
每日论文合辑
(2025.06.12)【ASPLOS’25】 ClosureX: Compiler Support for Correct Persistent Fuzzing
因为对于该领域不熟悉,我还是召唤了翻译来理解每个词的本意:Fuzzing 是一种被广泛采用且务实的漏洞挖掘方法,用于加强软件的健壮性。研究表明,提高 fuzzing 的吞吐量能直接提升漏洞发现率。性能最高的 fuzzing 策略是「持久化 fuzzing」(persistent fuzzing),它通过在完成一次测试后循环回到入口,而不是退出进程,从而复用同一进程处理所有测试用例。这样就消除了与执行成本相当的进程创建、初始化和销毁开销。不幸的是,持久化 fuzzing 会导致语义上不一致的程序状态:一个测试用例对进程状态的修改会保留到后续测试中。这种语义不一致会带来漏报崩溃、误报崩溃以及整体错误,进而削弱模糊测试器的有效性。我们观察到,现有的 fuzzing 执行机制在“每次测试用例之间丢弃和恢复状态量”上形成一条连续谱。我们提出了 ClosureX,一种在这条状态恢复谱上位于新位置的执行机制:它仅重置与当前测试用例执行相关的状态。这样就实现了接近持久化的性能,同时保留了重量级状态恢复的正确性。我们将 ClosureX 实现为一组 LLVM Pass,并与 AFL++ 集成。在对十个流行的开源 fuzzing 目标的评估中,ClosureX 在保持语义正确性的同时,平均将测试用例执行速度提升了 3.5 倍以上(相比于 AFL++)。ClosureX 也比 AFL++ 更稳定、更快地发现漏洞,速度快 1.9 倍,且发现了 15 个 0-day 漏洞(4 个已记为 CVE)。
本文中 Fuzz 的定义:
Fuzzing is the process of generating test cases based on a set of seed test cases and running the test case against a program to find bugs.
背景、动机、贡献
- Fuzzing 着重需要关注的是生成未见过的用例,称为
coverage-guided fuzzing - 这篇论文关注的是如何减小 Fuzz 的开销(复用进程),而同行有两个极端
- ①每个 Fuzz 都单开一个进程
- ②所有 Fuzz 都使用一个进程(循环到开始)
- 本文核心是识别程序运行时的关键信息(例如变量修改),然后当可以复用时恢复他们然后执行下个例子
- 作者对 Persistent Fuzzing 的效率问题起到了贡献
补充信息:==在 fuzzing 领域,“怎么在性能和正确性中间平衡”一直是个难题。==很多工作要么牺牲正确性,要么牺牲性能,能在二者之间找到新切入点,就很有价值。
- Fuzz 的四个步骤:
- 程序插桩
- 测试用例生成
- 程序运行与监控
- 反馈分析与修复
- Fuzz 的两种层次:
- 高级语言:因为有源码,所以插桩效率和效果都好
- 二进制:基本块级别
- Fuzz 程序生成有两种:
- generational
- mutational
作者在背景结束时说了:**ClosureX is a coverage-guided, mutational, source-available fuzzer.**这个地方的定义下的不错。

- 作者在进程管理上做到了跨架构
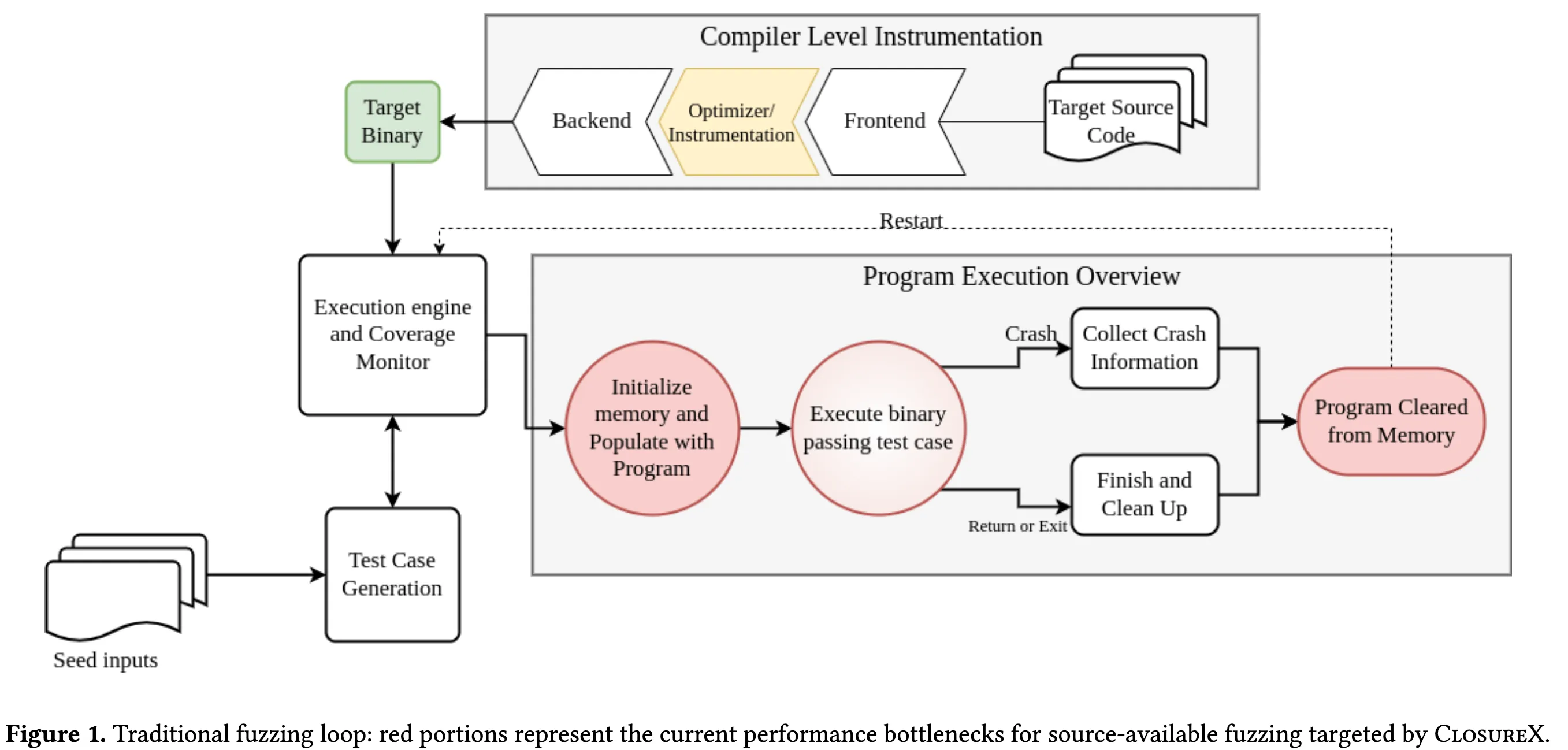
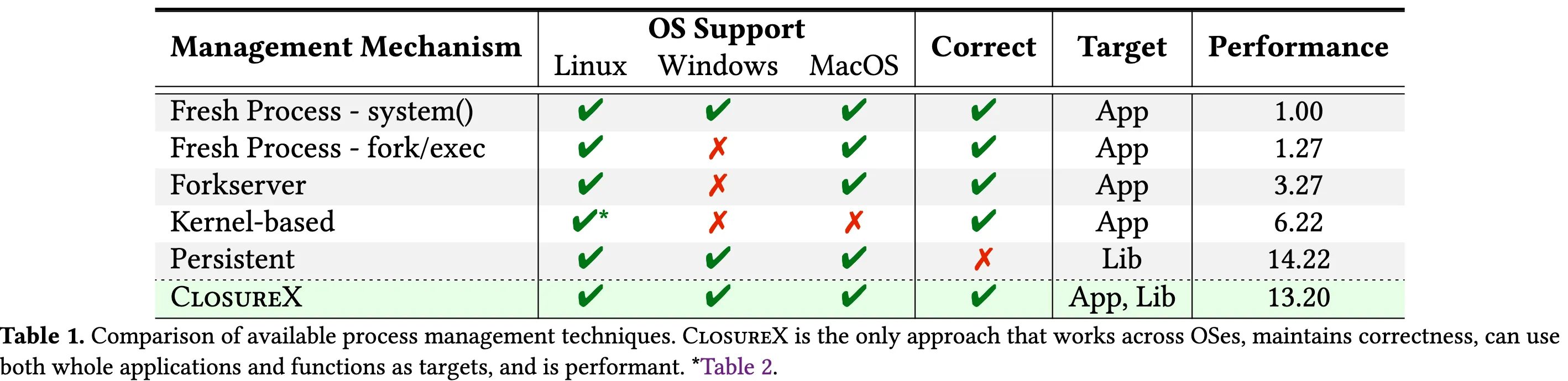
作者的动机在于(首先对比了几种 Fuzz 策略)对比了其他 Fuzz 的不足,已经讲明白了人家的缺点,比如依赖 os 导致无法跨架构,以及持续 fuzz 条件下进程的问题。主要导致:Semantically inconsistent
所以作者在实现时又回到了那个核心问题:让程序自己记录状态,并在相邻测例之间保持正确性。
- 要在 main 函数里着重对异常退出的程序恢复其栈信息、同时清空堆 (alloc) 。
(2025.06.13)【ASPLOS’25】 Composing Distributed Computations Through Task and Kernel Fusion
本论文是 NVIDIA 和斯坦福合著的
其摘要为:
我们提出了 Diffuse,一个在分布式、基于任务的运行时系统中动态执行任务和内核融合的系统。
Diffuse 的核心是一个用于分布式计算的中间表示(IR),它支持对分布式任务进行可扩展的分析,从而实现任务融合。
我们将任务融合与 JIT 编译器结合,进一步将融合任务中的内核合并执行。
实验结果表明,Diffuse 的中间表示具有足够的通用性,能够作为两个真实世界的基于任务的库(cuPyNumeric 和 Legate Sparse)的目标,使得 Diffuse 可以跨函数和库边界发现优化机会。
在最多 128 个 GPU 上,Diffuse 能够加速未修改的、由任务库组成的应用程序,平均提速 1.86 倍(几何平均),最高可达 10.7 倍(最低 0.93 倍)。
此外,Diffuse 还能发现原始应用程序开发者未曾识别的优化机会,使得用高级 Python 编写的程序在性能上达到或超越显式并行的 MPI 库。
一句话核心:The key component of Diffuse is an intermediate representation of distributed computation that enables the necessary analyses for the fusion of distributed tasks to be performed in a scalable manner.
关键概念:
- Sequential libraries:指的是像 NumPy 或 SciPy 这样的传统单机、单线程库,通常由用户在本地以串行方式调用,不考虑并行性或分布式执行。这些库是易于使用、表达力强的,但不具备分布式扩展能力。
- Task:任务是指运行时系统调度的基本执行单元,通常由库代码将高层操作(例如矩阵乘法)翻译为一系列的任务。每个任务通常处理 一小块数据,由运行时调度并发执行。任务是用户定义的函数调用,但并不直接执行,而是交由 runtime 统一调度。
- Kernel:每个任务的具体实现逻辑,称为 Kernel,即任务要执行的代码体。Task 是包装,Kernel 是真正干活的内容。多个任务可能共享同一个 kernel 实现(类似于函数体被多次调用)。
- runtime:运行时是任务调度的大脑,负责接收任务序列、分析数据依赖关系、安排并发执行、实现节点间通信和同步。
长难句:The task decomposition of library operations results in tasks that may be optimized individually but can have poor data locality and allocate much more temporary data than a different program organization that breaks down the abstraction boundaries by fusing tasks together both within the operations of a particular library and across library boundaries.
把库的==操作拆分成任务虽然可以对每个任务单独优化==,但这样做往往会导致数据局部性差、临时数据分配多。相比之下,如果能打破不同操作或库之间的边界,把任务融合在一起,就能实现更高效的程序组织方式。
背景、动机、贡献
本文的定义是在并行分布式系统上对库的调度优化。
- 作者不关注串行程序→并行程序,而是关注“如何高效地组合那些已经是并行的、分布式的程序,尤其是由不同人分别编写的库”。
(2025.06.15)【CGO’25】Towards Efficient Compiler Auto-tuning: Leveraging Synergistic Search Spaces
中规中矩的论文,点子和创意不够新,但是效果还行。行文的话一看是中国学生直接用英文进行的写作,通俗易懂。