
Plankton: Reconciling Binary Code and Debug Information
【二进制·I】Plankton: Reconciling Binary Code and Debug Information
元信息:
- 领域:二进制,反汇编,二进制提升,LLVM IR,栈消歧,类型系统
- 作者单位:香科大,香港城市大学
- 发表:ASPLOS 2024
- TL; DR:Plankton 是一种面向二进制的提升器(lifter),能够将编译优化过的二进制精确恢复为接近源代码级别的 LLVM IR,并保留高质量变量、类型和作用域信息。它通过栈区消歧、别名分析以及调试信息利用,有效提升静态分析在反编译 IR 上的准确性和适用性。评测显示,Plankton 在大规模基准和真实项目中显著减少了静态分析的误报与漏报,同时具备可扩展性,可支持更多体系架构与下游 LLVM 应用。
简评:这篇论文工作扎实,显然源于作者丰富的实践经验与深入的调研洞察,研究内容横跨多个相关领域,不仅涉及二进制分析,还涵盖编译器、类型系统等编译与程序设计的大类下的多个子领域。具体实现部分均基于严谨的算法设计,细节繁多、技术性强,因此此处未逐一展开。若进行略读,仅需关注第一章,即可快速把握研究动机与一个典型示例,从而理解当前亟需解决的问题。
摘要: 静态分析已被广泛应用于大规模软件缺陷检测。尽管近年来取得了显著进展,但其在实际应用中仍存在不足,因为它需要通过编译干预才能获得可分析的代码。直接使用二进制提升器(binary lifter)翻译二进制代码可以在一定程度上缓解这一问题,因为这种方式对构建系统无侵入性。然而,即便在存在调试信息的情况下,现有的二进制提升器仍无法生成足够精确的代码,难以支撑严格的静态分析。为此,本文提出了一种新的二进制提升器 Plankton,并引入了两种新算法,用于弥合低层代码与高层代码之间的鸿沟,从而在带有调试信息的二进制文件中生成高质量的 LLVM 中间表示(IR),在仅有轻微精度损失的情况下支持功能完备的静态分析。实验结果表明,Plankton 在静态分析效果上与传统的编译干预方案相当,仅有 17.2% 的结果差异,但在实用性上显著优于后者,并且在性能上较现有提升器平均提升了 76.9%。
1 引言
静态分析已被广泛应用于 C/C++ 程序的软件缺陷检测。然而,尽管近年来取得了巨大进展,一个长期被忽视的事实是:对编译过程进行干预的要求,实际上是现代静态分析落地的“最后一公里”问题。传统静态分析需要介入程序的构建流程以获取可分析的代码,这通常通过在原有编译配置中引入自定义编译器或解析器来实现。例如,SVF 要求最终用户使用 wllvm(一种 Clang 的包装器)来编译项目。然而,编译干预并非总是可行,原因主要有两方面:
首先,现代构建系统正变得日益复杂和多样化。例如,仅 C++ 语言就存在超过 20 种构建系统和 36 种编译器。支持如此庞杂的原生构建系统极其困难且易出错。以最成功的商用静态分析工具之一 Coverity Scan 为例,它在过去 20 多年中一直致力于实现对不同工具链的兼容性。然而,即便投入了巨大努力,编译干预的成功仍无法保证。例如,Coverity Scan 和 SVF 都曾被报告无法使用其自定义编译器编译源码,导致分析失败。
其次,软件构建过程的可访问性并非总能得到保证。例如,在云端代码扫描服务中,源码及其完整编译流程往往不可获取。上述问题严重阻碍了成熟静态分析系统在工业环境中的部署,这正是所谓的“最后一公里问题”。
与其在这最后一公里上投入巨大的精力,不如绕过这一问题,直接使用构建流程的最终产物——二进制文件。与传统方案相比,基于二进制的方法通过二进制提升(binary lifting) 获取可供分析的代码,这种方式对软件构建系统无侵入性,因此在真实环境下更不易失败。由此,问题就转化为:我们能否在提升后的代码上获得与编译源码相近的静态分析效果?
严格的静态分析需要目标代码中包含大量源代码级信息,以便推导其语义。当前最先进的静态分析方法主要依赖于关于两类程序实体的基本假设来设计分析算法,即变量边界与类型信息。然而,二进制代码天然不包含此类信息,而从纯二进制中恢复这些信息仍然是一个不可判定的问题,这会严重影响静态分析的精度。
图 1 简要展示了二进制代码中变量边界与类型信息缺失是如何影响数据依赖图(Data-Dependence Graph, DDG)构建的,DDG 是最基础的静态分析之一。
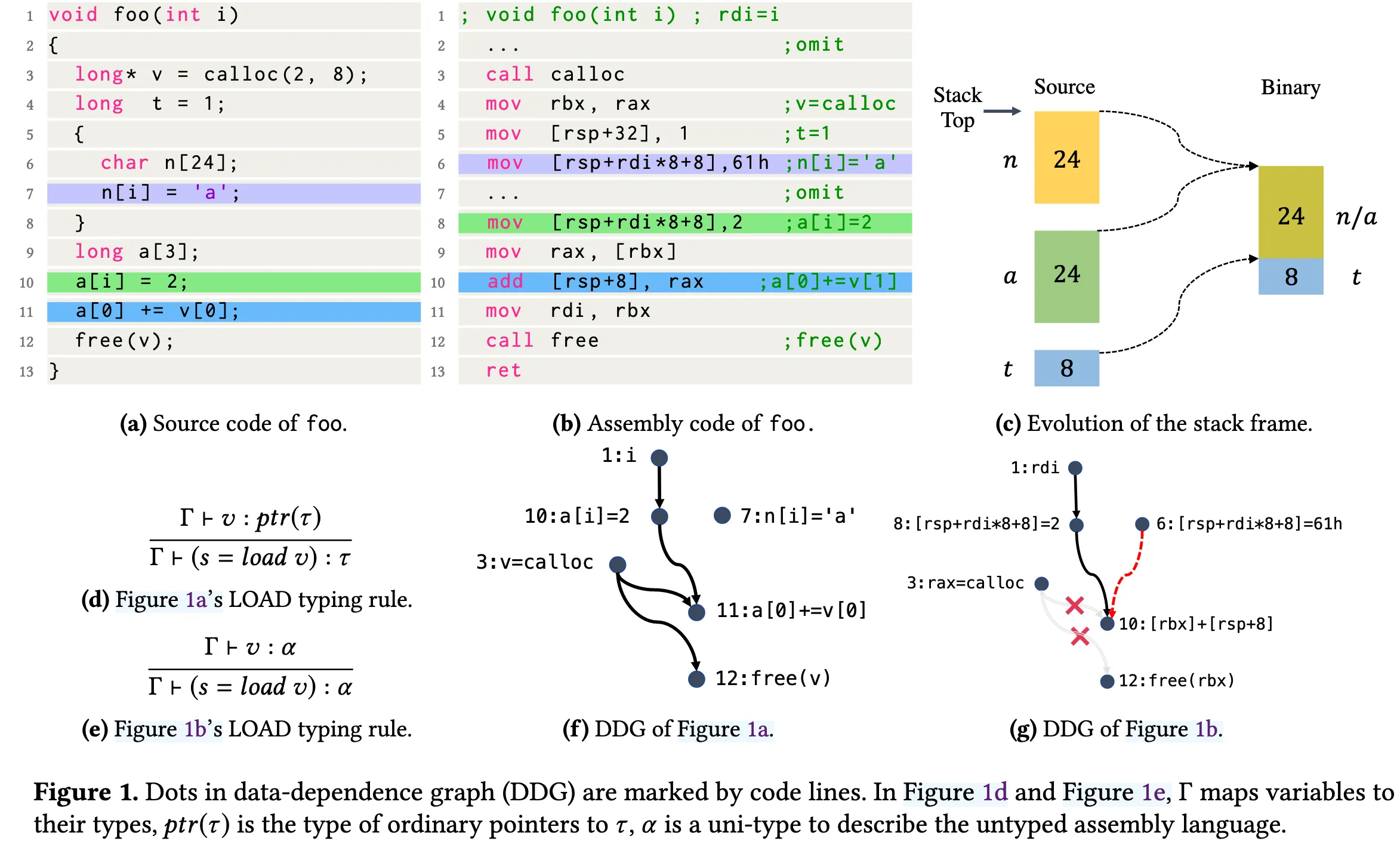
变量边界
与源代码中内存被划分为互不重叠的变量不同,汇编代码会“扁平化”内存空间,允许跨变量访问内存,甚至可能出现对象重叠。例如,在图 1(a) 中,第 7 行对 n[i] 的写操作与第 11 行对 a[0] 的读操作之间不存在任何数据依赖,因为每个局部变量都对应一个独立的内存块(图 1© 左侧),因此在图 1(f) 中 DDG 中没有这两行之间的边。然而,在二进制代码中,编译器会将 n 与 a 放入同一个栈槽([rsp+8])(图 1© 右侧),因为它们的作用域不重叠,这会引入一个伪造的依赖,从而在图 1(g) 中出现额外的边。
知识补充
- 栈帧(Stack Frame):函数调用时,编译器会在栈上为该函数分配一块连续的内存,用来存放局部变量、临时值、返回地址等。
- 栈槽(Stack Slot):在栈帧中分配给某个变量(或一组变量)的特定位置(偏移量)。比如
[rsp+8]就是一个“槽位”。
例如在高级语言中有:
char n[24];
long a[3];- 编译器会为
n分配一块 24 字节的内存 - 为
a分配另一块 24 字节的内存 - 它们在逻辑上是完全分开的,源代码级静态分析能看到这一点,所以不会认为
n[i]和a[i]有数据依赖。
但是编译器会分析变量的生命周期,既然 n 和 a 它们的存活时间没有重叠,则编译器认为可以复用同一块栈槽(比如[rsp+8])来存放n和a,这样可以: - 节省栈空间(尤其在嵌入式或高性能程序里很重要)
- 提高缓存命中率
所以在汇编代码中,n和a都变成了对同一个地址[rsp+8]的访问:
mov [rsp+rdi*8+8], 61h ; n[i] = 'a'
mov [rsp+rdi*8+8], 2 ; a[i] = 2二进制级静态分析看不到变量名和生命周期,只能看到:
- 两次内存访问发生在同一个地址
[rsp+8]的区域 - → 推断它们之间可能有数据依赖(即修改了同一内存)
这样就产生了伪依赖(false dependency),进而影响数据依赖图。
类型信息
二进制代码完全丢弃了高级类型信息,并允许对任意类型的值执行操作。例如,源代码中的内存读取(图 1(d))的类型规则要求操作数 v 必须是指向类型 τ 的指针,且加载值 s 的类型同为 τ;而在汇编代码(图 1(e))中,所有操作数都使用统一类型 α。现有静态分析工具通常会利用类型信息提升分析效率,丢失类型信息可能导致分析结果破坏。例如,图 1(a) 第 3 行中 calloc 返回的指针与第 11 行、第 12 行存在数据依赖。但在图 1(b) 中,calloc 分配的内存通过两个整型寄存器 rax 与 rbx(第 9 行与第 12 行)返回与操作,一些静态分析器(如 SVF)会忽略表现为整型的指针值,从而破坏数据流分析。这会导致图 1(g) 中缺少从第 3 行到其引用点的两条边,甚至会引发错误的内存泄漏告警,因为 calloc 的分配点未被分析到 free 函数调用。此外,没有正确的类型信息,静态分析器在内存分配函数调用点无法正确建模堆对象。
在 C/C++ 里,类型信息是非常严格的:
long* v = calloc(2, 8); // v 是 long* 类型
a[0] += v[0]; // 只能当 long 来用
free(v); // 只能传给需要 long* 的 free编译器和静态分析工具知道 v 是一个指针(long*)→ 所以可以很容易画出 “v 从 calloc 到 a[0] 再到 free” 的数据流。
汇编代码里完全没有“long*”的概念,只有寄存器和字节:
mov rbx, rax ; rax里是calloc返回的地址
add [rsp+8], rax ; 把rax当成整数加
...
call free ; free用的是rbx- 在 CPU 看来,
rax和rbx只是两个整数寄存器(通用寄存器) - 它不关心这是不是指针
- 所有值在二进制里都是“统一类型 α”
有些静态分析器(比如 SVF)为了效率,会有个简化假设: “如果一个值是整数类型,就不要把它当成指针来追踪”。结果:
calloc返回的指针存在rax- 后来被复制到
rbx - 分析器一看:这两个寄存器是整数,不是指针 → 就不连数据流
- 于是数据依赖图(DDG)断掉了
后果:假阳性 & 精度下降:因为分析器没看到free和calloc是同一块内存 → 会误报内存泄漏,分配的堆对象也无法被正确建模(比如不清楚它的大小、类型)
幸运的是,尽管纯二进制并不是编译源代码的理想替代品,但在软件静态分析场景中,调试信息仍是不可或缺的,因为它在调试、崩溃诊断和性能分析中极其有用。例如,现代操作系统均提供调试符号包,且最新版 MacOS 平台上的 Firefox 构建中包含嵌入式调试信息。在我们对来自 Linux 和 GitHub 的 100 个知名 C/C++ 项目(按 star 数量排名靠前的项目)的调研中,发现它们在生成二进制文件时全部支持输出调试信息。
因此,更可行的方案是在进行二进制提升时结合调试信息,以建立二进制代码到源代码的映射,从而帮助解决大量不可判定的逆向工程问题。尽管如此,调试信息仅提供源代码级信息的一个子集,因为编译器无法将所有二进制代码反向映射到源代码,这意味着在部分代码片段中,变量与类型信息仍然缺失,从而限制了提升代码与静态分析的精度(如第 2 节所示)。
1.2 我们的方法
本文提出了一种全新的二进制提升器 Plankton,并配合两种新算法,从带有调试信息的二进制文件中生成高质量的 LLVM 中间表示(IR),以支持精确、完整的静态分析,同时仅带来极小的精度损失。
我们的核心洞见在于:存在数据依赖关系的代码片段,在源代码层面上也往往具有一致的属性。这一特性使得我们能够在调试信息不完整的情况下,通过额外的静态分析与代码变换,填补二进制到源代码映射中的空白。
具体而言,我们的方法包括以下两部分:
(1)栈消歧算法(Stack Disambiguation Algorithm)
该算法旨在重建提升后代码中变量实体与栈引用之间的关联关系。直觉上,在源代码中,对栈槽(stack slot)的引用可以映射到在特定程序点可见的、由顶层变量表示的互不重叠的内存块,这本质上就是变量作用域信息。因此,该算法在调试信息提供的现有作用域基础上进行扩展,为每个变量计算精确的作用域。算法利用指令间的数据依赖关系,将栈内存引用进行分组,并通过结构不变量构建出良定义的变量作用域。
(2)类型强化算法(Type Enforcement Algorithm)
该算法旨在恢复提升后代码中所有值的正确类型。直觉上,在 C/C++ 等强类型语言中,所有操作都必须遵循严格的类型规则,即类型不匹配的值必须显式进行类型转换以保证代码的有效性。因此,类型转换的使用频率可以反映类型恢复的正确程度:正确类型值越多,所需的类型转换越少。算法从部分已知的值类型出发,通过保持语义等价的代码变换,逐步消除类型转换,并将结果向所有代码片段传播,直到收敛于固定点,以最大化类型正确性水平。
我们基于 LLVM 编译器基础设施使用 C/C++ 实现了 Plankton,并在真实程序上结合两种先进的静态分析工具(SVF 与 Pinpoint)进行了评估。实验结果表明,Plankton 能够充分利用源代码级静态分析技术,取得与传统编译干预方法相当的漏洞检测效果,结果差异仅为 17.2%,而实用性更强,且在精度方面平均优于现有提升器 76.9%。进一步的实验还表明,大部分剩余结果差异源于静态分析本身固有的“随机性”,这证明了 Plankton 在实际应用中与传统编译干预方法同样有效。
总而言之,本文的贡献如下:
- 提出了两种新算法,可结合调试信息从二进制文件中生成高精度 LLVM IR,从而实现完整的静态分析。
- 实现了结合上述算法的全新二进制提升器 Plankton,并在解析调试信息及代码提升过程中处理了大量复杂情形,投入了显著的工程化工作。
- 通过实验验证了 Plankton 具有足够好的可扩展性与精度,在实用性更强的同时,与源代码编译结果的差异仅为 17.2%,并且在平均精度上优于现有提升器 76.9%。
2 研究动机
2.1 激励性示例
将软件构建产物(二进制文件)直接翻译为可分析的代码表示形式,具有显著潜力来实现更为实用的静态分析流程,因为这一过程对构建系统无侵入性。然而,将为高级语言设计的静态分析直接应用于低级汇编代码,会因为两者之间存在巨大的语义鸿沟而导致严重的精度损失。

一个激励性示例,展示了函数
foo的原始源代码、其编译后的汇编代码,以及经过 Plankton 翻译后的结果。三段代码均经过简化以提高可读性。彩色标注的代码行表示它们之间的对应关系(一个源代码行可能会映射到多条汇编指令)。文中的注释旨在帮助理解,并不代表实际的调试信息与源代码的映射关系。
我们通过一个激励性示例来说明二进制代码与源代码之间可能影响静态分析的两大核心差异。图 2(a) 展示了函数 foo 的源代码,图 2(b) 展示了使用 Clang -O1 -g 编译后得到的对应 X86_64 汇编代码。以图 2(a) 第 7 行 sc.qitem = self->qitem 语句为例,它被编译为图 2(b) 第 5 行的 mov [rsp+48], rax 指令。
变量边界(Variable boundaries)
在图 2(a) 中,sc 变量拥有独立的内存块,因此 sc.qitem 只能在访问 sc 时被访问。而在图 2(b) 中,所有局部变量被放置在平坦化的栈内存中,并通过相对于 rsp 寄存器的偏移量进行访问。因此,对应 sc.qitem 的栈槽 [rsp+48] 可能在任意使用 rsp 相对偏移访问的情形下被访问,这迫使静态分析需要推理可能不存在的(伪造的)数据依赖关系,从而造成精度下降。
类型信息(Type information)
在图 2(a) 中,该赋值语句遵循严格的类型规则,且数值具有正确的类型——它向 sc.qitem(Item* 类型)写入一个 Item* 类型的指针。而在图 2(b) 中,寄存器 rax 与栈槽 [rsp+48] 中保存的值可以是任意类型,这可能会误导静态分析,产生错误结果。即使有调试信息,也不足以完全填补二进制与源代码之间的差距,因为编译器无法将所有二进制代码反向映射到源代码。例如,调试信息可能告诉我们图 2(b) 第 11 行的 [rsp+16] 对应源代码中的 sc 变量,但对于第 17 行的 [rsp+24] 则无法映射到任何变量。
2.2 现有方法的局限性
现有的二进制提升器(binary lifter)在支持严格静态分析时普遍存在多方面的局限性。
首先,诸如 McSema 等提升器会输出完全忠实于机器执行语义的仿真式 IR,这种 IR 过于低级,无法直接支持源代码级静态分析。
其次,诸如 RetDec 等提升器仅将调试信息中的知识直接应用于提升后的代码,而没有意识到调试信息本身的不完整性,因此会导致显著的精度损失。
此外,即便是最先进的反编译器(如 IDA Pro 与 Ghidra),也无法在带有调试信息的情况下精确翻译二进制代码,因为它们的算法通常依赖于预定义的规则或模式。结果是,在 IDA Pro 的反编译代码中,图 2(b) 第 3 行与第 8 行的栈引用会被声明为独立的值,而非 sc 结构体的字段。
更进一步,将这些反编译器的输出重新编译为可供分析的代码表示,往往需要大量人工干预,并且对于大型程序来说并不总是可行的。
2.3 我们的方法
核心洞察
我们克服上述局限性的核心洞察在于:存在数据依赖关系的代码片段在源代码层面也具有相应的属性依赖关系,这使得我们能够利用这些依赖关系,结合不完整的调试信息,填补二进制到源代码映射中的空白。基于这一洞察,我们提出了两种新算法,以更好地解决二进制提升(binary lifting)中最关键的两个问题。
2.3.1 变量边界(Variable Boundaries)
在二进制代码中,经过编译器优化后内存布局被“扁平化”,因此需要将其重新划分为互不重叠的变量,以便支持静态分析。然而,由于调试信息的不完整,现有的二进制提升器只能将部分栈引用映射到变量实体。例如,在图 2b 中,第 11 行的栈引用被映射为变量 sc,而第 17 行的 [rsp+24] 则没有任何映射。
直觉 :我们直觉认为,已识别变量的存活区间(live range)可以帮助我们将二进制层面的内存引用与源代码中的变量建立联系。例如,如果我们拥有 sc 的完整作用域信息,就可以判断第 17 行的 [rsp+24] 实际上是 sc 的一个字段。
因此,第一个算法为每个局部变量推导出其作用域,并利用该信息恢复精确的变量信息。具体而言,算法通过静态分析,利用多种作用域不变式(例如:重叠的变量具有不相交的作用域)以及内存引用之间的数据依赖关系,提取一组约束条件。将这些约束与调试信息结合起来进行统一求解,即可获得每个变量的最终作用域。
例如,对于图 2b 第 11 行引用的 sc,算法收集到两个数据流事实:
- 该位置访问的值在第 7 行由
mov rax → [rsp+24]定义; - 第 22 行从
[rsp+24]读取了同一个值,因为在这两行之间的路径中没有重新定义该位置的值。
这表明,这三处 [rsp+24] 实际上引用的是同一个值,因此应属于同一个局部变量。接着,Plankton 将这些事实与“变量作用域必须连续”的作用域不变式结合,根据控制流图(CFG)为 [rsp+24](即 sc)绘制作用域,该作用域覆盖了第 11 行的 sc。此外,二进制代码中 sc([rsp+16])的字节大小为 40,因此 [rsp+24] 必定是 sc 的字段而非独立变量,因为 24 − 16 < 40 且不同变量不应重叠。经过上述分析,sc 的作用域可扩展至第 7 行至第 22 行。
2.3.2 类型信息(Type Information)
为了便于静态分析,提升后的 LLVM IR 中的所有值都应当分配正确的类型。然而,由于调试信息只能将少部分值映射到正确类型,现有提升器仍可能留下大量类型不正确的值。例如,在图 2(b) 中,第 6 行的 r15 被标记为 Cmd* 类型,而第 7 行的 rax 却是未类型化的。
直觉
在强类型语言(如 C/C++)中,所有操作都必须遵守严格的类型规则,这意味着类型不正确的值必须通过显式类型转换才能满足这些规则。因此,如果我们能够在保持 LLVM IR 有效性的前提下消除这些类型转换,就能够为所有操作分配正确的类型。换句话说,类型转换的使用程度反映了类型正确性的水平——类型越正确的代码,所需的类型转换越少。
基于这一直觉,我们的第二个算法利用保持语义等价的代码转换(semantic-preserving transformations),持续消除类型转换并分配正确的值类型。例如,图 3(a) 展示了由图 2b 第 6 行和第 7 行的汇编指令直接翻译得到的原始 LLVM IR。

算法首先进行代码优化,移除图 3(a) 中的冗余(类型转换)操作,使值之间的依赖关系更显式化(如图 3b)。接着,将 inttoptr 和 bitcast 指令转换为 getelementptr,并修改 load 指令的类型(如图 3©)。随后,通过插入 ptrtoint 保持代码的有效性,将加载的值转换回原始类型。完成此步骤后,我们不仅为 load 指令分配了正确的类型,还将类型提示向前“传播”到下一条指令。
进一步的转换将得到图 3(d),其中已经不存在类型转换。最终,图 2© 展示了 Plankton 的翻译结果,其与由源代码编译的版本高度相似。
评估
机器:Intel Xeon E5-1620 v3 CPU, 500G Memory, Ubuntu 16.04 LTS.
评估中采用了两款基于 LLVM 的最新静态分析工具 Pinpoint 与 SVF。二者均执行稀疏值流分析(sparse value-flow analysis),用于检查程序的源–汇(source–sink)属性。我们利用它们检测五类常见 CWE 漏洞:空指针解引用(NPD)、释放后使用(UAF)、双重释放、文件描述符泄露以及内存泄露。在本次评测中,所有静态分析的超时限制均设为 24 小时,内存上限为 500 GB。
评测指标
由于本研究的目标并非直接评估静态分析工具本身的检测能力,我们不直接测量分析结果的精确率与召回率,而是将对编译后 IR 的分析结果视为“基准真值”(ground truth),并与对反编译后(lifted)IR 的分析结果进行对比。当两份报告具有相同的源位置与汇位置时,认为它们为相同报告。
- 真阳性(TP):在编译后 IR 与反编译后 IR 中均检测到的漏洞。
- 假阳性(FP):仅在反编译后 IR 中检测到的漏洞。
- 假阴性(FN):仅在编译后 IR 中检测到的漏洞。
基准测试集
如表 1 所示,评测使用了标准基准测试集与真实世界程序。标准基准包括 Juliet Test Suite。真实世界程序方面,我们选择了包括 PHP 在内的 17 个开源 C/C++ 项目,总计 18 个项目。我们使用 wllvm(Clang 的封装工具)生成静态分析所需的 LLVM IR。所有二进制文件均通过两种主流系统编译器(Clang 与 GCC)并使用项目默认配置进行构建。
在 18 个项目中,14 个默认以调试信息(debug information)构建,其余 4 个则提供启用调试构建的选项。此外,所有二进制文件均根据项目默认配置使用不同级别的编译器优化选项进行构建,包括 -O0、-O3、-Ofast 等。最终,我们在评估中共获得 48 个二进制文件。
6 讨论
交叉编译 :Plankton 同样支持其他体系架构(如 Arm)。在实验中,我们仅使用 X86_64 进行评估,原因在于该架构的普及性以及所有基准方法均支持该架构。
生成其他 IR 形式 :目前,Plankton 仅生成不同版本的 LLVM IR。这是因为 LLVM IR 更适合静态分析,并且已有大量静态分析工具基于其构建。尽管 Plankton 不能直接生成其他形式的 IR(如 Gimple),其底层算法具有通用性,因此可以在其基础上实现 Gimple 的提升器(lifter)。
其他下游应用 :由于 Plankton 能够生成接近源代码的 LLVM IR,它除可用于静态分析外,还能支持基于 LLVM 的其他应用,包括二进制组合分析、链接后优化以及代码嵌入等。其中部分任务(如链接后优化)要求生成的 LLVM IR 可重新编译。虽然 LLVM IR 在设计上是可重编译的,但当前 Plankton 无法保证 100% 成功重编译,因为并非所有汇编指令都存在对应的 LLVM IR 表达(部分指令与系统相关),且并非所有库函数均被正确建模(见 § 5.4.1)。因此,若要支持这些应用,还需额外工作,我们将其作为未来研究的一部分。
7 相关工作
二进制提升(Binary Lifting) :已有大量提升器被提出,用于从二进制文件生成 LLVM IR。SecondWrite 基于 VSA 方法从剥离符号信息的二进制中恢复变量和数据类型,但未考虑可能的变量重叠,且仅对顶层变量推断类型。BinRec 基于动态反汇编进行提升。Lasagne 静态地将 X86_64 二进制翻译为 LLVM IR,并编译为 Arm,同时强制执行 x86 内存一致性模型。revng 依赖 QEMU 执行提升。LISC 自动学习从汇编到 IR 的翻译规则。Inception 合并从二进制与源代码生成的 LLVM IR。mctoll 和 RetDec 也通过代码转换改进生成的 LLVM IR,但 mctoll 采用的窥孔(peephole)转换仅考虑针对整型指针指向对象的单个操作,且 LLVM 优化仅用于减少代码体积。更重要的是,这些转换均只运行一次且无指导,显著限制了其效果。
基于元数据的二进制分析 :大量现有工作利用编译器生成的元数据以促进需要高质量二进制翻译结果的分析任务。Egalito 与 RetroWrite 使用嵌入在位置无关代码(PIC)中的附加元数据以实现精确的二进制重写。PEBIL 与 Vulcan 需要符号信息以进行静态二进制插桩。Zeng 等人、Shuffler、MCFI、Selfrando 以及 CCR 利用编译器生成的信息来实施控制流完整性(CFI)。HPCToolkit 提出了利用调试信息理解经过完全优化的模块化代码的性能。Park 等人利用与 JNI 互操作相关的类型信息改进二进制反编译与静态分析,但其方法仅处理并传播函数签名类型。与上述工作不同,Plankton 首次利用调试信息以辅助静态代码分析。