
AOBO:A Fast-Switching Online Binary Optimizer on AArch64
【二进制·II】AOBO: A Fast-Switching Online Binary Optimizer on AArch64
🌏元信息:今年<u TACO 第二期</u的原创文章(“New Article, Not an Extension of a Conference Paper.”),来自华东师范大学,不开源。
关键词:Post-link optimization, code layout optimization, online code replacement, AArch64 instruction set architecture(后链接优化,代码布局优化,运行时代码替换,AArch64 ISA)
TL;DR :AOBO 是首个面向 AArch64 的在线二进制优化器。它基于 BOLT 重写器,提出低复杂度的混合边权估计方法,并通过在线代码替换在不中断应用的情况下完成优化切换。在 MySQL/MongoDB 等实际场景中实现了显著加速和亚秒级停顿时间。
前言
这篇论文的方法论整体上比较朴素。由于我对 BOLT 已经较为熟悉,通读全文后会发现,文中所述的大部分技术路径实际上就是大家常用的套路:例如借助 objdump 或类似工具扫描指令、识别调用点(这一部分作者直接复用 BOLT 的框架)。在权重估计方面,作者提出了一个结合前驱和后继基本块的混合估计方案,本质上是一个比较直观的 trick,但其优势在于复杂度低,且在“实时优化”的场景下能在保证轻量化的同时达到不错的效果。
在动机上,作者强调 AArch64 平台缺乏 LBR(Last Branch Record)等硬件支持,因此需要提出新的边权估计方法。但除去这个点,其他大部分方法论其实在 X86-64 或其他架构上都是通用的,这使得 AArch64 本身作为研究动机显得相对薄弱。作者的 离线阶段 基本流程是:原 ELF + perf 采样数据 → (BOLT/AOBO 重写器) → 优化后的函数代码 + 原地址 → 新地址映射表而在 在线阶段(AOBO 部分),流程则是:暂停目标进程 → 进行栈分析 → 找到当前栈帧涉及的直接调用点(bl 指令) → 修改调用点以跳转至优化函数
整体而言,方法论部分相对常规,但作者在 实时性(subsecond 级别在线替换) 和 低复杂度混合估计 两个维度上给出了针对性优化。更多局限性可以参考论文的第七节。
前置概念
- ① 什么是边缘分析(Edge Profiling) 边缘分析是一种程序运行时的性能分析技术,用来统计程序控制流图中“边”(即基本块之间跳转)的执行频率。它能帮助编译器或优化器判断哪些路径被频繁执行,从而在这些关键路径上进行优化,提升整体性能。
- ② 什么是在线代码替换(Online Code Replacement) 在线代码替换指的是在程序运行过程中,将当前正在执行的原始二进制代码切换为经过优化的新代码,而无需停止整个应用。它通常包括生成优化代码、加载新版本、并在合适的时机切换执行流。
- ③ 在线代码替换的好坏
- 好处:能在应用运行时提升性能,无需停机重启;优化效果立竿见影,尤其适合长时间运行的大规模服务器应用。
- 坏处:实现复杂,需保证切换过程的安全与正确性;如果处理不好,可能导致性能抖动、暂停时间过长,甚至影响系统稳定性。
- ④ 优化后的函数哪里来的?为 AArch64 定制化的 BOLT 生成的。
原文翻译
摘要
随着现实世界中服务器应用的复杂性不断增长,大规模应用的性能优化正变得愈发具有挑战性。OCOLOS 与 Dynimize 在在线优化上的成功表明,基于边缘分析(edge profiling)数据的二进制重写能够显著加速这些应用。然而,目前在 AArch64 平台上尚无类似的在线二进制优化器。
针对 AArch64 平台日益增长的应用需求,本文提出 AOBO ——一种专为 AArch64 设计的快速切换型在线二进制优化器。AOBO 不仅为 AArch64 特有特性提供了实用且高效的工程支持,还克服了大多数商用 AArch64 服务器缺乏硬件计数器用于边缘分析的难题。尤其值得注意的是,AOBO 采用了一种新颖的边权重估计方案,以实现更精确的边缘估计,从而使其二进制重写器能够生成效率更高的代码。此外,AOBO 在在线代码替换阶段的耗时被优化到亚秒级,这使得应用能够在极短的时间内从运行原始二进制平滑切换到运行优化后的二进制。
我们使用 CINT2017、GCC、MySQL 与 MongoDB 对 AOBO 进行了评估,测量了边权重估计的准确性与覆盖率、优化后二进制的性能提升,以及在线优化的开销。为了保证对比的公平性,我们采用各软件包默认编译脚本生成的二进制性能数据作为基线。实验结果表明,AOBO 能够提供更为精确的边权重估计,并生成性能更优的二进制程序。同时,AOBO 以极低的开销实现了在线优化,并显著提升了大规模应用的性能。与基线相比,AOBO 的在线优化在 MySQL 和 MongoDB 上的性能分别提升了 24.7% 与 31.11%。更为重要的是,应用暂停时间在 MySQL 上从 1599.8 毫秒 降低至 462.1 毫秒,在 MongoDB 上从 1765.9 毫秒 降低至 507.1 毫秒。
引言
随着现实世界中服务器应用代码规模的持续扩展与程序复杂性的不断增长,大规模应用的优化变得愈发具有挑战性。大规模应用的性能优化涵盖了广泛的方向,既包括软件层面的方案,也包括硬件层面的方案。然而,这些优化方法大多仅在应用源代码可用,或存在特定硬件加速器时才可行。而在许多应用场景中,这些条件往往无法满足。
因此,研究人员提出基于 后链接优化(Post-Link Optimization, PLO) 的二进制优化方法,以优化大规模应用。实践表明,该方法无需修改源代码,也不依赖硬件加速器,便能实现显著的性能提升。PLO 是在程序编译的链接阶段之后进行的一类优化,其核心思想是利用性能分析数据来优化大规模应用的代码布局。PLO 主要依赖的性能分析数据是控制流图(CFG)中边的执行频率,这些频率统计了函数调用次数与基本块跳转次数。在性能分析数据的指导下,PLO 会将频繁调用的函数或执行路径中相邻的基本块放置在一起,以改善代码局部性。进一步而言,PLO 会根据执行轨迹的“热度”重新排列基本块,确保最热的后继基本块作为默认顺序流(fallthrough)。这种优化可以减轻现代处理器分支预测器的压力。
从处理器微架构的角度看,这类代码布局优化能够显著减少大规模应用的指令缓存缺失(icache misses)、指令 TLB 缺失(iTLB misses)以及分支预测失败(branch mispredictions)。例如,图 1 展示了一个简化的代码布局优化实例。为了提高代码局部性,优化后的代码将热点代码放置在一起,并将最热的后继路径作为默认顺序流。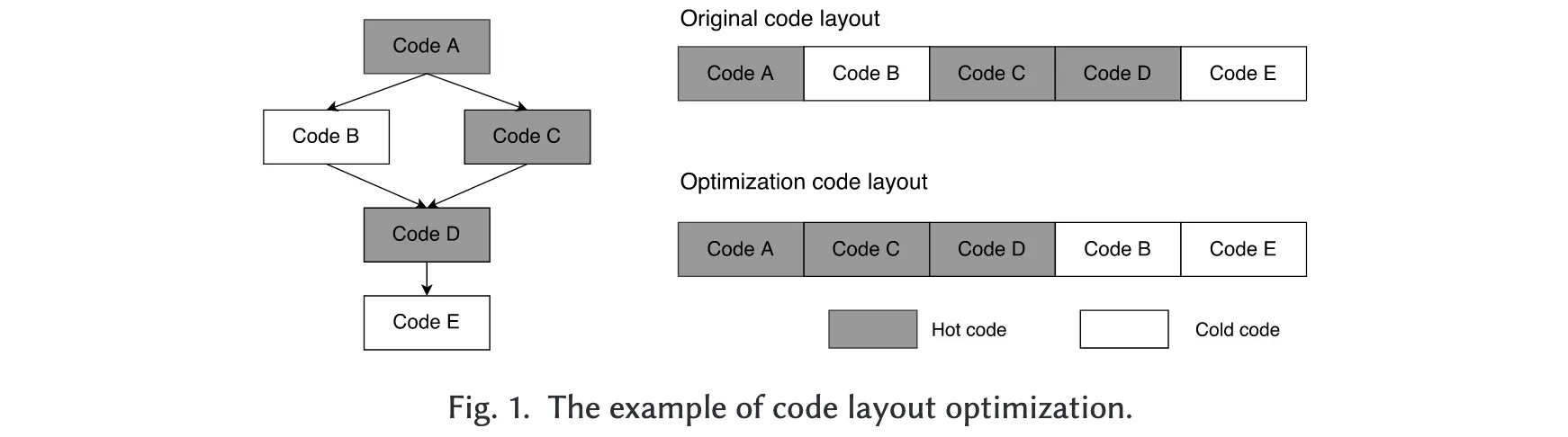
PLO 的性能分析数据主要可以通过两类方式获取:基于软件的插桩或基于硬件的采样。基于插桩的方法会带来不可忽视的运行时开销,并且插桩后的二进制通常无法直接部署在生产环境中,这限制了其应用范围。相比之下,基于硬件的采样在生产环境下是一种实用的边权重收集方法。在现代 X86-64 平台上,可以直接利用 最后分支记录(Last Branch Records, LBR) 硬件寄存器来收集边信息。然而,在 AArch64 平台上,大多数商用服务器并未提供类似 LBR 的广泛可用的分支分析硬件。
ARM 的 嵌入式跟踪宏单元(Embedded Trace Macrocell, ETM) 是 Cortex-A、Cortex-R、Cortex-M 和 Neoverse 系列处理器中用于捕获分支信息的强大硬件组件,但 ETM 主要用于嵌入式设备、智能终端系统或开发板,并未在商用 ARM 服务器中得到广泛支持。另一种新兴硬件特性是 分支记录缓冲区扩展(Branch Record Buffer Extension, BRBE),其功能与 Intel 的 LBR 类似。但 BRBE 仅在 ARMv9.2 及之后的架构中得到支持,而基于 ARMv9.2 的服务器芯片目前尚未在市场中广泛应用。
因此,在大多数缺乏硬件支持边缘分析的商用 AArch64 服务器上,边权重数据必须依赖估计算法来获取。典型的方法是利用 Linux 的 perf 工具采集采样地址,并通过聚合这些采样地址的计数来推导基本块的执行频率。基于基本块执行频率,再进一步估计控制流图中边的执行频率。
近年来,基于 PLO(后链接优化,Post-Link Optimization)的二进制优化器受到了广泛关注。例如,BOLT 与 Propeller 已在 Meta 与 Google 的实际应用中得到广泛使用。然而,大多数基于 PLO 的二进制优化器属于离线优化器。按照 PLO 的常见优化流程,首先需要从运行中的应用收集性能分析数据,然后二进制优化器根据这些数据生成优化后的二进制文件。随后,必须停止正在运行的原始应用,并重新启动经过优化的应用。在生产环境中,应用的重新启动被视为一项极其关键的操作,需要经过谨慎的考量与规划。这一操作不仅会延长应用停机时间,还需要重新初始化相关的监控与测试程序。
为解决上述问题,理想的在线二进制优化器应当能够在无需重新启动应用的情况下完成优化。在已有工作中,Dynimize 与 OCOLOS 达到了该领域的最新水平,但二者均仅适用于基于 X86-64 指令集架构(ISA)的应用优化。近年来,采用 AArch64 ISA 的处理器已迅速普及并获得广泛认可。为了在 AArch64 平台上实现无需重启应用的有效二进制优化,我们提出了 AOBO ——一种面向 AArch64 的快速切换型在线二进制优化器。
与基于 PGO(Profile-Guided Optimization) 的方法不同,后者在中间表示(IR)层级依据性能分析数据进行代码布局优化,而基于二进制重写的方法则能在性能数据收集阶段与利用这些数据的二进制重写阶段之间,保持更精确的指令映射关系。因此,二进制重写能够实现更一致且更高效的优化效果。
然而,设计与实现这样一种优化器也面临若干挑战。我们总结出三大主要挑战,并提出相应的解决方案,同时强调克服这些挑战所带来的收益:
首先,在新的指令集架构(ISA)上设计并实现一个在线优化器,需要进行深思熟虑的、特定于该 ISA 的考量。据我们所知,AOBO 是首个在 AArch64 上设计并实现的实用型在线二进制优化器。在整体设计上,AOBO 使用 AArch64 的二进制重写器,在目标应用运行的过程中由独立进程生成优化后的二进制文件,随后通过在线代码替换机制,将内存中的原始二进制替换为优化版本。为了确保在线代码替换的正确性与高效性,我们在 AArch64 平台上实现了若干关键的体系结构设计。由于运行中应用的程序特性会动态变化,在线优化的能力使 AOBO 能够对程序的运行时行为进行分析,并基于收集到的性能分析数据动态优化代码布局。此外,在线优化能够在无需重新部署应用的前提下完成优化,从而极大提升了服务的连续性。
其次,AArch64 的二进制重写依赖于精确的边权重估计。不同于 X86-64 平台,大多数现有的商用 AArch64 服务器并不具备 LBR(Last Branch Record)硬件特性。BOLT 是一个功能强大的离线二进制优化器,支持 AArch64 平台,同时作为一个活跃的开源项目已被集成进 LLVM。然而,BOLT 所采用的边权重估计算法相对简单,仍存在优化空间。为此,我们在 AOBO 的二进制重写器中设计并实现了一种更精确的边权重估计方法,称为混合边权重估计方案。基于该方案,AOBO 的二进制重写器能够在 AArch64 平台上实现更高效的代码布局优化。
最后,一个实用的在线优化器需要能够快速地完成从运行原始应用到运行优化应用的切换。AOBO 通过在线代码替换机制避免了应用重新部署的需求。然而,在代码替换过程中,AOBO 仍需要将执行流从原始代码切换至优化代码,这会导致程序出现短暂的暂停。为提升 AOBO 在生产环境中的实用性,我们对代码替换阶段的应用暂停时间进行了优化,使其能够在亚秒级内完成切换。该优化进一步提升了服务的连续性,并在一定程度上降低了在线代码替换过程中对延迟敏感型应用的影响,从而带来更平滑的用户体验,满足实际生产环境中的性能需求。
为了验证 AOBO 的有效性与实用性,我们开展了一系列实验。我们使用 SPECspeed 2017 整数基准测试(CINT2017) 以及若干实际工作负载来评估 AOBO 边权重估计方案的准确性与覆盖率。与 BOLT 的原始估计算法相比,AOBO 在保持略宽覆盖率的同时,能够获得更为精确的边权重估计。借助更准确的边权重估计来指导二进制重写,AOBO 的二进制重写器相较于软件包默认编译脚本生成的二进制,能够实现更高的性能提升。具体而言,AOBO 在 MySQL 上带来平均 32.86% 的性能提升,在 MongoDB 上提升 43.14%,在 GCC 上提升 12.21%,并且超过了原始 BOLT 所取得的优化效果。
此外,我们选择 MySQL 和 MongoDB 作为大规模应用的在线优化对象。在无需重新启动 AArch64 平台应用的前提下,AOBO 能够对使用默认脚本编译的 MySQL 和 MongoDB 分别带来 24.7% 与 31.11% 的性能提升,同时在在线优化过程中对应用运行影响可以忽略不计。更值得注意的是,应用暂停时间在 MySQL 中从 1599.8 毫秒 降低至 462.1 毫秒,在 MongoDB 中从 1765.9 毫秒 降低至 507.1 毫秒。
最后,我们将所提出的混合边权重估计方法与当前最先进的性能剖析推断技术 profi 进行了比较。实验结果表明,我们的方法在减少边权重估计时间的同时,还能够提升生成二进制程序的性能。
综上,本文的贡献主要包括:
- 我们提出了 AOBO,首个面向 AArch64 的在线二进制优化器,能够在应用运行时对其进行优化。
- 我们在 AOBO 中设计并实现了一种 混合边权重估计方案,通过基本块执行频率推断边权重,从而实现更为准确的估计。
- 我们优化了在线代码替换中的应用暂停时间,使得运行二进制能够在亚秒级时间内完成切换。
- 我们从多个角度对 AOBO 进行了全面评估,包括边权重估计的准确性与覆盖率、离线与在线优化带来的性能提升,以及在线优化开销。实验结果表明,AOBO 能够在小开销下显著提升大规模应用的性能,并支持其在线优化。
本文其余部分的结构如下:第 2 节概述 AOBO 的设计,包括二进制重写与在线优化组件;第 3 节详细介绍 AOBO 内部混合边权重估计方案的设计,并与其他估计算法进行对比;第 4 节描述 AOBO 在线优化的具体实现;第 5 节阐述实验设计,以验证 AOBO 的有效性与实用性;第 6 节总结相关工作;第 7 节讨论当前工作的局限性;最后在第 8 节给出结论,并展望未来工作。
2 系统概述
AOBO 是一种面向 AArch64 平台的高效且实用的在线二进制优化器。其设计基于 OCOLOS 框架,并针对 AArch64 进行了定制与优化。图 2 展示了 AOBO 的整体架构。AOBO 包含三个功能模块,并通过一个驱动器来协调这些模块之间的控制流转移。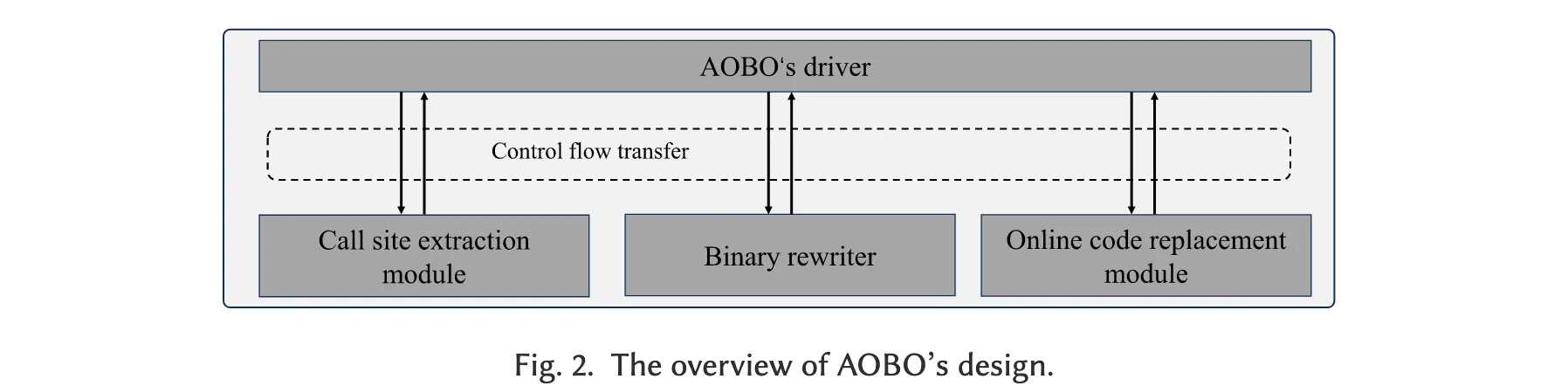
- 调用点提取模块(Call Site Extraction Module):识别待优化应用中的函数调用关系,用于辅助后续的代码替换操作。
- 二进制重写器(Binary Rewriter):在性能分析数据的指导下生成优化后的二进制文件。
- 在线代码替换模块(Online Code Replacement Module):将内存中正在运行的代码更新为优化后的版本。
AOBO 的在线优化通过在应用运行期间调用二进制重写器执行二进制重写,并在生成优化二进制后执行一次在线代码替换来实现。此外,借助二进制重写器的能力,AOBO 也支持高效的离线二进制优化。
2.1 二进制重写
AOBO 的二进制重写器是 BOLT 的 AArch64 定制版本。由于当前大多数商用 AArch64 服务器不具备边缘分析硬件,AOBO 的二进制重写器采用 边权重估计方法 来获取边权重信息。BOLT 内置的原始估计算法不足以准确推断边权重,因此我们在 AOBO 中提出了一种新颖的 混合估计方法,以获取更为精确的边权重,从而生成更高效的代码。如图 3 所示,AOBO 的二进制重写过程如下: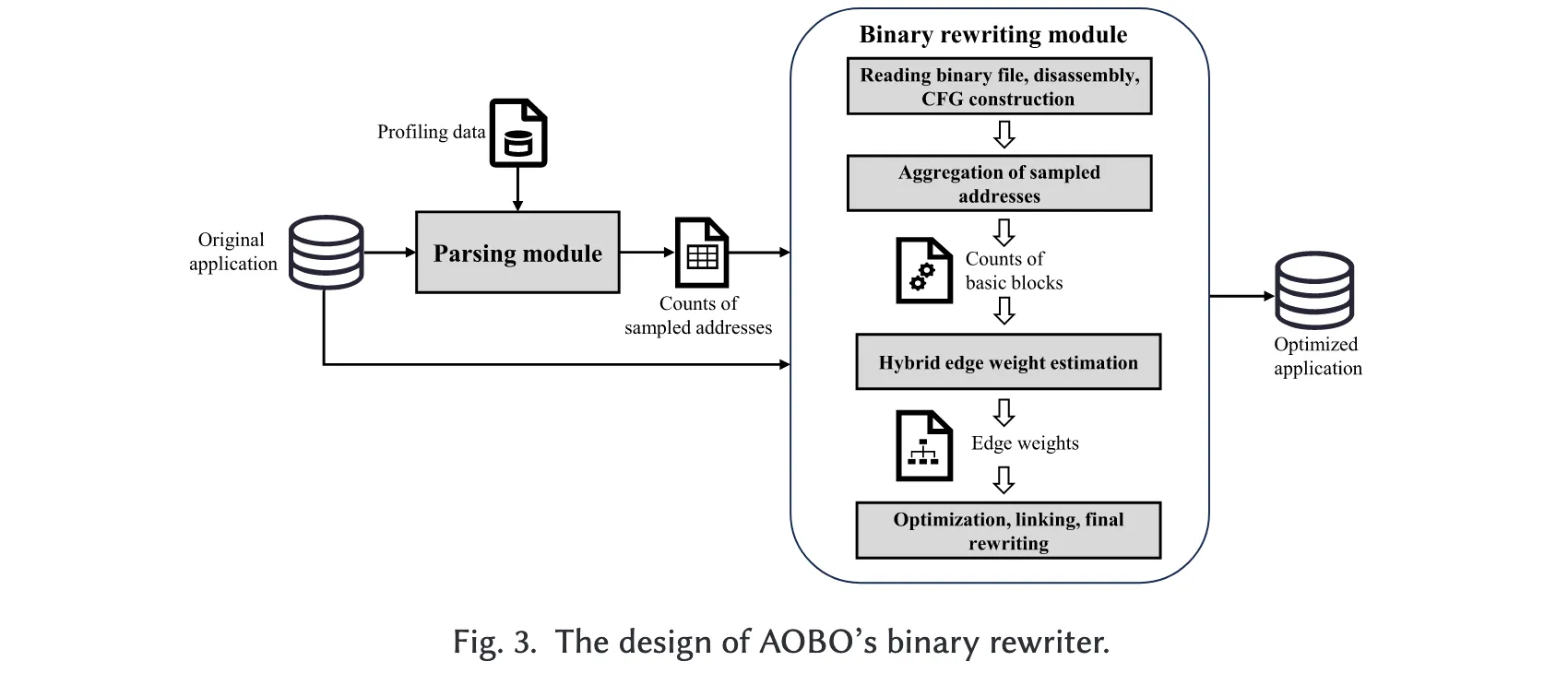
- 收集性能数据:首先利用 Linux perf 工具收集待优化应用的性能分析数据。
- 解析与转换:通过解析模块,将性能分析数据转换为采样地址计数,并将其传递给二进制重写模块。
- 输入数据:采样地址数据与原始应用一同输入到二进制重写模块。
- 符号与反汇编:二进制重写模块从 ELF 文件中提取符号表及函数描述信息,并使用 LLVM 内部反汇编器将函数的机器指令转换为 MCInst 对象。
- 构建控制流图(CFG):基于 MCInst 对象构建每个函数的控制流图。CFG 中的每个基本块包含一段连续的机器指令,基本块之间的关系通过分析分支指令确定,从而形成控制流图中的边。
- 执行频率映射:AOBO 聚合采样地址数据,推导基本块的执行频率,并将其映射到 CFG 的内存表示中。
- 边权重估计:利用混合估计算法,根据基本块的执行频率推断边权重。
- 代码布局优化:在估计的边权重指导下执行代码布局优化,以提升代码局部性。
- 生成优化二进制:最终将优化后的函数重新链接,生成优化版本的应用。
在我们的设计中,AOBO 仅优化目标应用的可执行文件,而不会修改或替换共享库。这一设计避免了用户管理多个版本库的负担,从而防止了代码膨胀与维护复杂性的问题。如果针对每个应用都要单独优化共享库,则需要生成独立版本,带来额外的管理和重新编译开销。
2.2 在线优化
AOBO 的在线优化框架工作流程如图 4 所示,其执行过程包含以下阶段:调用点提取、应用启动、性能数据收集、二进制重写以及在线代码替换。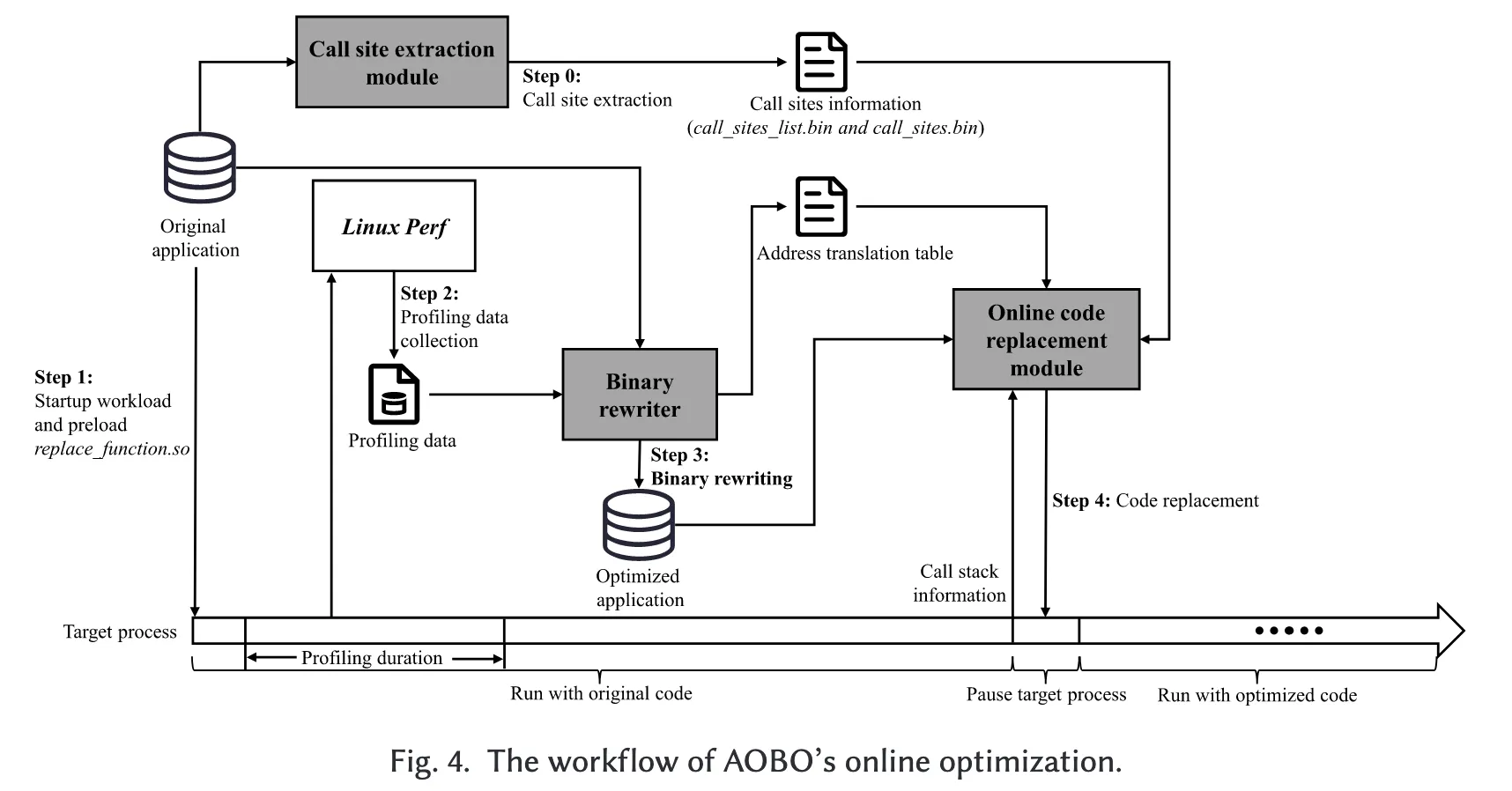
在准备执行在线代码替换之前,系统会预先提取并分析直接调用点信息,用于识别直接调用指令的地址及其目标函数,并将这些信息写入本地文件。对于每个应用,此操作仅需在首次执行在线代码替换之前执行一次(图 4 的步骤 0)。
在 AOBO 的执行初始阶段,AOBO 首先预加载用于代码替换的动态链接库(replace_function.so),并通过 execve 系统调用启动目标应用(图 4 的步骤 1)。随后,AOBO 使用 Linux perf 工具收集性能数据(图 4 的步骤 2)。接着,AOBO 生成优化后的二进制文件以及地址转换表,其中记录了原始函数与优化函数之间的映射关系(图 4 的步骤 3)。完成上述步骤后,AOBO 启动在线代码替换任务(图 4 的步骤 4)。
在线代码替换的过程主要包括 调用栈分析、调用指令重编码与代码插入 三个阶段。这些步骤确保了在线优化的可靠性,并将对用户体验的影响降到最低。
在代码替换开始时,AOBO 通过带有 PTRACE_ATTACH 选项的 ptrace 系统调用暂停目标进程,并保存其当前上下文。随后,AOBO 进行调用栈分析,以获取调用栈上的函数列表。对于每个线程,AOBO 遍历其栈帧,提取表示当前函数执行位置的地址。由于在预处理阶段已获取函数边界地址,AOBO 可以将提取的执行位置与函数边界进行关联,从而精确识别调用栈中的函数,并将函数入口地址作为其唯一标识。
如果调用栈中存在递归调用,则可能出现同一函数在函数列表中多次出现的情况。为避免重复重编码与插入操作,AOBO 会在进入下一步之前对函数列表进行去重。随后,AOBO 对这些函数中的调用指令进行重编码,使控制流重定向至优化后的函数。通过修改调用指令,AOBO 能够保证每个优化函数能够自入口至出口完整执行,从而避免原始版本与优化版本之间的上下文不一致。
为确保地址转换表中的地址与虚拟地址空间中的地址保持一致,应用需在编译时启用 no-pie 选项,以禁用地址空间布局随机化(ASLR)。借助存储在本地文件中的调用点信息,AOBO 能够识别当前调用栈中函数的直接调用指令地址及其目标函数地址。通过查询地址转换表,AOBO 获取相应的优化函数地址,并基于这些地址重编码新的直接调用指令,使其调用优化函数。最后,AOBO 将所有重编码后的直接调用指令、优化函数以及优化二进制文件的虚函数表(vtable)信息以机器码格式记录下来。这些信息将用于后续的实际代码插入阶段。
最后,AOBO 通过预加载的 replace_function.so 库执行实际的代码插入操作。AOBO 修改程序计数器(PC)寄存器,使执行流跳转至 replace_function.so 中定义的函数。在这些函数内部,AOBO 会读取先前记录的机器码及其对应的目标地址,并使用 mmap 函数在虚拟地址空间中为优化后的函数创建新的映射。随后,AOBO 将新的直接调用指令与虚函数表(vtable)的机器码复制到虚拟内存空间中对应的位置。完成这些操作后,PC 会被重新指向原始程序的运行位置,从而恢复应用的执行。接着,AOBO 恢复先前保存的进程上下文信息,并通过带有 PTRACE_DETACH 选项的 ptrace 系统调用恢复正常执行,使优化后的代码能够顺利运行。
综上所述,AOBO 采用在线代码替换机制,在程序运行过程中将原始应用替换为优化版本,从而实现无需重新启动应用即可执行优化后的二进制文件。特别地,AOBO 的关键组件专为 AArch64 ISA 设计,因此它成为首个运行于 AArch64 平台的在线二进制优化器。面向 AArch64 平台的核心组件设计,以及用于缩短代码替换暂停时间的优化策略,将在第 4 节中详细介绍。
需要指出的是,AOBO 目前仅支持对直接调用指令的更新,而尚未处理间接调用。这种不完全的代码替换会导致:当某个包含间接调用的函数位于被暂停的调用栈中时,该间接调用在执行时可能仍会跳转至未优化的目标函数。关于这一限制,我们将在第 7 节中进行更为详细的讨论。
概括一下流程:
- 应用先跑一段时间 → 收集性能数据。
- AOBO 根据数据生成优化版本。
- AOBO 暂停应用 → 借助
replace_function.so把调用指令重定向到优化函数。 - 应用恢复执行,此时就已经在跑优化后的代码了。
3 边缘权重估计
在原始 BOLT 中,提供了两种用于估计边缘权重的方案:基于热度的估计方案与迭代估计方案。然而,这些方法在边缘权重估计的精确性方面仍存在不足。因此,我们提出了一种新的混合边缘权重估计方案,该方案综合考虑了待估计边缘的前驱与后继基本块的执行频率,以提升精度。
3.1 原始 BOLT 中的边缘权重估计方案
图 5 展示了基于热度的估计方案与迭代估计方案的设计。在该图中,a、b、c、d、e 和 f 分别表示基本块 A、B、C、D、E 和 F 的执行频率。实线表示在当前估计轮次中已经确定权重的边缘,而虚线表示尚待估计权重的边缘。边上的标签则标注了当前轮次已知或估计得到的边缘权重。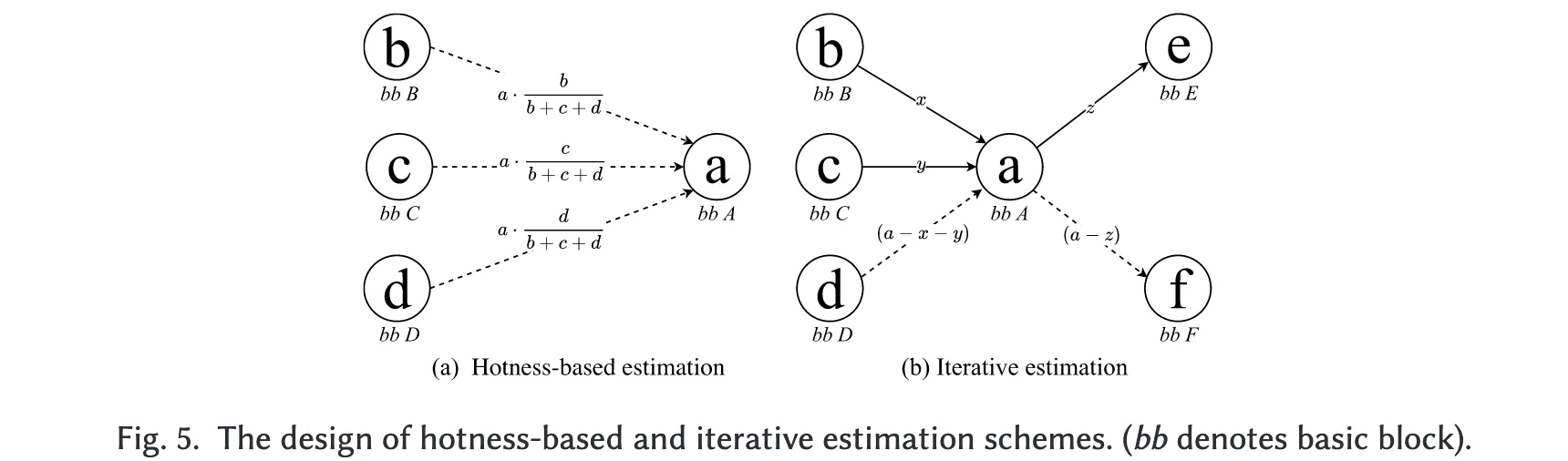
3.1.1 基于热度的估计方案
如图 5(a) 所示,该方案通过基本块的相对“热度”来推测边缘权重。其基本思想是:边缘权重与前驱基本块的执行频率成比例。此外,对于某一条 B→A 边,如果基本块 B 的执行频率为零,但该边是 A 的唯一入边,则该方案会将边 B→A 的权重直接设置为基本块 A 的执行频率。
这一方法在一定程度上减轻了因采样地址收集不完整带来的影响。然而,它无法准确应对前驱基本块存在多个后继跳转的情况。例如,在图 5(a) 中,基本块 B 可能除了跳转到 A 之外,还会跳转到一个或多个其他基本块。因此,仅依赖前驱基本块的执行频率,难以精确反映各条边的执行比例。
3.1.2 迭代估计方案
第二种方法是通过迭代推算边缘权重。如图 5(b) 所示,该方案的基本策略是:先以某个基本块(例如 A)的执行频率为基准,逐步减去其所有已知相邻边(具有相同起点或终点的边)的累计权重,得到尚未知边的估计值。该过程不断迭代,直到无法进一步调整为止。其步骤通常为:
- 先处理仅有单一入边或单一出边的基本块;
- 随后,再利用基本块的执行频率及已估计出的边缘权重,推算剩余边的权重。
在该方法中,边缘权重的估计结果高度依赖于两个因素:
- 基本块执行频率(由 Linux perf 的采样地址聚合得到);
- 前一轮迭代的估计结果。
然而,Linux perf 的基于事件的采样方法存在偏移 (skid) 与盲区 (blind spots) 等问题,导致基本块执行频率的统计存在误差,从而影响了边缘权重估计的精确性。随着迭代次数的增加,这种误差会进一步累积与放大。
此外,在某些情况下,若某基本块的多个相邻边权重均未知,迭代估计无法直接给出解答。此时,该方案会采用一种启发式策略:将该边权重设置为前驱与后继基本块执行频率的较小值的一半。这种做法提升了估计的覆盖率,但牺牲了估计的准确性。
偏移: 在 Linux perf 的事件采样中,硬件计数器在“触发事件”时发出采样信号,但由于流水线的执行,记录下来的指令地址可能并不是真正触发事件的那条指令,而是后面的一条或几条指令。
盲区:某些指令或执行路径无法被 perf 的事件采样正确覆盖,导致采样数据里缺少这部分信息。 原因可能包括:事件触发率过低,没能捕捉到;硬件性能监控单元(PMU)的限制;指令流水线优化,使某些分支或指令不会被标记。
3.2 混合估计方案
为了解决前述两种边缘估计方法固有的问题,我们在 AOBO 中提出了一种新的混合边缘估计方案,该方案结合了前驱热度估计与后继热度估计。其设计如图 6 所示。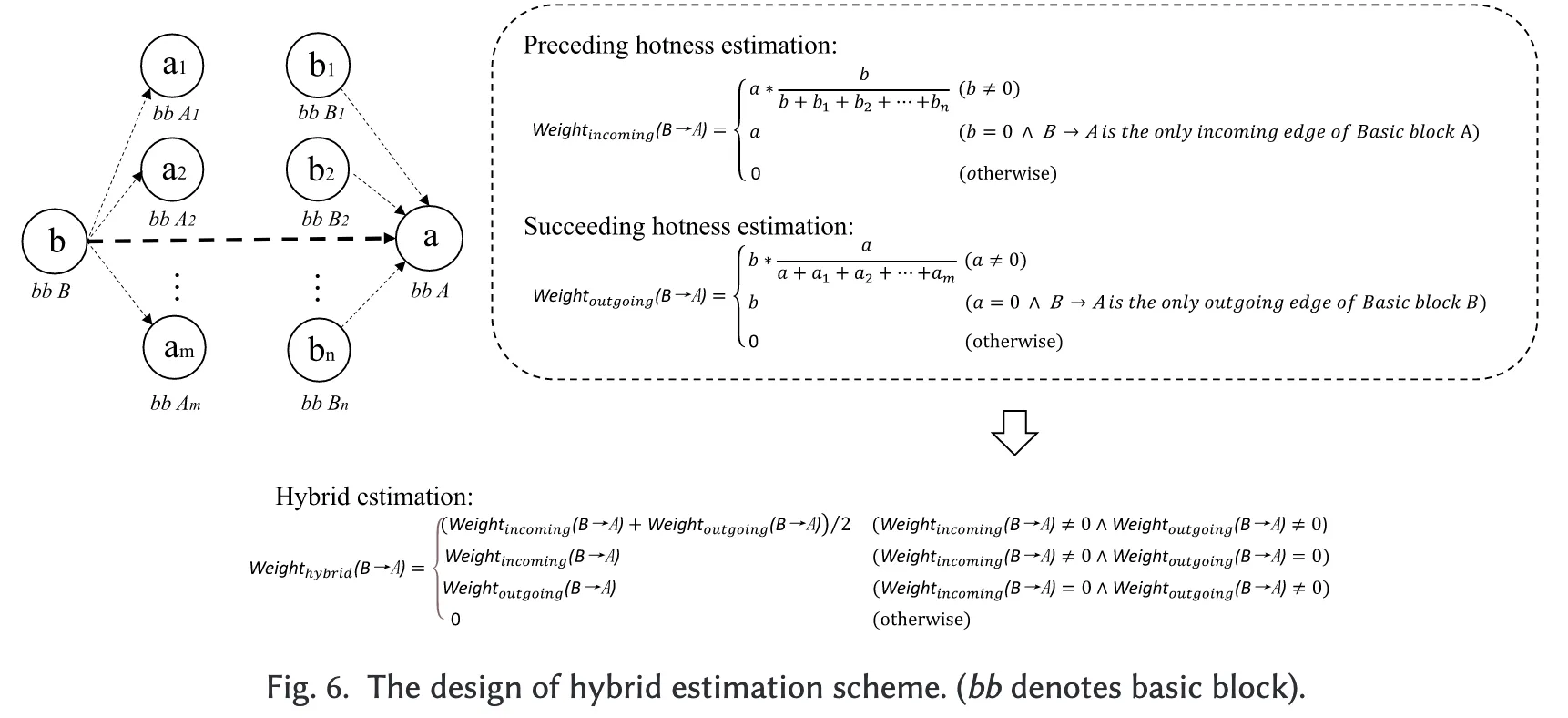
假设我们需要估计边缘 B → A 的权重。设基本块 A、B、A1, …, Am, B1, …, Bn 的执行频率分别为 a, b, a1, …, am, b1, …, bn。我们分别用 Weight_incoming(B → A)、Weight_outgoing(B → A) 与 Weight_hybrid(B → A) 来表示由前驱热度估计、后继热度估计以及混合估计得到的边缘权重。
如图 6 所示,边缘 B → A 的权重估计过程首先计算前驱热度估计与后继热度估计的结果。其中:
- 前驱热度估计与第 3.1.1 节所述的基于热度的估计方案相同,保证每条边的权重与其前驱基本块的执行频率成比例;
- 后继热度估计则确保每条边的权重与其尾部基本块的后继基本块的执行频率成比例。
我们根据图 6 中的公式分别计算 Weight_incoming(B → A) 与 Weight_outgoing(B → A),再由二者计算得到 Weight_hybrid(B → A)。从概念上讲,该方案同时涵盖了前驱热度估计与后继热度估计所能处理的情况,因此它能够估计比单一方法更多的边缘权重。此外,为了获得更为准确的估计结果,当 Weight_incoming(B → A) 与 Weight_outgoing(B → A) 均非零时,我们采用两者的平均值作为最终的边缘权重。这一策略有助于缓解由基本块执行频率不精确所导致的偏差,从而为整个控制流图提供更为均衡的边缘权重结果。
与原始的基于热度估计方法相比,本方案不仅能够获得更为精确的边缘估计结果,还能够覆盖更多的控制流图边缘。根据上述描述,前驱热度估计与后继热度估计的计算复杂度均为 O(|E|),其中 |E| 表示控制流图中的边数。由于混合方案仅通过算术平均结合了前驱与后继的估计结果,其计算复杂度仍保持在 O(|E|)。因此,该方案在保证精度的同时开销轻量,不会影响二进制重写的整体效率。
这一段讲了一大堆,其实就是“前驱热度算一次,后继热度算一次,最后取平均。”
4 在线优化的详细实现
作为首个在 AArch64 平台上实现在线二进制优化的优化器,AOBO 在多个关键组件上需要进行精细的 AArch64 特定实现,这些组件包括调用点提取、直接调用指令重编码以及进程上下文的保存与恢复。此外,AOBO 对在线代码替换机制进行了优化,以显著降低应用的暂停时间。
4.1 调用点提取
为了确保运行中程序的调用栈上原始函数能够正确地引用其对应的优化函数,AOBO 需要全面理解原始函数之间的调用关系。因此,在执行在线代码替换之前,必须对原始 ELF 文件中的直接函数调用进行静态提取和分析。
AOBO 首先从 ELF 文件中提取所有函数的符号名称,并利用 objdump 工具并行反汇编 ELF 文件中的函数。随后,AOBO 从反汇编结果中提取直接调用点的信息。
图 7 展示了 AOBO 中调用点提取的一个示例。如图所示,直接调用指令可以通过符号 “bl” 识别。==因此,AOBO 会扫描所有包含“bl”指令的反汇编行,并进一步解析这些行以提取函数地址、直接调用指令地址以及目标函数地址。==随后,AOBO 将这些地址记录在指定的本地文件中(call_sites_list.bin 与 call_sites.bin)。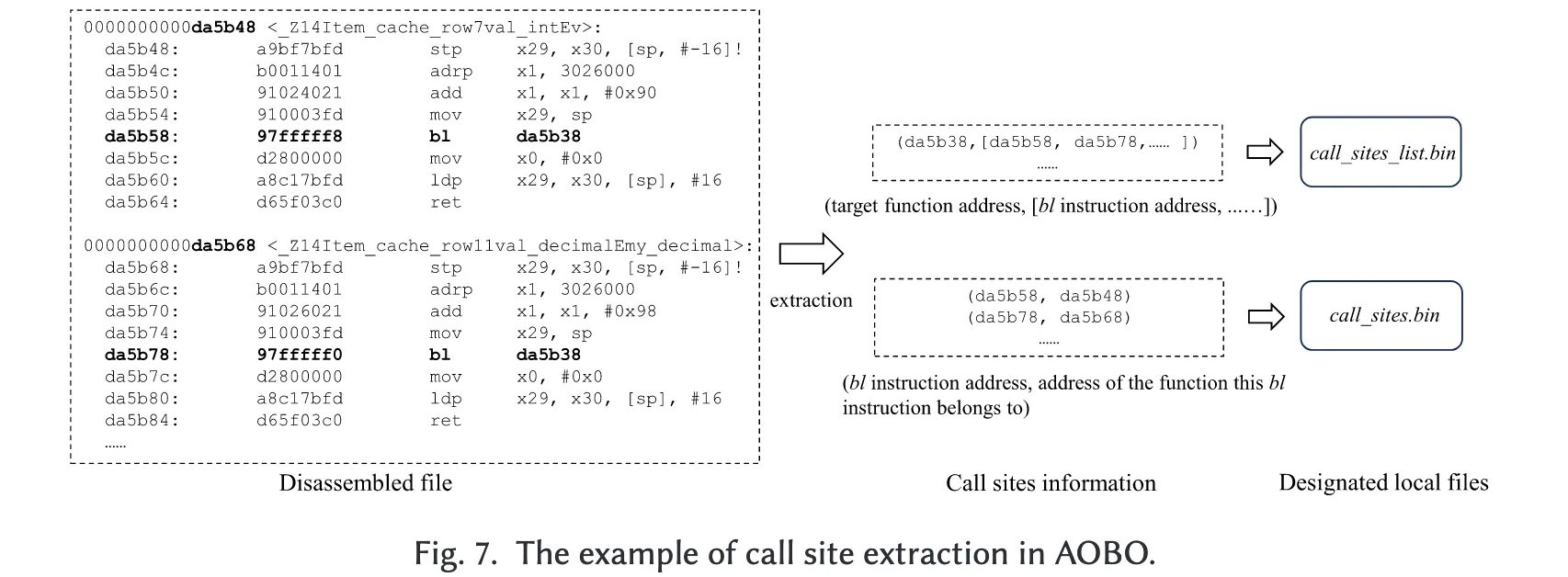
结合记录原始函数与优化函数映射关系的地址转换表,存储在 call_sites_list.bin 中的信息可以用来判断直接调用指令的目标函数是否已经被优化,并据此确定这些直接调用指令的新目标地址。而存储在 call_sites.bin 中的信息则可用于判断这些直接调用指令所属的函数是否当前出现在调用栈上。
因此,对于一个出现在 call_sites.bin 中的 bl 指令地址(对应某个直接函数调用),如果它的目标函数已被优化,且该 bl 指令所属的函数也出现在当前调用栈上,那么该 bl 指令就需要被重编码,以便跳转到优化后的函数。
说白了就是我们理解的最普通的方式拿跳转信息
4.2 直接调用指令的重编码
在 AOBO 中,直接调用指令的重编码遵循 AArch64 指令集架构 (ISA) 的特定编码规则。图 8 展示了采用 PC 相对寻址的直接调用指令的重编码过程。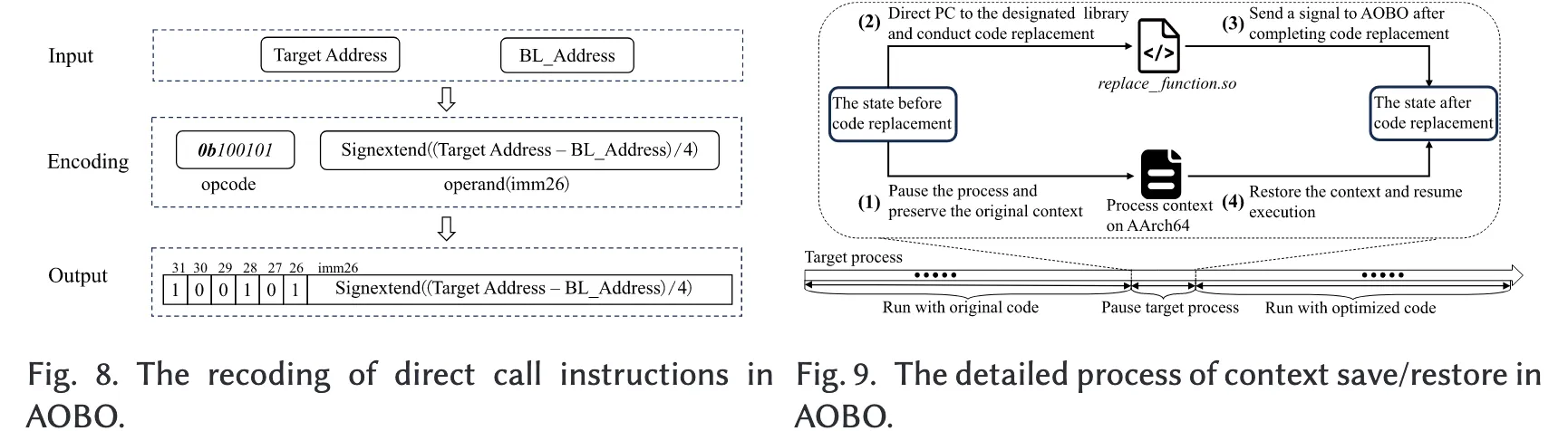
- 0b100101 是直接调用指令的固定操作码。
- 对于每一条直接调用指令,AOBO 计算其目标地址与该指令地址(即 BL_Address)之间的偏移量。
- 该偏移量经过除以 4 并带符号扩展后,作为立即数操作数存储。
随后,AOBO 将编码好的机器码记录到指定的本地文件中。具体存储过程如下:
- AOBO 将直接调用指令的机器码存入数组;
- 将该数组写入本地文件;
- 若处理器运行在小端模式 (little-endian),则将机器码的最高有效字节写入数组的最低存储地址;
- 若处理器运行在大端模式 (big-endian),则将机器码的最低有效字节写入数组的最低存储地址。
这种处理方式确保了 AOBO 在不同端序模式下均能正确存储并应用重编码后的直接调用指令。
4.3 进程上下文保存与恢复
为了顺利完成代码替换,AOBO 需要在替换阶段临时暂停目标进程,并在替换完成后恢复正常执行。如图 9 所示,AOBO 首先通过 ptrace 系统调用中断目标进程的执行,随后捕获并保存所有相关的进程上下文信息。接下来,AOBO 修改 PC 寄存器,将其指向预先加载的动态链接库 replace_function.so,该库具体执行代码替换操作。
当替换完成后,replace_function.so 会向 AOBO 发送信号,触发恢复操作。AOBO 随即恢复之前保存的进程上下文,之后程序即可继续运行,并执行优化后的代码。
在整个代码替换过程中,最关键的环节在于进程上下文的完整保存与恢复,特别是所有寄存器状态。在 AArch64 平台上,这意味着需要保存和恢复:
- 31 个通用寄存器
- 浮点寄存器
- SP 寄存器(堆栈指针)
- PC 寄存器(程序计数器)
- PSTATE 字段(处理器状态寄存器)
其中,PC 寄存器在这段过程中被多次修改,用于严格控制应用的执行流。
4.4 代码替换时间的缩减
虽然 AOBO 在在线优化时不需要终止原始应用并重新部署优化版本,但在线代码替换操作不可避免地会引入应用暂停,从而影响服务连续性,甚至带来用户体验上的波动。因此,我们的目标是进一步缩短替换所需的时间,以提升 AOBO 在生产环境中的实用性。以 MySQL 的 read_only 场景为例,对代码替换各阶段耗时进行分析,如表 1 所示。结果表明,主要开销集中在:
- 调用栈分析
- 调用指令重编码
- 代码插入
其中,代码插入阶段在 MySQL read_only 场景中约占总替换时间的 8.2%,这一部分几乎无法进一步压缩。因此,我们的优化重点放在调用栈分析与调用指令重编码两个阶段。在调用栈分析阶段,AOBO 会遍历每个线程的栈帧,以获取代表函数执行位置的地址。在 OCOLOS 的原始实现中,调用栈解析过程中会提取大量额外信息,例如函数在栈帧中的起始位置、函数名称等。这种额外解析为每一帧引入了不小的开销。为此,AOBO 引入了条件编译与宏控制机制:
- 在 调试版本中,保留这些额外的栈帧信息提取逻辑,以便调试与分析;
- 在 发布版本中,仅提取函数执行位置,从而简化调用栈解析流程。
这种优化有效地提升了替换效率,同时也弥补了 OCOLOS 原始实现中的效率缺陷。
调用指令重编码用于在代码替换阶段,依据第 4.1 节所述的调用点本地文件(call_sites_list.bin 与 call_sites.bin),对当前调用栈上函数所属的直接调用指令进行重编码。整个调用指令重编码过程可分为两个部分:本地文件加载与实际重编码。
我们进一步发现,本地文件加载约占调用指令重编码总执行时间的 70%。为缩短调用指令重编码所需时间,AOBO 在代码替换前将本地文件预加载到内存中,并在代码替换完成前保持内存常驻以供复用。此外,我们对执行实际指令重编码的函数进行了内联化处理,以减少通过堆栈传参所带来的函数调用开销。
在完成上述两项面向 AOBO 代码结构的优化后,MySQL 的 read_only 场景下代码替换时间由 1,582.9 毫秒降至 461.7 毫秒。第 5.4.3 节的综合实验结果进一步表明,这些优化使得 AOBO 在 MySQL 与 MongoDB 上的代码替换时间平均分别缩短了 71.12% 与 71.28%。相较于原始 OCOLOS 框架,AOBO 实现了亚秒级别的切换,能够在极短时间内完成从原始代码到优化代码的切换。
截至此,论文的篇幅到了一半
5 评估
我们从以下几个方面开展实验评估:AOBO 边缘权重估计的准确性与覆盖率、AOBO 二进制重写带来的性能提升、AOBO 在线优化的性能增益与运行时开销,以及与最新技术的对比。为了全面评估我们提出的混合估计方案,我们选择了 CINT2017 基准测试集以及若干实际工作负载(MySQL、MongoDB 和 GCC),并将我们的混合估计方案与 BOLT 原有的两种估计方案进行对比,考察其在准确性与覆盖率方面的表现。此外,我们还比较了在不同估计方案提供的边缘权重信息指导下,优化后的工作负载在性能提升方面的差异。随后,我们选取 MySQL 与 MongoDB 作为目标工作负载,深入评估 AOBO 在线优化的性能提升效果及运行时开销。最后,我们将我们的混合估计方法与当前最先进的 profile inference 技术 profi 进行了专门对比。为了减轻因采样方式获取的性能分析数据波动,以及因优化后二进制文件的性能变化带来的实验偏差,我们对每个实验均 重复执行五次,并采用 平均结果 作为最终评估数据。
5.1 实验设置
我们在一台 双路 Ampere Altra Max 服务器 上运行实验,每个插槽具有 128 个核心。每个核心配置有 64 KB L1 指令缓存、64 KB L1 数据缓存、1024 KB L2 缓存,主频最高可达 3,000 MHz。此外,服务器配备 16 MB 系统级缓存(SLC) 与 1,024 GB 内存。操作系统为 Ubuntu 20.04.2 LTS。
实际工作负载的基本配置信息如表 2 所示。我们使用各软件包自带的 默认编译脚本 编译工作负载,以确保比较的公平性与结果的现实意义。MySQL 的默认优化等级为 -O3,而 MongoDB 与 GCC 的默认优化等级均为 -O2。通过遵循这些默认设置,我们保证实验能够真实反映实际使用场景,而不会因自定义配置引入潜在偏差。
在 边缘权重估计 与 二进制重写 实验中,为尽可能确保输入分析数据的可靠性,我们将 MySQL 与 MongoDB 的性能分析数据采集时间设置为 120 秒,而对 GCC 则在整个运行期间收集性能分析数据。根据客户的反馈,生产环境中典型的 MySQL 与 MongoDB 虚拟机实例一般配置为 16 核 CPU 与 64 GB 内存。因此,我们在评估时有意将系统配置约束在客户推荐的核心数与内存规模下。
为提升执行效率,我们在运行 GCC 工作负载时采用 64 线程与 64 个 CPU 核心。此外,我们使用 -O3 编译选项 编译 CINT2017,并在实验中使用其参考输入数据。
表 2. 实际工作负载的基本信息
| Workload | Version | Test tool | Metric | Profiling time | Optimization level | Function number | .text section (MB) |
|---|---|---|---|---|---|---|---|
| MySQL | 8.0.32 | Sysbench 1.0.18 | Transactions per second (tps) | 120 秒 | -O3 | 69,149 | 53.74 |
| MongoDB | 5.0.13 | YCSB 0.17.0 | Operations per second (opt/sec) | 120 秒 | -O2 | 93,431 | 76.95 |
| GCC | 10.3.0 | LLVM 16.0.0 | Wall time | 整个执行过程 | -O2 | 43,620 | 26.60 |
后续评估策略
- 边权估计的准确性
- 对SPECINT的性能提升、L1-icache-load-miss、iTLB-load-miss、branch-miss
- 对在线真实应用 MySQL 的性能提升,profile 时间占比对比
- 代码替换的时间
- 和另一个 SOTA Profi 的对比,对比性能提升和边权估计
6 相关工作
本文提出了 AOBO —— 一个面向 AArch64 的高效且实用的二进制优化器。其主要贡献包括提出一种 混合边缘权重估计方案,以更准确地推断边缘权重,从而指导 AOBO 的二进制重写器进行更有效的代码布局优化。同时,AOBO 还支持从正在运行的原始应用程序快速切换到优化后的版本。我们的相关工作归纳为四个方向:边缘权重估计、代码布局优化、运行时程序优化以及编译器层面的代码重写研究。
6.1 边缘权重估计
为了以较低开销并在不依赖特定硬件的情况下获得边缘权重信息,一些研究使用 边缘权重估计方法,通过基本块的执行频率来计算边缘权重。
例如,SamplePGO、BOLT 与 AutoFDO 都采用 迭代方法 来估计控制流图(CFG)中的边缘权重,其中 BOLT 还支持基于基本块 “热度” 的权重猜测。然而,正如第 3.1 节所述,这两类方法都存在固有缺陷,导致估计结果不够准确。
另一类常见方法是基于 最小费用流(MCF) 的算法。Levin 等人 将边缘权重估计问题转化为 MCF 问题,以在流网络中创建一个合法循环流,并最小化加权流量成本。Chen 等人 提出了一种基于硬件事件采样的性能分析信息收集框架,该框架通过多事件采样、MCF 算法与基于 LBR 的分支分析,提高了采样精度。He 等人 提出了 profi 算法,这是一种新型的性能分析推断方法,旨在解决基于采样的性能分析在 PGO(Profile-Guided Optimization) 中精度下降的问题。与其他基于 MCF 的算法相比,profi 能更好地保持观测到的执行次数比例,同时确保 CFG 的连通性。此外,profi 的执行效率也得到了进一步提升,其典型复杂度为 o(|V|²),理论复杂度为 O(|V|² · |E|²),优于其他同类方法。
相比之下,正如第 3.2 节所述,我们提出的 混合估计方案 的复杂度仅为 O(|E|),显著低于 profi 算法。其低复杂度确保了在 AOBO 优化过程中不会引入显著的额外开销。此外,我们还进行了实验,将 profi 算法与我们的混合估计方法在执行效率与性能提升方面进行了对比。结果表明,我们的混合估计方法在这两个方面均优于 profi。
6.2 代码布局优化
代码布局优化能够为大规模应用带来显著的性能提升。Ispike 是一款面向 Intel Itanium 架构的二进制优化器。它基于 Itanium 架构的特定硬件特性,在较低开销的条件下实现了显著的性能收益。Codemason 则采用二进制插桩的方法来收集性能分析数据,并据此对二进制文件进行代码布局优化。
目前在工业界仍被广泛使用的二进制优化系统包括 BOLT 与 Propeller。BOLT 是一种基于反汇编的离线二进制优化系统。它依托于 LLVM 基础设施,对目标二进制文件进行反汇编,利用性能分析数据重建控制流图(CFG),并最终通过重新链接编译后的目标文件生成优化后的二进制文件。Propeller 则是一种面向大规模数据中心工作负载的基于重链接的优化器,它引入了基本块分段(basic block sections)的概念,并将其作为链接器的基本单元。在完成编译和链接优化后,Propeller 根据性能分析数据重新链接这些基本块分段。由于其 实用性与高效性,BOLT 与 Propeller 等离线二进制优化器在工业界得到广泛应用。AOBO 的二进制重写器正是基于 BOLT 实现,并针对 AArch64 架构进行了定制化改造,同时融入了增强的边缘权重估计方法。与传统的离线二进制优化器相比,AOBO 进一步引入了 在线代码替换模块,从而实现了在程序执行期间对 AArch64 应用的代码布局进行优化的能力。
对于静态编译器(如 C/C++ 编译器),PGO(Profile-Guided Optimization) 是一种有效的代码布局优化技术。PGO 主要在 中间表示(IR)层进行代码布局优化。当编译器生成 IR 后,PGO 会利用性能分析数据对 IR 进行标注,然后在编译过程中使用这些数据优化代码布局。PGO 的主要挑战在于:如何在 PGO 优化阶段将 运行时性能数据 与 IR 表示 建立准确关联。由于性能数据通常是从二进制文件收集的,在应用到编译链早期的 IR 时可能出现误差;而编译器在后续阶段对代码的进一步转换,也会导致性能数据与 IR 代码布局之间的不匹配,从而削弱优化效果。
为了解决这一问题,CSSPGO 提出了一种伪插桩方法(pseudo-instrumentation),能够在 IR 与二进制指令之间建立映射关系。然而,该方法可能增加生成二进制文件的代码体积,并带来额外的运行时开销。此外,在大多数 AArch64 服务器上实现 PGO 还必须克服缺乏硬件边缘分析支持所带来的困难。
对于非直接以本地机器码形式运行的语言,代码布局优化同样适用。例如,运行在 Java 虚拟机上的 Java 字节码,借助 JIT 编译器可以实现动态代码布局优化。类似地,动态语言如 PHP、Hack 与 JavaScript 也能从虚拟机层面的代码布局优化中获益,例如 HipHop Virtual Machine 与 JavaScript Virtual Machine 都具备相应的优化能力。
6.3 运行时程序优化
动态二进制插桩系统被设计用于收集程序运行时信息,并采用自适应的动态优化机制来提升被插桩应用的性能。然而,这类二进制插桩通常会引入较大的性能开销,往往超过运行时优化所带来的收益。Dynimize 是一种用户态程序,它基于运行时收集的性能信息快速优化目标进程的内存中机器码,从而加速部分数据库工作负载。但需要注意的是,Dynimize 属于商业产品,且仅支持 X86-64 平台。JACO 在 Java 应用层面展示了类似的在线优化机制:它在字节码级别构建加权调用图,以收集控制流信息,并基于性能分析数据生成优化后的函数顺序;随后将优化代码放入代码缓存,并修改相关调用点以跳转至优化代码。OCOLOS 是首个面向 X86-64 平台的开源在线代码布局优化器,适用于本地二进制文件。OCOLOS 通过在线代码替换机制,使得经 BOLT 优化的应用能够在无需重启的情况下直接执行。相比之下,AOBO 则是 首个面向 AArch64 平台的在线二进制优化器,并且支持快速切换,从运行原始应用无缝切换至优化后的版本。
6.4 编译器层面的代码重写
近年来,一些研究工作也开始利用编译器技术进行代码重写。He 等人提出了一种三阶段框架用于无人机感知与导航,结合 LLVM IR 与数据依赖图分析,并引入负载均衡算法以减少数据迁移和能耗。Xiao 等人提出了一个端到端的可编程图表示学习框架 PGL,通过利用 LLVM IR 改进程序执行效率,解决了在异构平台上将代码段映射至特定硬件设备的难题。Hataba 等人则针对自动驾驶软件提出了一种混淆系统,用于防御时序侧信道攻击,该系统通过 LLVM 生成多个混淆版本的代码来增强安全性。SODA-OPT 基于 MLIR 进行高层优化,并为 FPGA 和 ASIC 等特定硬件平台生成代码。Moses 等人提出了一种方法,将 GPU 代码转换为 CPU 代码,同时保留并行结构,以便在 CPU 上高效执行。
上述工作主要基于 LLVM IR 或 MLIR 的 离线代码重写。相比之下,AOBO 实现了在线二进制优化,能够在应用运行过程中动态分析其当前运行时行为,并基于收集的性能分析数据优化代码布局。此外,AOBO 的在线优化无需应用重新部署,从而 显著提升了服务连续性。
7 局限性
缺乏间接调用的处理能力:
目前,AOBO 在函数调用点的在线修改仅限于直接调用,尚未扩展至间接调用指令。由于间接调用的目标函数在静态分析阶段是未知的,无法从间接函数调用指令的操作数中解码,因此 AOBO 的调用点提取模块无法在二进制文件中静态提取目标地址。间接调用的目标地址可能会在执行过程中动态变化,即便在性能分析数据中仅识别出一个目标函数,将间接调用替换为直接调用仍可能影响程序的稳定性。这一限制导致驻留在内存地址空间中的代码无法被完全替换,从而可能带来一定的性能损失。值得注意的是,该限制仅在 AOBO 的 在线优化阶段 出现,并且仅影响应用暂停时调用栈上的函数。
在线代码替换导致的服务暂停:
AOBO 在执行在线代码替换时需要一个短暂的服务暂停,这会导致目标应用在一段时间内停止提供服务。尽管我们已经尽力缩短这一暂停时间,但它仍然是 AOBO 在线优化过程中固有的问题。该暂停可能对服务连续性产生轻微影响,并在一定程度上影响用户体验。
对额外编译选项的依赖:
AOBO 能够在应用运行过程中无需源代码即可执行在线二进制优化。然而,它要求输入的二进制文件必须使用特定的编译选项构建,包括:
-Wl,--emit-relocs:该选项使链接器在链接阶段保留重定位信息,使得重写器能够在在线优化中准确地将原始函数地址映射到其优化后的版本。-no-pie:该选项确保二进制文件加载到固定内存地址,从而使 AOBO 能够在代码替换后准确更新直接调用并平滑执行优化后的函数。-fno-jump-tables:跳转表依赖编译时常量来确定跳转目标,而 AOBO 无法在在线代码替换过程中更新这些常量。因此,需要使用该选项禁止生成跳转表。
这些编译选项目前是 AOBO 正确执行在线优化所必需的,我们计划在未来探索消除这一依赖的可能性。需要指出的是,-no-pie 选项增加了控制流劫持的风险。在必须降低这一风险的场景下,可以通过 轻量级虚拟化技术 部署 AOBO。这类虚拟化方案攻击面小,能够在禁用地址空间布局随机化(ASLR)的情况下缓解潜在的安全问题。
有限的语言支持:
AOBO 的在线替换机制通过修改内存地址空间中直接调用指令的机器码实现。因此,AOBO 目前仅支持 Fortran 和 C/C++ 等直接编译为本机机器码的语言。对于编译为平台无关代码并在 Java 虚拟机上运行的 Java 程序,AOBO 并不适用。同样,AOBO 也无法对部分动态语言(如 PHP 和 JavaScript)编写的程序进行在线优化。
8 结论与未来工作
在本文中,我们提出了 AOBO ——一种面向 AArch64 平台的快速切换型在线二进制优化器,用于加速大规模应用。凭借新提出的 混合边缘权重估计算法,AOBO 能够在 AArch64 平台上生成更优的二进制程序。基于在线代码替换机制,AOBO 能在应用执行过程中直接进行代码布局优化。此外,我们还最大限度地缩短了在线代码替换带来的程序暂停时间,实现了亚秒级切换至优化后的代码。
AOBO 构建在 BOLT 框架 之上,继承了这一被工业界广泛采用框架的健壮性,确保能够有效处理多种真实应用工作负载。通过在编译时引入 -no-pie 选项,AOBO 可以确保目标进程的内存空间固定,从而在在线代码替换过程中实现安全的代码插入。本文提出的混合边缘权重估计方法是一种简洁而有效的方案,不仅带来了个位数百分比的精度提升,还改进了在估计信息指导下生成的优化代码的性能。这一成果启发我们在未来探索更高效的估计方法,以进一步提升优化效果。
此外,随着支持 ETM (Embedded Trace Macrocell) 的 ARM 服务器在商用市场中逐渐普及,我们计划探索 ETM 是否能帮助采集更精确的分支信息。同时,随着未来 ARM 架构中更多硬件辅助的分析功能(如 BRBE)逐渐可用,我们将研究如何利用这些硬件能力进一步提升 AOBO 的优化质量。本文的工作不仅展示了 AOBO 在 AArch64 平台上的可行性与有效性,还为未来更精细的硬件支持下的在线二进制优化研究提供了方向。