行工具,旨在提供比传统 du 命令更直观的磁盘使用情况分析。它通过图形化的方式展示目录和文件的磁盘占用,帮助用户快速识别占用大量空间的目录。
🧰 功能特点
- 图形化展示:使用 ASCII 条形图和颜色区分,直观显示各目录或文件的磁盘占用比例。
- 智能递归:自动递归目录树,突出显示占用空间最大的子目录或文件。
- 无需额外排序:默认按大小排序,无需结合
sort或head命令。 - 多种选项:支持显示完整路径、限制显示层级、排除特定目录等功能。
使用方法和 du 类似! dust -d 1:设置显示层数dust -n 20:显示前 20 个占用空间最大的项dust -D或dust -F:仅显示目录或文件

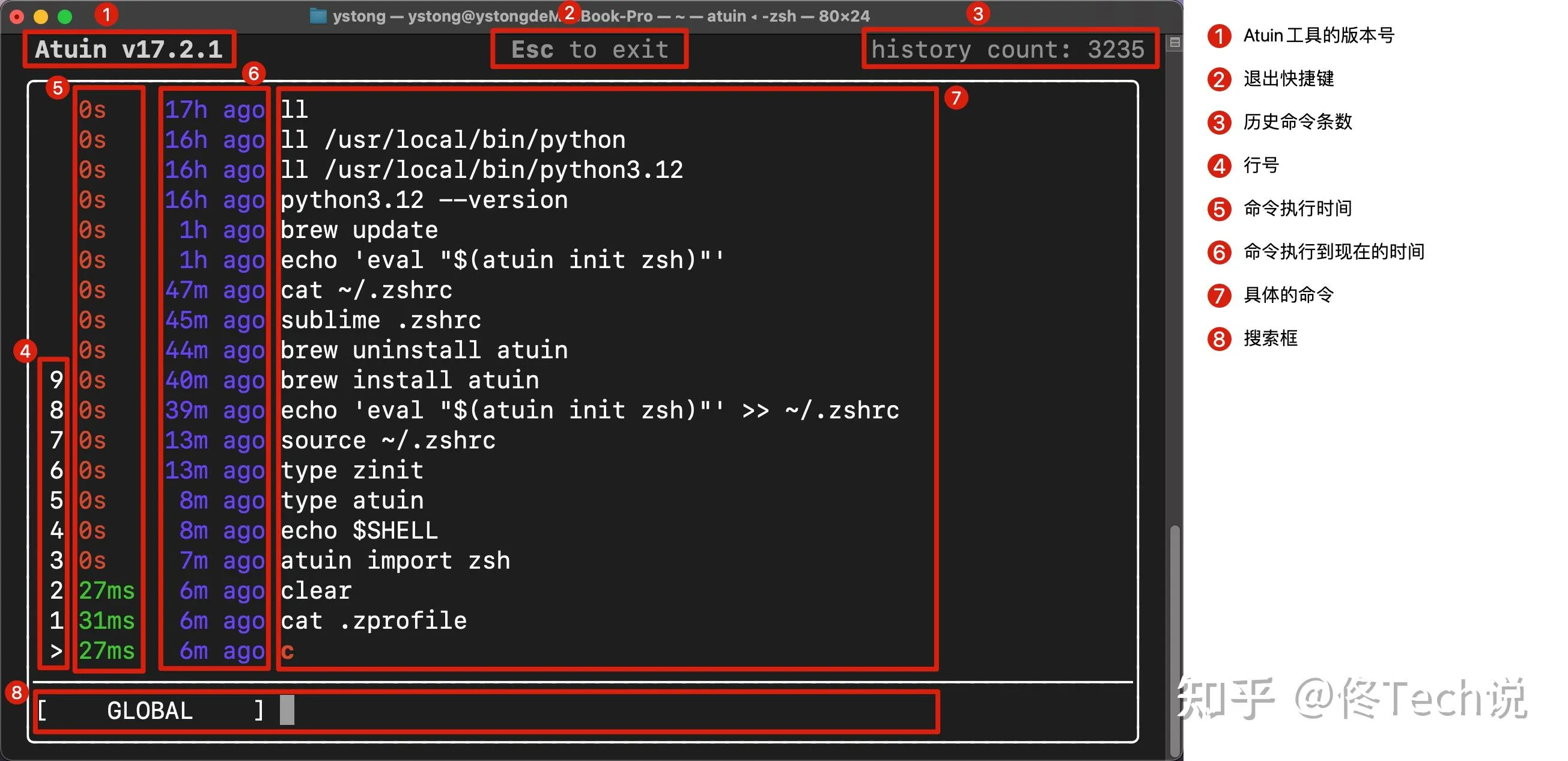
atuin
Atuin 是一个现代化的 Shell 历史记录管理工具,旨在增强命令行历史的功能和可用性。它使用 SQLite 数据库替代传统的 .bash_history 或 .zsh_history 文件,记录每条命令的额外上下文信息,如工作目录、退出状态、主机名、会话、命令持续时间等。
tldr
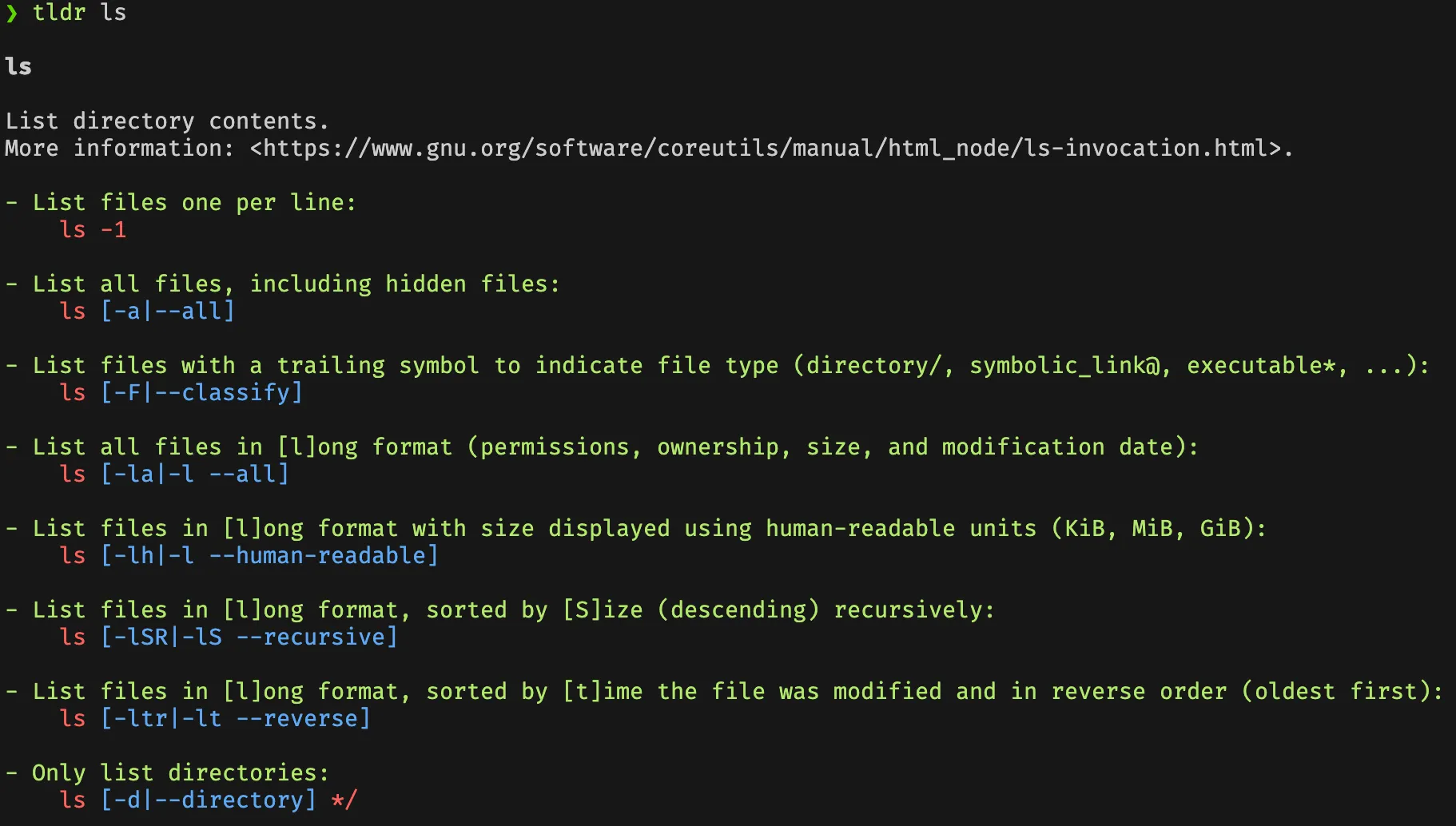
tldr 是一个命令行工具,旨在为常见的命令提供简洁、实用的使用示例,作为传统 man 手册的简化补充。其名称源自网络术语 “Too Long; Didn’t Read”,意在帮助用户快速获取命令的核心用法,而无需阅读冗长的文档。
使用方法非常简单:tldr <想看的命令> 就行
例如:
qsv
qsv(全称为 Quicksilver)是一款基于 Rust 的命令行数据处理工具,专为高效处理大型表格数据(如 CSV、TSV、JSONL、Parquet 等)而设计。它提供了超过 50 个可组合的子命令,涵盖数据查询、切片、索引、分析、过滤、转换、排序、验证、连接、格式化等功能,适用于数据科学、数据工程和数据清洗等场景。
qsv 的主要功能包括:
- 数据转换与增强:使用
apply命令对列进行字符串、日期、数学、货币等多种转换,还支持基本的自然语言处理功能,如相似度计算、情感分析、语言检测等。 - 数据分析:通过
stats命令快速生成每列的统计信息,包括均值、标准差、最常见值等。 - 数据连接与合并:使用
join命令实现 CSV 文件之间的连接操作,支持内连接、外连接和交叉连接。 - 数据验证与清洗:提供
dedup(去重)、fill(填充空值)、validate(验证数据格式)等命令,帮助清洗和标准化数据。 - 数据切片与采样:利用
slice和sample命令对数据进行切片和随机采样,适用于处理大型数据集。 - 格式转换:通过
fmt命令在不同的分隔符(如逗号、制表符)之间转换,支持 ASCII 分隔的数据。
对于偏好图形界面的用户,qsv提供了qsv pro,这是一个基于 Tauri 构建的桌面应用程序,提供了图形用户界面(GUI)来执行数据处理任务。qsv pro支持数据表格查看、统计信息生成、数据转换脚本(recipes)、CKAN 上传工作流等功能。
具体使用方法等待补充
qsv count data.csv:统计行数qsv dedup data.csv > deduped.csv:去重qsv join --left file1.csv file2.csv > joined.csv:连接两个 csv 文件
monolith
monolith 是一个命令行工具,用于将完整的网页保存为单个 HTML 文件,嵌入所有资源(如 CSS、JavaScript、图像等),以便离线查看。
功能亮点
- 完整保存网页:将网页及其所有依赖资源嵌入到一个 HTML 文件中,确保离线时页面的完整性。
- 资源嵌入:将外部资源(如 CSS、JavaScript、图像)转换为 base64 编码的 data URL,嵌入到 HTML 中。
- 灵活的选项:支持排除特定资源(如音频、视频、图像、JavaScript、CSS),设置自定义 User-Agent,指定超时时间等。
- 跨平台支持:支持 Linux、macOS 和 Windows 等多个平台。
monolith https://example.com -o example.html:保存网页为单个 HTML 文件
cat page.html | monolith -b https://example.com - > complete_page.html:从标准输入读取 HTML 并嵌入资源
ouch
ouch 是一个由 Rust 编写的命令行工具,全称为 Obvious Unified Compression Helper,旨在为用户提供简洁高效的文件压缩与解压缩体验。它支持多种常见压缩格式,简化了在终端中处理压缩文件的流程。
- 统一命令接口:使用统一的命令语法处理多种压缩格式,无需记忆不同工具的复杂参数。
- 广泛的格式支持:支持
.tar、.zip、.7z、.gz、.xz、.lzma、.bz2、.lz4、.sz(Snappy)、.zst(Zstandard)和.rar等格式。 - 自动格式识别:根据文件扩展名自动识别并选择合适的压缩或解压方式。
- 无运行时依赖:在 Linux x86_64 平台上运行时无需额外依赖。
- 辅助功能支持:提供辅助模式,提升可访问性。
- Shell 自动补全和手册:支持 Shell 自动补全和 man 手册,提升用户体验。
使用方法: ouch c <文件/目录> -o <输出>ouch d <压缩文件>- 获取压缩时帮助:
ouch c --help- 可以设置压缩线程
- 可以设置压缩密码
| 功能 | ouch |
tar / gzip / unzip 等传统工具 |
|---|---|---|
| 多格式支持 | ✅ | ❌(需使用多个工具) |
| 自动格式识别 | ✅ | ❌ |
| 简洁的命令语法 | ✅ | ❌(参数复杂) |
| 无运行时依赖 | ✅ | ❌ |
| 辅助功能支持 | ✅ | ❌ |
sk
sk 是一个高效、灵活的模糊查找工具,适用于各种终端操作场景。无论是查找文件、管理进程,还是搜索命令历史,sk 都能提供快速、直观的交互体验。其丰富的选项和 Shell 集成功能,使其成为提升终端工作效率的利器。
示例命令:
find . -type f | sk:查找文件ps aux | sk | awk '{print $2}' | xargs kill:查找并终止进程find . -type f | sk --multi > selected_files.txt:多选文件并输出到文件
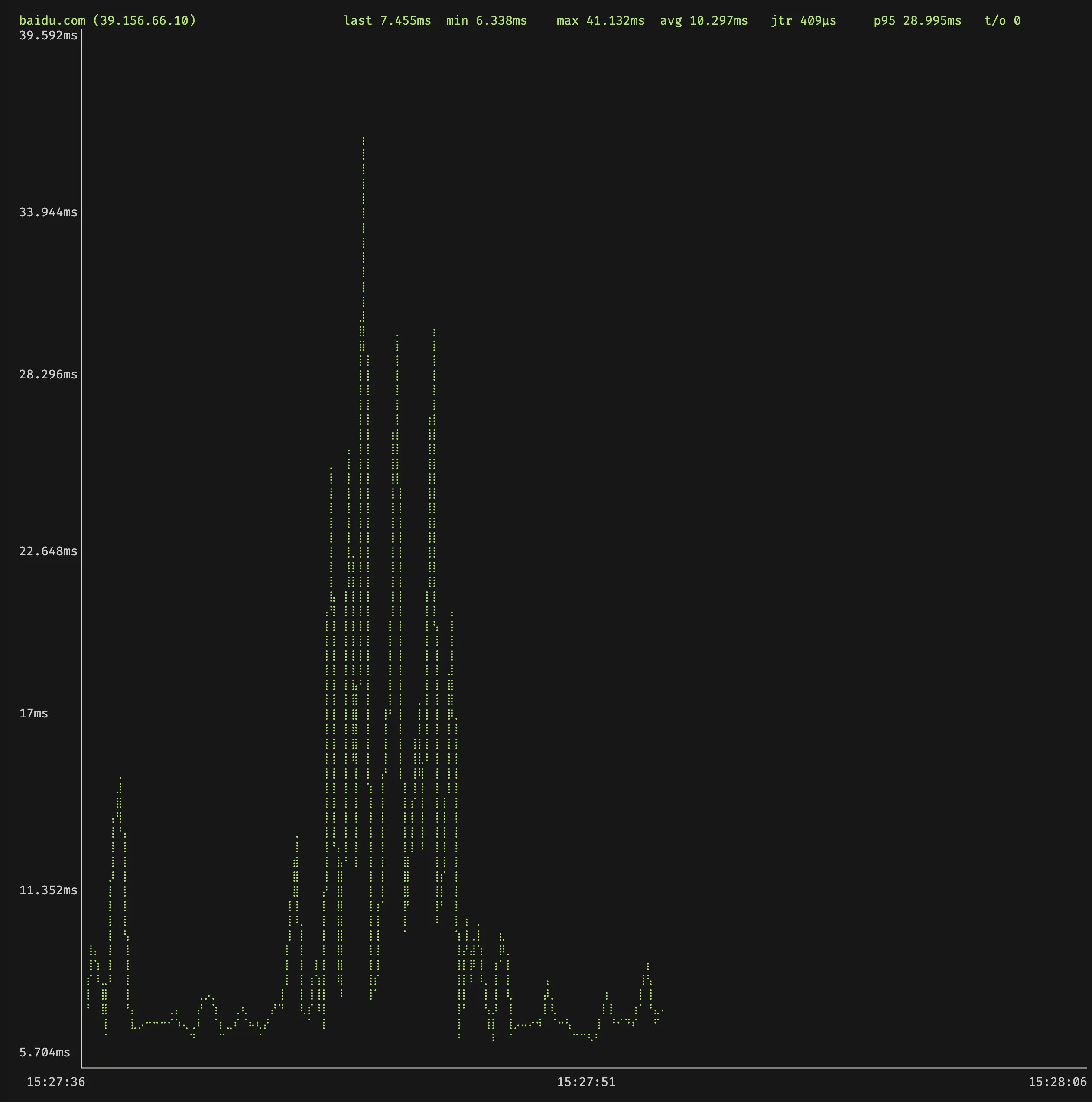
gping
gping(Graphical Ping)是一个跨平台的网络诊断工具,使用 Rust 编写。它的主要特点是在终端中以图形方式显示 ping 的响应时间,便于用户直观地观察网络延迟的变化趋势。除了基本的 ping 功能外,gping 还支持:
- 同时对多个主机进行 ping 操作,并以不同颜色区分
- 自定义图表的刷新间隔和显示时间范围
- 以图形方式显示命令的执行时间(使用
--cmd选项) - 支持 IPv4 和 IPv6
其会绘制优雅的 GUI:
也可以同时 ping 多个主机
bandwhich
bandwhich 是一个用 Rust 编写的命令行工具,用于实时监控 Linux 系统中的网络带宽使用情况。与传统工具不同,bandwhich 能够按进程、连接和远程 IP/主机名显示带宽使用情况,帮助用户快速识别哪些进程或连接占用了网络资源。
功能亮点
- 按进程显示带宽使用:实时显示每个进程的上传和下载速率,便于识别带宽占用大的进程。
- 连接级别监控:展示每个网络连接的带宽使用情况,包括本地和远程地址。
- 远程主机统计:按远程 IP 或主机名汇总带宽使用,帮助分析外部通信。
- 交互式界面:基于终端的用户界面,支持键盘导航和排序,类似于
top命令。
注意,在 Mac 上需要使用 sudo 权限